


第一次个人编程作业
https://github.com/zouzou-1/031902543
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(3')
(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。(3')
PSP2.1 Personal Software Process Stages 预估耗时(分钟) 实际耗时(分钟) Planning 计划 · Estimate · 估计这个任务需要多少时间 15 10 Development 开发 · Analysis · 需求分析 (包括学习新技术) 180 70 · Design Spec · 生成设计文档 30 15 · Design Review · 设计复审 30 10 · Coding Standard · 代码规范 (为目前的开发制定合适的规范) 30 30 · Design · 具体设计 30 60 · Coding · 具体编码 300 540 · Code Review · 代码复审 60 30 · Test · 测试(自我测试,修改代码,提交修改) 120 360 Reporting 报告 · Test Repor · 测试报告 120 120 · Size Measurement · 计算工作量 30 30 · Postmortem & Process Improvement Plan · 事后总结, 并提出过程改进计划 120 300 · 合计 1065 1575
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
代码如何组合几个类,几个函数,他们之间关系如何?
答:代码分为两个类和一个函数,他们之间的关系是以sensitive_class类为主,在需要获取txt文本时调用readtxt函数,在构建敏感词字典是,先调用拓展类,进行敏感词的拓展。
本函数实现txt文件按行读入,形成一个列表,列表的元素是文本的每一行
# 按行读取txt文件: def readtxt(file_name)这是一个类,作用是构建一个敏感词库、匹配敏感词和打印文本
#构建敏感词库和检测敏感词的类 class sensitive_class(object) #初始化敏感词字典 def __init__(self) #将一个词加入敏感词字典函数 def add_word(self, word) #搜索是否配对的函数 def search_match_word(self,line, begin_index, match_type=MinMatchType) #待检测文本一行一行进入检测的函数 def test_in_line(self,line, match_type=MinMatchType) #开始检测文本的入口函数,检测从这个函数开始 def test_for_sensitivewords(self)这是一个类,作用是拓展敏感词库
#拓展敏感词库(拼音和部分大小写情况)的类 class cartesian(object): def __init__(self,words) #用于得到,例如['法','fa','f','F'],['F','f'],这样的列表 def expand_sensitivewords(self,word) #添加生成笛卡尔积的数据列表 def add_data(self,data=[]) #计算笛卡尔积,即得到'法轮gong'、'***'这样的字符串添加到敏感词字典里 def build(self,words)算法的关键之处
首先一定是建立敏感词字典,利用字典的嵌套和key:value的对应,构建一个类似树一样的结构。
其次是在大佬那看到的笛卡尔积的使用上。最开始能得到以下的数据:
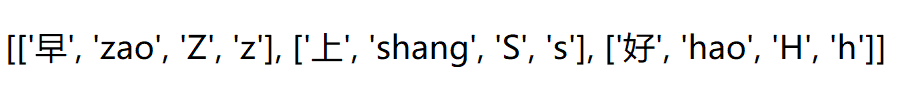
**怎么做也没办法出来想要的结果:**
**经过短短几行代码就能完成。**#几个列表算笛卡尔积 def build(self, words): for item in itertools.product(*self._data_list): str_1 = '' for word in item: str_1 += word result_matched[str_1] = words expand_sensitivewords_list.append(str_1)
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
答:
- **个人能力不足,没有进展到改进模块性能上,所以所花费时间为1分钟。1分钟的花费如下:
以下是第一次获取的性能分析表**
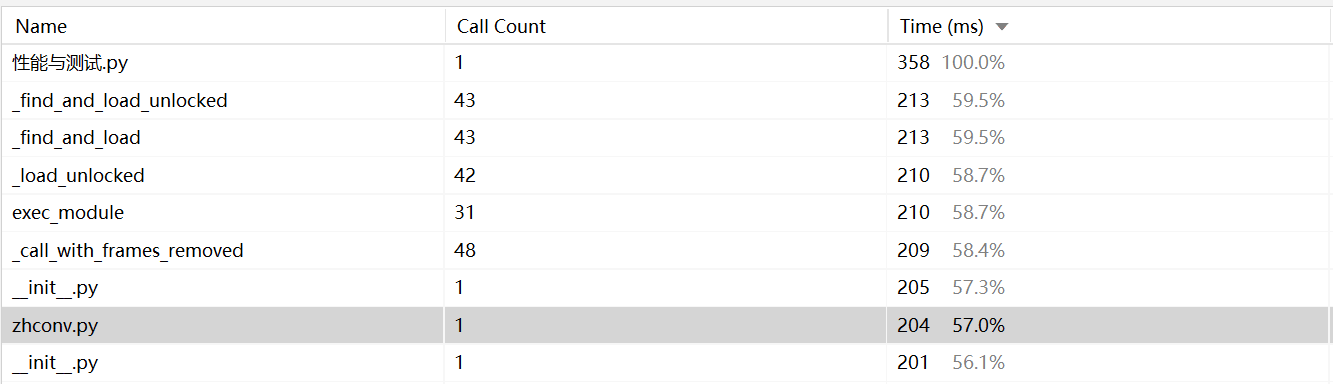
可以看出zhconv.py花费的时间很多,但是,这个功能我没有用到呀(想实现繁体字的功能,然而出现了很奇怪的问题就没继续了),猜测是import的时候就花了很多时 间,所以删除掉了。以此,检查一遍代码,把一些用不着的和用不来的库删除。
- 得到了以下新的性能分析图:
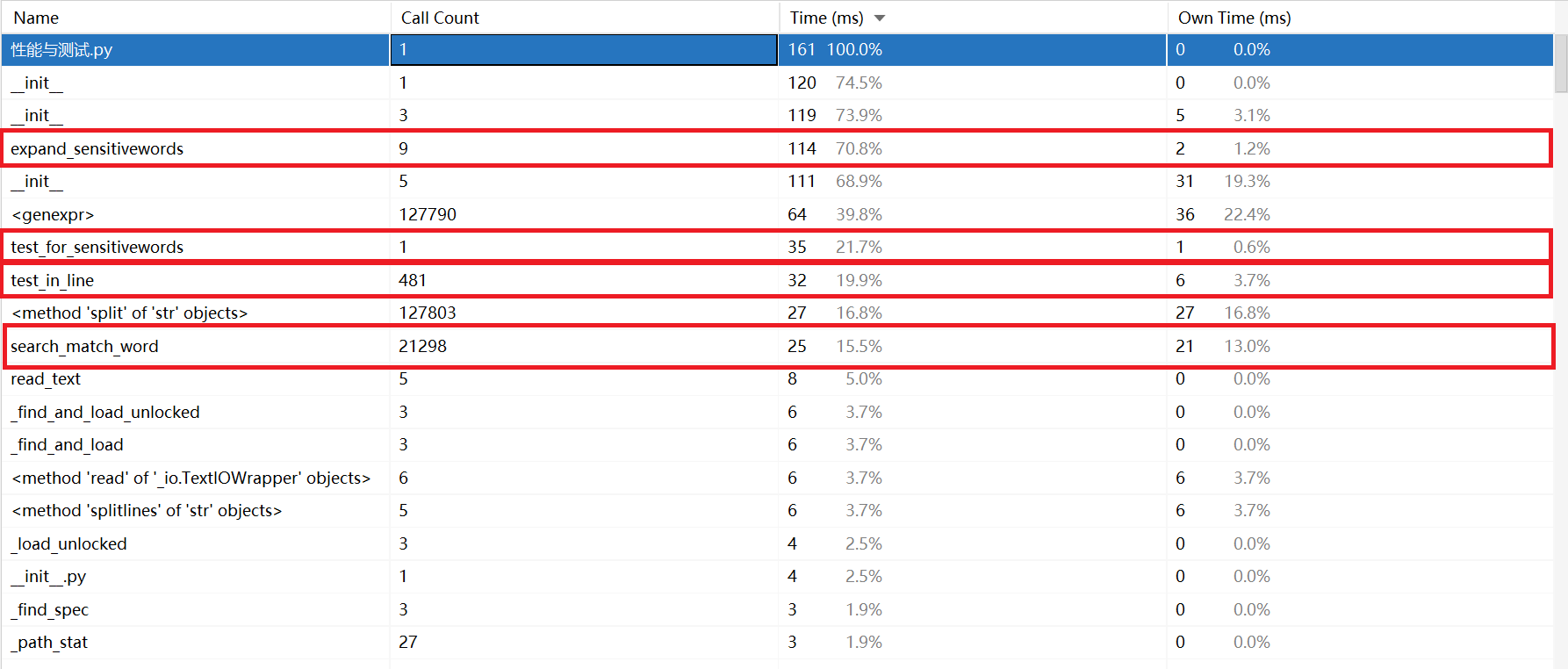
- 看得出花费时间最多的是expand_sensitivewords函数。
#用于得到,例如['法','fa','f','F'],['F','f'],这样的列表 def expand_sensitivewords(self,word): #汉字时 if u'\u4e00' <= word <= u'\u9fff': p=Pinyin() py_all=p.get_pinyin(word)#全拼 py_dhead=p.get_initial(word)#首字母 py_xhead=py_dhead.lower()#小写首字母 self.add_data([word,py_all,py_dhead,py_xhead]) #字母时 else: if 'a'<= word <='z': py_xhead=word py_dhead=word.upper()#转换大写 self.add_data([word,py_dhead]) else: py_xhead=word.lower()#转换小写 py_dhead=word self.add_data([word,py_xhead]) **这个函数实现的是获取汉字拼音,字母大小写的功能,所以花费时间多,原因在于调用xpinyin这个库。
前4的函数都是用于实现字符串匹配的,花最多的时间在匹配上总比花时间在其他冗杂又简单的函数上要好 一些。**
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
- 测试构建敏感词字典这部分的函数
测试代码如下:
from func.main import * def test_sensitive_map() : s = sensitive_class()构思思路:这部分的类真的写的乱七八糟,是在找不出可以assert的数据结构或者变量,所以就调用了这个类构建sensitive_class()这个类得到覆盖率。
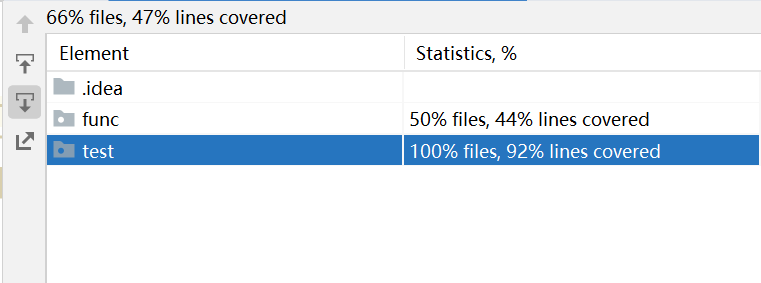
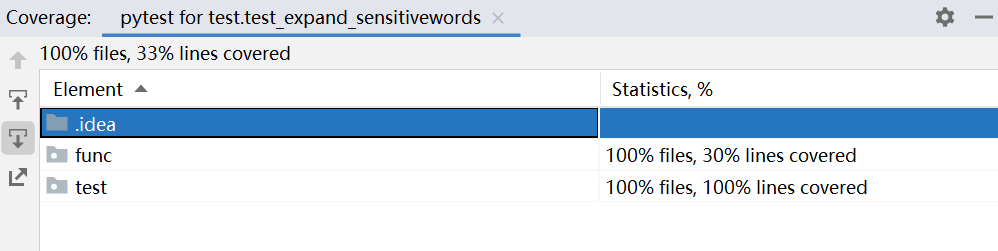
测试覆盖率截图:
- 测试拓展类
测试代码如下:
#导入cartesian类 from func.main import cartesian #测试cartesian类,测试是否能到对应的字符串。 def test_expand_sensitivewords(): c = cartesian("早上好") #判断中间过程的结果是否正确 assert c._data_list == [['早', 'zao', 'Z', 'z'], ['上', 'shang', 'S', 's'], ['好', 'hao', 'H', 'h']]构思思路:
导入这个类,创建对象。对比中间过程是否一致。
测试覆盖率截图:
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
- 异常场景:命令行参数输入格式错误。
代码:
if len(sys.argv) == 4: for i in sys.argv: read_file_name.append(str(i)) else: print("检查一下输入") exit(0)结果:

三、心得
(4.1)在完成本次作业过程的心得体会(3')
心得一:千万不要还没开始就害怕。第一次看作业要求的时候,真的感到震撼和恐慌。需求不知道怎么实现,测试不知道怎么操作。因为这份不安和害怕,导致一遇到问题就想退缩不做了。
心得二:基础很重要,千万不要认为把时间放在学习基础知识上会浪费时间。最开始的几天,从网络上找了很多JAVA的代码来看,也尝试了很久去修改,然而,久久没有进展。归结原因,就是对Java不了解,又不敢把时间放在学习基础知识上,急切地想要赶紧上手。卡在最开始真的很崩溃。后来,听说Python比较好写,决定从零开始,没学完基础的语法就绝不碰和作业有关的代码。花了一段时间把基础的语法学清楚后,理解网上的代码比原来快了许多的。
心得三:遇到暂时实现不了的需求,多学学,多看看,多交流,说不定就能峰回路转。在写代码的过程中,每一次遇到困难去网上找找方法,和同学交流交流,也许就会有转机。
最后,还有许多需求没有实现,很遗憾也很失落。希望下一次作业能比这次更好。

