gitlab--缓存 cache
缓存 cache 介绍
使用 cache 指定要在作业之间缓存的文件和目录列表。您只能使用本地工作副本中的路径。缓存在流水线和作业之间共享。缓存在产物之前恢复。
cache:paths
使用 cache:paths 关键字来选择要缓存的文件或目录,路径是相对于项目目录,不能直接链接到项目目录之外
例如
rspec:
script:
- echo "This job uses a cache."
cache:
key: binaries-cache
paths: # 缓存 binaries 中以 .apk 结尾的所有文件 和项目下 .config 文件结尾的文件:
- binaries/*.apk
- .config当在全局定义了 cache:paths 会被 job 中的覆盖。以下实例将缓存 target 目录。
cache:
paths:
- my/files
build:
script: echo "hello"
cache:
key: build
paths:
- target/cache:key 缓存标记
由于缓存是在 job 之间共享的,如果不同的 job 使用不同的路径就出现了缓存覆盖的问题。如何让不同的 job 缓存不同的 cache 呢?设置不同的cache:key
使用 cache:key 关键字为每个缓存提供唯一的标识键。使用相同的缓存键的所有作业都使用相同的缓存,包括在不同的流水线中。如果未设置,则默认为 default,所有带有 cache: 关键字但没有 cache:key 的作业将共享 default 缓存。必须与 cache:path 一起使用,否则不会缓存任何内容
例如
cache-job:
script:
- echo "This job uses a cache."
cache:
key: binaries-cache-$CI_COMMIT_REF_SLUG # 设置了 key
paths:
- binaries/缓存在作业之间共享,因此如果您为不同的作业使用不同的路径,您还应该设置不同的 cache:key。 否则缓存内容可能会被覆盖
cache:key:files
使用 cache:key:files 关键字在一两个特定文件更改时生成新密钥。cache:key:files 可让你重用一些缓存,并减少重建他们的频率,从而加快后续流水线运行的速度
文件发生变化自动重新生成缓存( files 最多指定两个文件),提交的时候检查指定的文件
例如
cache-job:
script:
- echo "This job uses a cache."
cache:
key:
files:
- Gemfile.lock
- package.json
paths:
- vendor/ruby
- node_modules此示例为 Ruby 和 Node.js 依赖项创建缓存。缓存绑定到当前版本的 Gemfile.lock 和 package.json 文件。当这些文件之一发生变化时,将计算一个新的缓存键并创建一个新的缓存。任何使用相同的 Gemfile.lock 和 package.json 以及 cache:key:files 的未来作业都会使用新的缓存,而不是重建依赖项。
cache:when
使用 cache:when 定义何时根据作业的状态保存缓存
可能的输入:
on_success(默认):仅在作业成功时保存缓存。on_failure:仅在作业失败时保存缓存。always:始终保存缓存
例如
rspec:
script: rspec
cache:
paths:
- rspec/
when: 'always'无论作业是失败还是成功,此示例都会存储缓存
cache:policy
要更改缓存的上传和下载行为,请使用 cache:policy 关键字。 默认情况下,作业在作业开始时下载缓存,并在作业结束时将更改上传到缓存。 这是 pull-push 策略(默认)。
要将作业设置为仅在作业开始时下载缓存,但在作业完成时从不上传更改,请使用 cache:policy:pull。
要将作业设置为仅在作业完成时上传缓存,但在作业开始时从不下载缓存,请使用 cache:policy:push。
当您有许多使用相同缓存并行执行的作业时,请使用 pull 策略。 此策略可加快作业执行速度并减少缓存服务器上的负载。 您可以使用带有 push 策略的作业来构建缓存。
必须与 cache: path 一起使用,否则不会缓存任何内容。
可能的输入:
pullpushpull-push(默认)
例子
prepare-dependencies-job:
stage: build
cache:
key: gems
paths:
- vendor/bundle
policy: push # 仅在作业完成时上传缓存,作业开始前从不下载缓存
script:
- echo "This job only downloads dependencies and builds the cache."
- echo "Downloading dependencies..."
faster-test-job:
stage: test
cache:
key: gems
paths:
- vendor/bundle
policy: pull # 仅在作业开始时下载缓存,但在作业完成时从不上传缓存
script:
- echo "This job script uses the cache, but does not update it."
- echo "Running tests..."创建全局缓存
在 .gitlab-ci.yml 里写入下面内容
cache: # 全局缓存
paths:
- app/ # 缓存项目 app 下的所有文件
stages:
- build
- test
- deploy
build:
stage: build
tags:
- build
before_script:
- ls
- ls app
script:
- ls
- id
- echo 'test123' >> app/a.txt # 创建了个文件,模拟编译产生的文件
- echo 'test456' >> app/b.txt # 创建了个文件,模拟编译产生的文件
- ls
test:
stage: test
tags:
- build
before_script:
- ls
- ls app
script:
- echo "run test"
- echo 'test' >> app/c.txt
- ls app # 在查看 app 下的内容
retry:
max: 2
when:
- script_failure
deploy:
stage: deploy
tags:
- build
before_script:
- ls
- ls app
script:
- echo "run deploy"
- ls app # 在查看 app 下的内容
retry:
max: 2
when:
- script_failureapp 目录下只有两个文件 deploy.yaml 和 svc.yaml
等待流水线运行完成之后,查看运行的日志。先来查看 build 里的文件


从 build 阶段可以看到,创建缓存到本地成功了
在来看 test 阶段


在来查看 deploy 的日志


缓存和代码仓库的地址
当我们在次运行当前流水线,查看结果,我们只需要查看 build 阶段就可以了
如果我们不想要缓存的话,可以删掉缓存,缓存在 runner 里面
先来看下代码仓库的地址,在日志里我们可以看到将代码下载到哪里了
Reinitialized existing Git repository in /home/gitlab-runner/builds/1xVj7c2X/0/root/lrunweb/.git/ # 进入到 runner 里面
上面是代码仓库的地址,接下来看下缓存的地址,因为缓存我们没有加 key,所以使用的是默认的 default-protected 下的缓存
在 runner 里的 /home/gitlab-runner 下有个 cache 目录,里面就是我们的缓存,我的这个项目使用的缓存是在如下目录里面
/home/gitlab-runner/cache/root/lrunweb/default-protected 接下来我们删除缓存之后在运行一次
接下来我们删除缓存之后在运行一次
root@c5249d1c22f7:/home/gitlab-runner/cache/root/lrunweb/default-protected# rm cache.zip # 删除缓存删除后在运行流水线,只看 build 阶段


创建 job 的缓存和缓存策略
上面我们使用的是全局的缓存,我们也可以给某个 job 设置缓存,也可以设置缓存的策略 push 或者 pull
stages:
- build1
- build2
- build3
- test1
- test2
- deploy
build1:
stage: build1
tags:
- build
before_script:
- ls
- ls app
cache:
key: build1 # 为缓存提供唯一的标识键
paths:
- app/a.txt # 将 app 下的 a.txt 文件创建一个缓存
- app/b.txt # 将 app 下的 b.txt 文件创建一个缓存
script:
- ls
- id
- echo 'test123' >> app/a.txt # 创建了个文件,模拟编译产生的文件
- echo 'test456' >> app/b.txt # 创建了个文件,模拟编译产生的文件
- ls app
build2:
stage: build2
tags:
- build
before_script:
- ls
- ls app
cache:
key: build2 # 为缓存提供唯一的标识键
paths:
- app/c.txt # 将 app 下的 c.txt 文件创建一个缓存
script:
- ls
- id
- echo 'test123' >> app/c.txt # 创建了个文件,模拟编译产生的文件
- ls app
build3:
stage: build3
tags:
- build
before_script:
- ls
- ls app
cache:
# key: build3 # 没有设置 key,将使用 default
paths:
- app/e.txt # 将 app 下的 c.txt 文件创建一个缓存
script:
- ls
- id
- echo 'test666' >> app/e.txt # 创建了个文件,模拟编译产生的文件
- ls app
test1:
stage: test1
tags:
- build
before_script:
- ls
- ls app
script:
- echo "run test"
- echo 'test' >> app/c.txt # 创建了个文件
- ls app # 在查看 app 下的内容
cache:
policy: pull # 缓存的策略是仅在作业开始时下载缓存,但在作业完成时从不上传更改
key: build1
paths: # 使用了 key,必须要有 paths,下载 a.txt 文件
- app/a.txt
- app/c.txt # 缓存 build1 里没有 c.txt 文件,所以不会下载。由于策略原因,c.txt 文件也不会上传到缓存里
test2:
stage: test2
tags:
- build
before_script:
- ls
- ls app
script:
- echo "run test"
- echo 'test' >> app/d.txt
- ls app # 在查看 app 下的内容
cache:
policy: push # 缓存的策略是仅在作业完成时上传缓存,但在作业开始时从不下载缓存
key: build2
paths:
- app/d.txt # 由于策略设置的是 push,所以会上传
- app/c.txt # 由于设置的策略是 push,所以不会下载 build2 里的 c.txt 文件,上传缓存时会给出警告
deploy:
stage: deploy
tags:
- build
before_script:
- ls
- ls app
script:
- echo "run deploy"
- ls app # 在查看 app 下的内容
retry:
max: 2
when:
- script_failure运行上面的流水线,查看日志,先来查看 build1 的日志
build1 日志
可以看到,重置缓存的时候是去 build1-protected 下面去下载缓存的
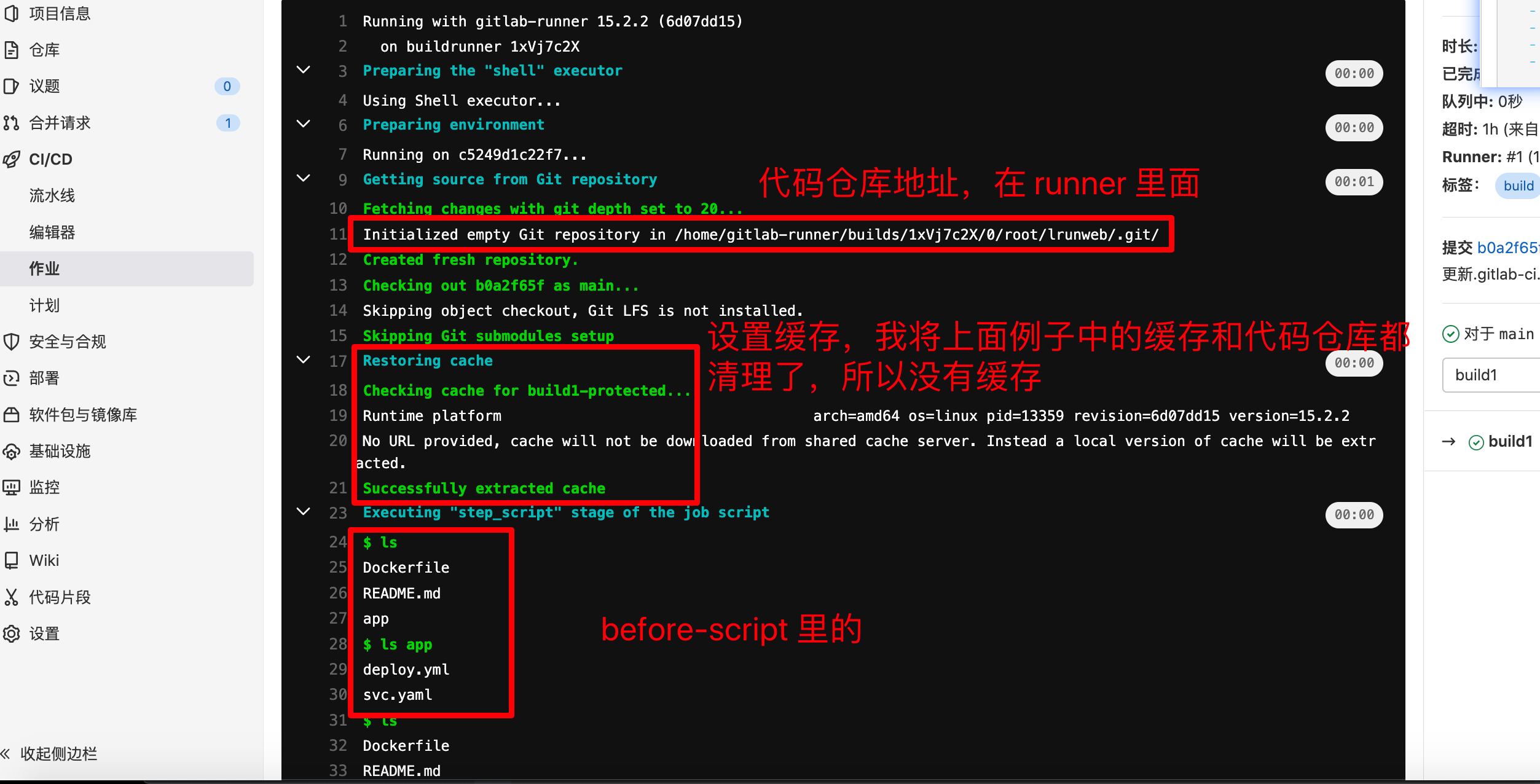

build2 日志
可以看到,重置缓存的时候是去 build2-protected 下面去下载缓存的


build3 日志


进入 runner 里查看下缓存

test1 日志


test2 日志


deploy 日志




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)