
爬虫-xpath解析
一、xpath解析原理:
1、实例化一个etree的对象,且需要讲被解析的页面源码数据加载到该对象中
2、调用etree对象中的xpath方法,结合着xpath表达式实现标签的定位和内容的获取
第一步:安装模块
pip install lxml
第二步使用流程
from lxml import etree 如何实例化一个对象: 1、将本地的html文档中的源代码数据加载到etree对象中 etree.parse(filePath) 2、可以讲互联网上的数据源码加载到该对象中 etree.HTML('page_text') 3、xpath('xpath表达式')
实例说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | from lxml import etree<html lang="en"> <head> <meta charset="UTF-8" /> <title>Title</title> </head> <body> <div class="链接"> <ul> <li><a href="http://www.baidu.com">百度</a></li> <li><a href="http://www.google.com">谷歌</a></li> <li><a href="http://www.sogou.com">搜狗</a></li> </ul> <ol> <li><a href="feiji">飞机</a></li> <li><a href="dapao">大炮</a></li> <li><a href="huoche">火车</a></li> </ol> </div> <div class="job">李嘉诚</div> <div class="common">胡辣汤</div> </body></html>"""tree = etree.parse("b.html")result = tree.xpath('/html') #[<Element html at 0x13193379180>]result = tree.xpath('//div[@class ="链接"]//a/text()') #['百度', '谷歌', '搜狗', '飞机', '大炮', '火车']<class 'list'>result = tree.xpath('/html/body/div[1]/ul/li[1]/a/text()') # xpath的顺序是从1开始数的, []表示索引 #['百度']result = tree.xpath('/html/body/div/ol/li/a[@href="dapao"]/text()') # [@xxx=xxx] 属性的筛选 ['大炮']ol_li_list = tree.xpath("/html/body/div[1]/ol/li")#得到ol下的所有li标签for li in ol_li_list: #遍历循环 # 从每一个li中提取到文字信息 text = li.xpath("./a/text()") # 在li中继续去寻找. 相对查找 href = li.xpath("./a/@href") # 拿到属性值: @属性 print(text , href) |
实例一、爬取往网站为https://xinzhuobu.com/?cat=2&paged=1的图片
网页分析:
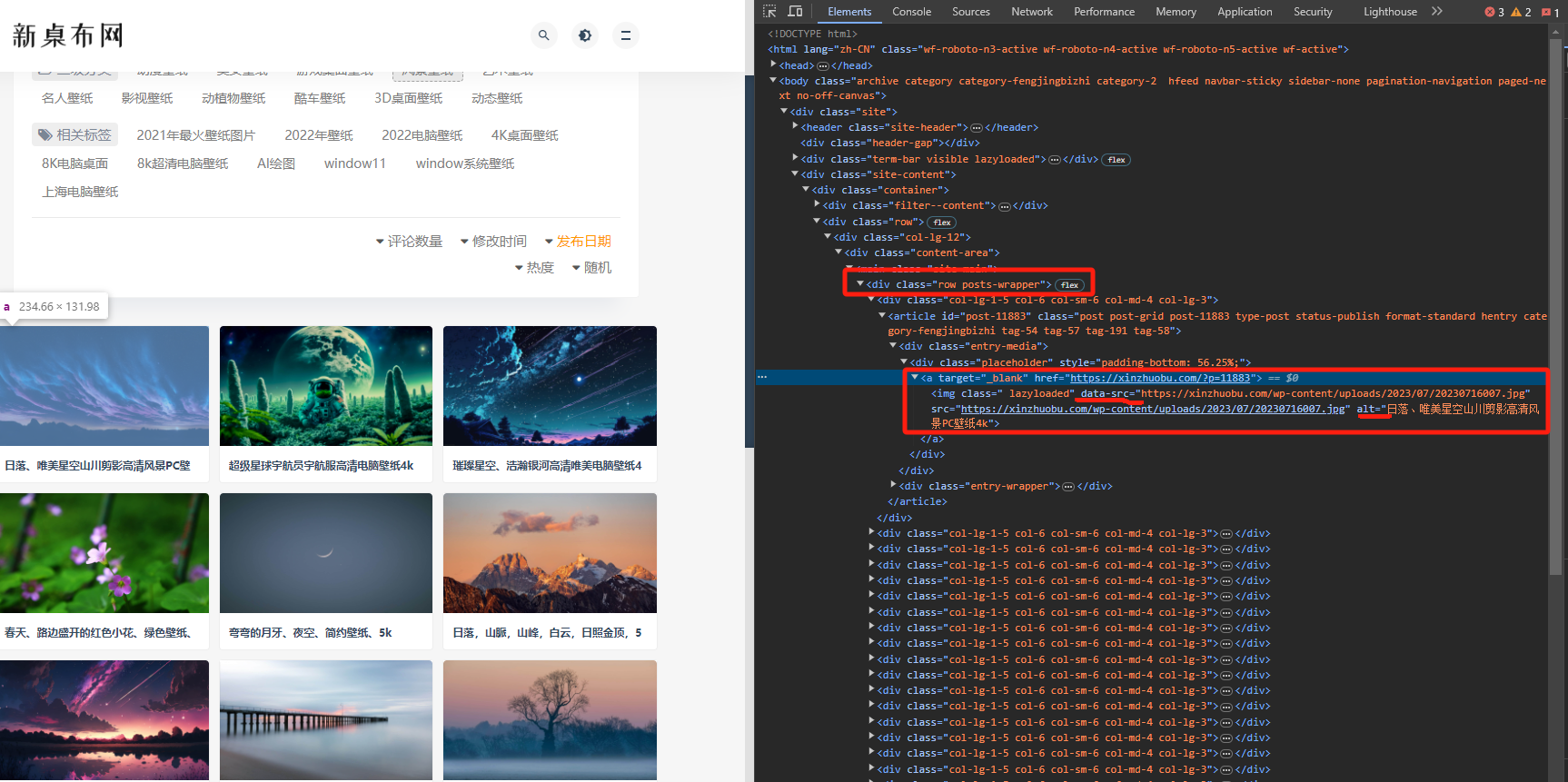
利用xpath复制得到在class = row posts-wrapper 下面的所有div的标签:复制xpath路径可以得到:
1 | /html/body/div/div[3]/div/div[2]/div/div/main/div #又因为main下面两个div,这里选择第一个,写法如下<br>/html/body/div/div[3]/div/div[2]/div/div/main/div[1]/div |
运行后可以得到很多div标签,然后在当前的div下面在获取得到data-src超链接和alt的文本就可以保存到本地中
for div in divs: pic_name = div.xpath('./article/div[1]/div/a/img/@alt')[0] pic_src = div.xpath('./article/div[1]/div/a/img/@data-src')[0]
完整代码如下:

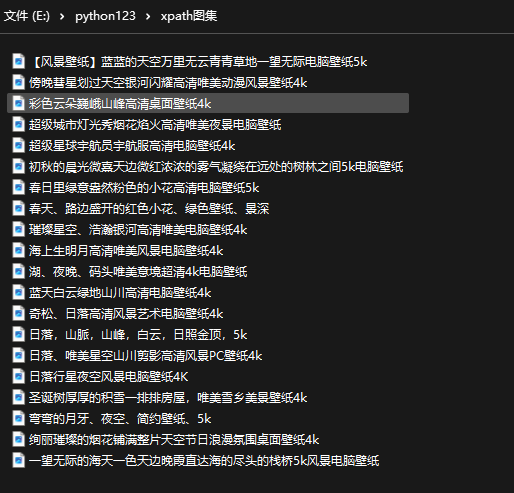
#准备一个url地址 url = "https://xinzhuobu.com/?cat=2" #UA伪装 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.30"} resp = requests.get(url=url,headers = headers) #实例化一个etree对象,把html数据源码发到etree对象中 html = etree.HTML(resp.text) divs = html.xpath('/html/body/div/div[3]/div/div[2]/div/div/main/div[1]/div') for div in divs: pic_name = div.xpath('./article/div[1]/div/a/img/@alt')[0] pic_src = div.xpath('./article/div[1]/div/a/img/@data-src')[0] print(f"{pic_name},{pic_src}") # f-string img_data = requests.get(url=pic_src,headers=headers).content #保存数据 with open( image + '/' + pic_name + '.jpg','wb')as fp: fp.write(img_data) print(pic_name + '下载完成!!') print('over')
运行得到结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现