第三次作业
1.基本信息
- 学号:2017*****1046;
- 姓名:邹一铭
- 码云仓库地址:https://gitee.com/zouxiaoming/word_frequency
2.程序分析
(1)首先声明编码方式和导入string模块中的punctuation方法
from string import punctuation
(2)读取文件到缓冲区
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
f1=open(dst,"r")
except IOError as s:
print (s)
return None
try: # 读文件到缓冲区
bvffer=f1.read()
except:
print ("Read File Error!")
return None
f1.close()
return bvffer
(3)数据处理,设置缓冲区,处理缓冲区bvffer的文件,并去除字符串中的符号将单词分割并读入词典,统计词频。
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer的代码,统计每个单词的频率,存放在字典word_freq
bvffer=bvffer.lower()
for x in '~!@#$%^&*()_+/*-+\][':
bvffer=bvffer.replace(x, " ")
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0)+1
return word_freq
(4)设置输出函数,用输出函数处理好单词按照词频顺序排列,输出词频top10的单词。
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
(5)对main函数进行封装,用于测试
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
3.性能分析结果及改进
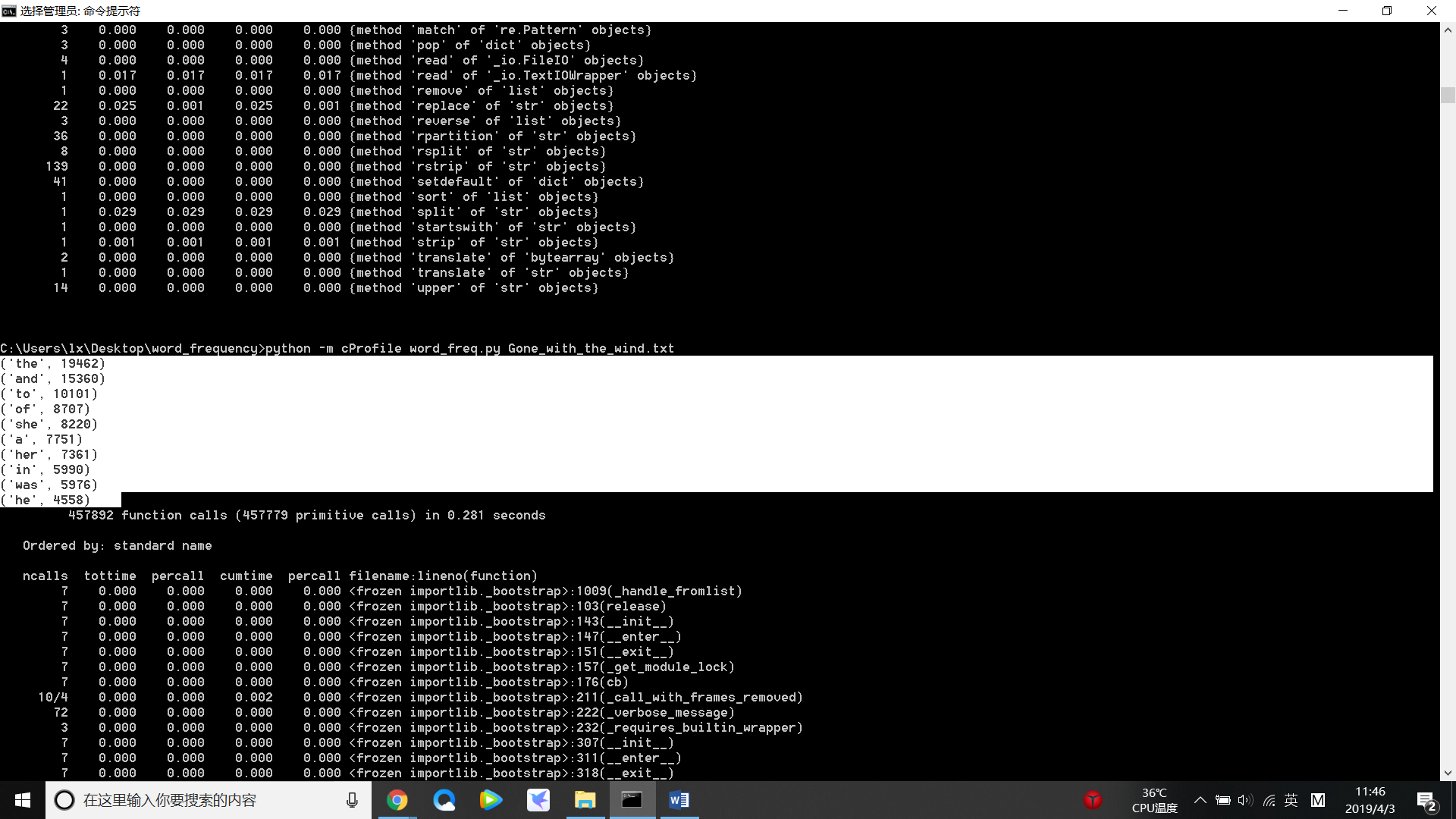
(1)测试:Gone_with_the_wind.txt 中词频统计top10:
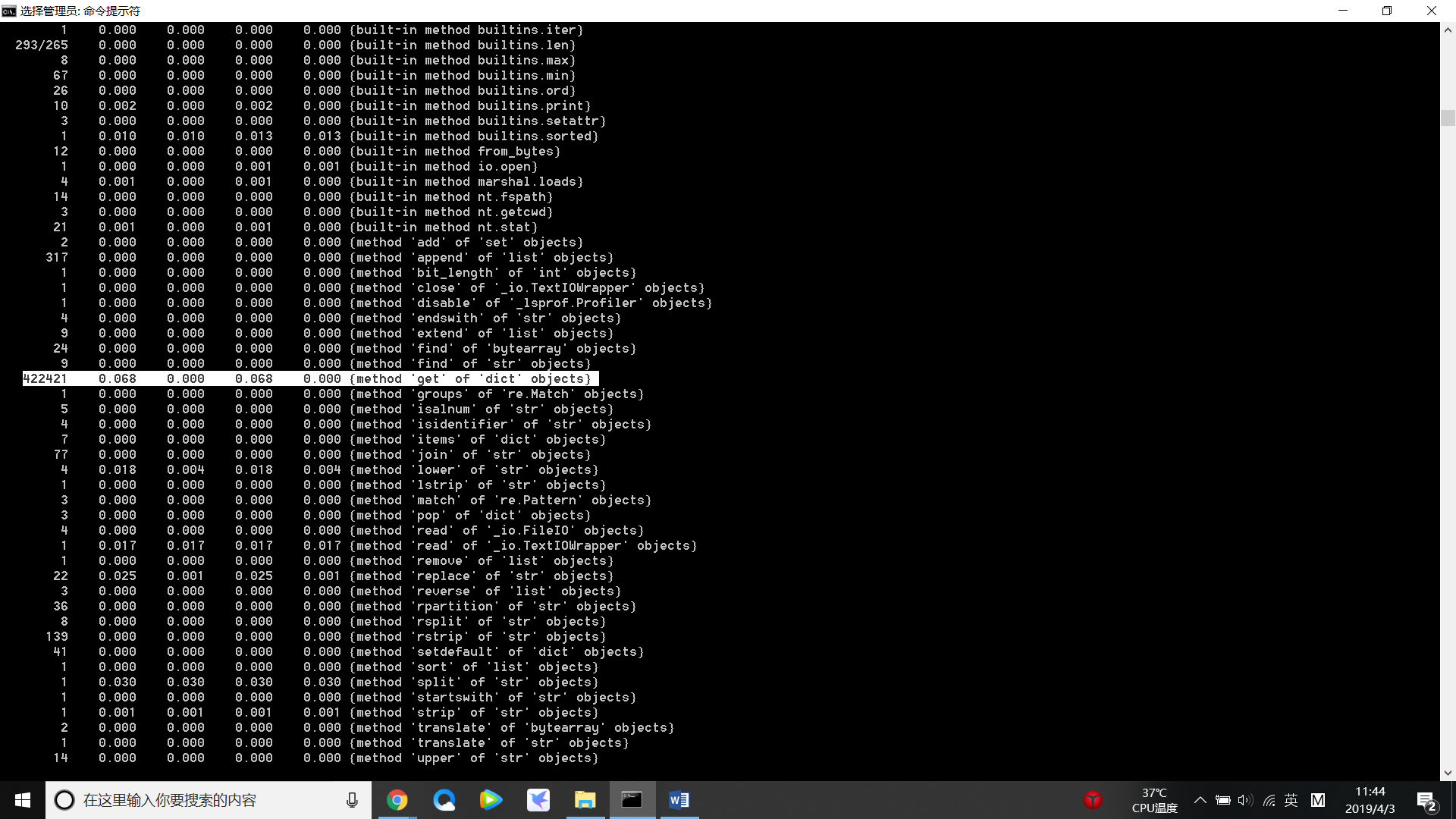
(2)测试:Gone_with_the_wind.txt 中执行次数最多的代码:
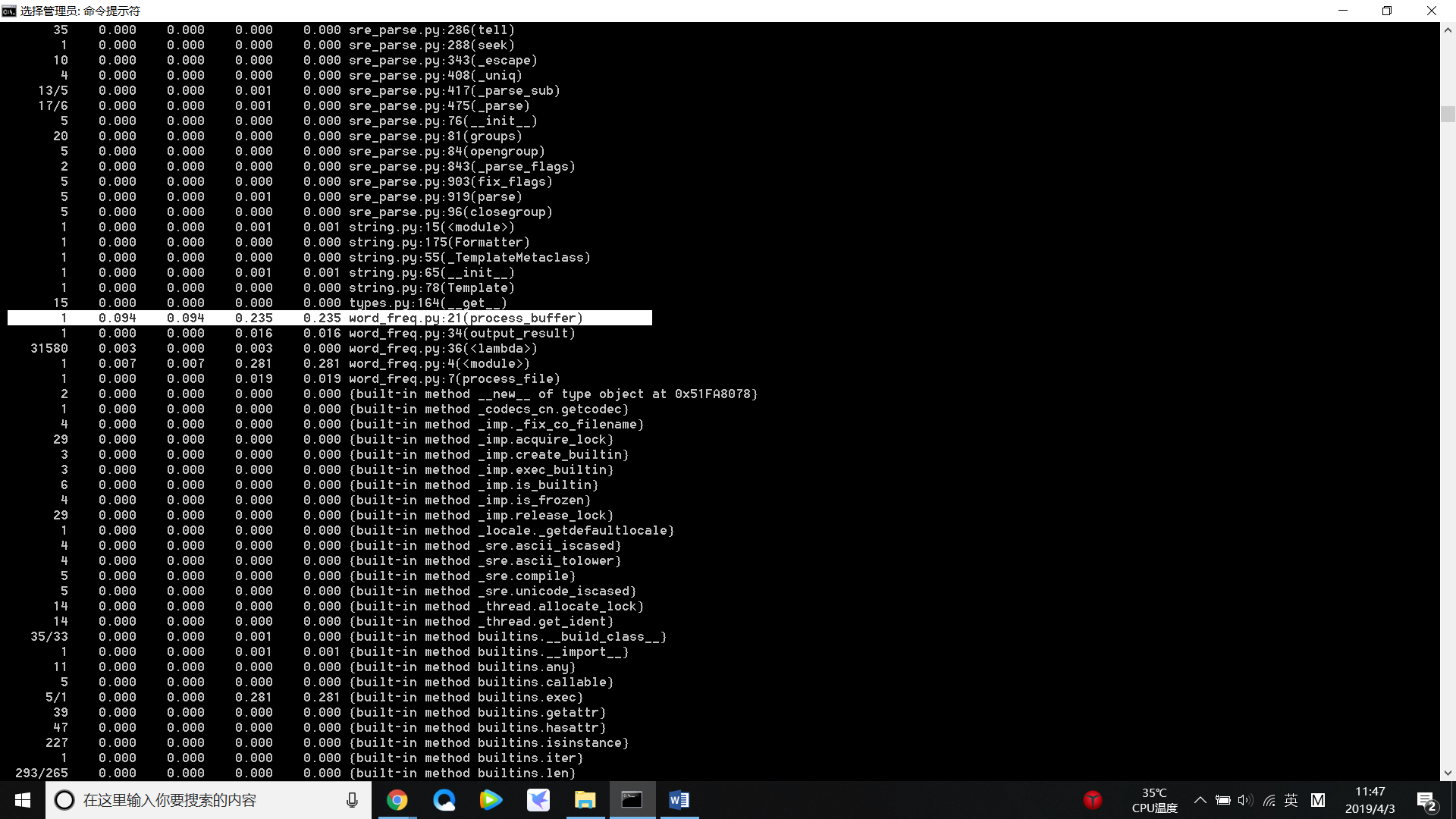
(3)测试:Gone_with_the_wind.txt 中执行时间最长的代码:
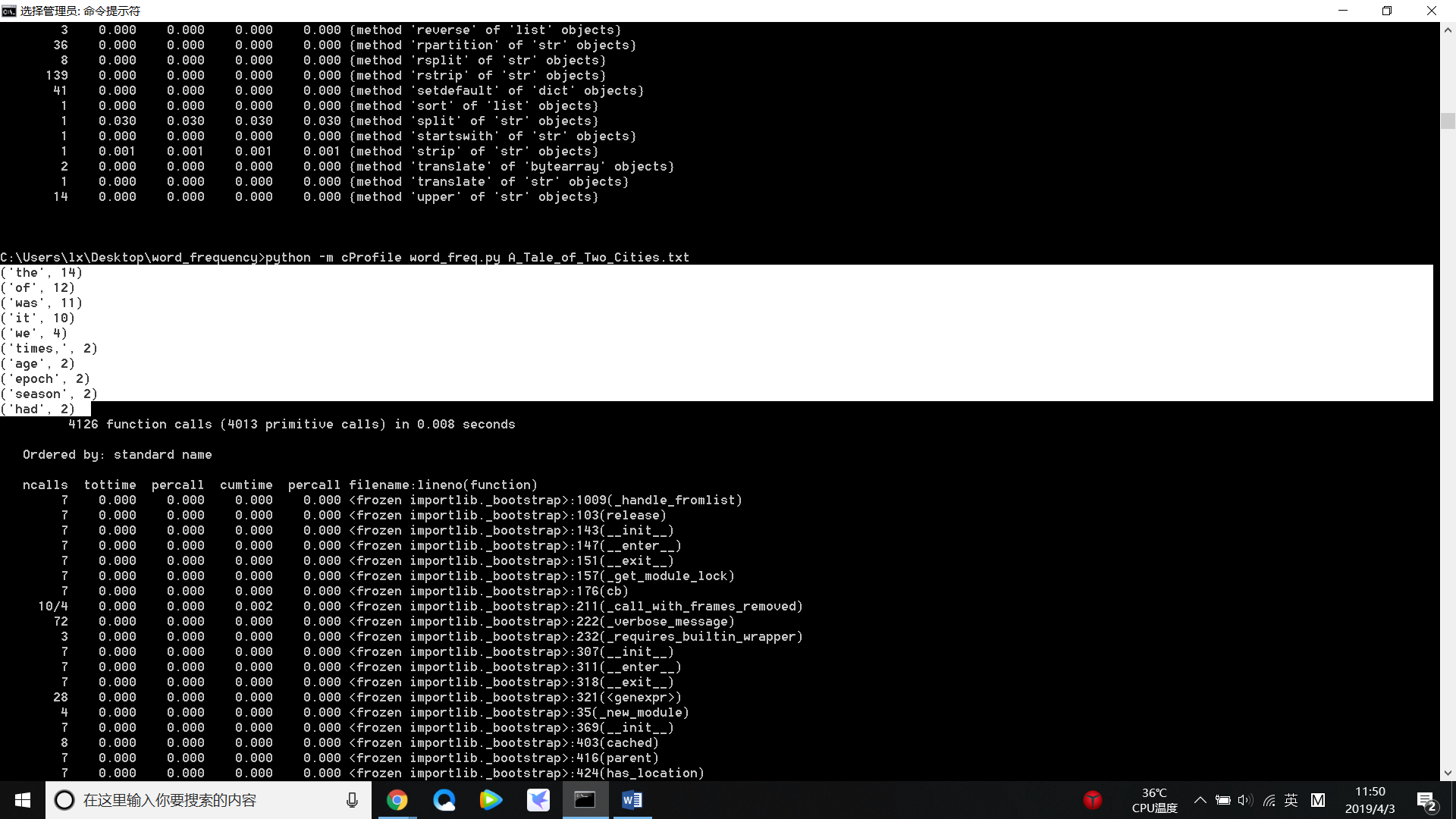
(4)测试:A_Tale_of_Two_Cities.txt 中词频top 10:
(5)A_Tale_of_Two_Cities.txt 中执行次数最多代码:
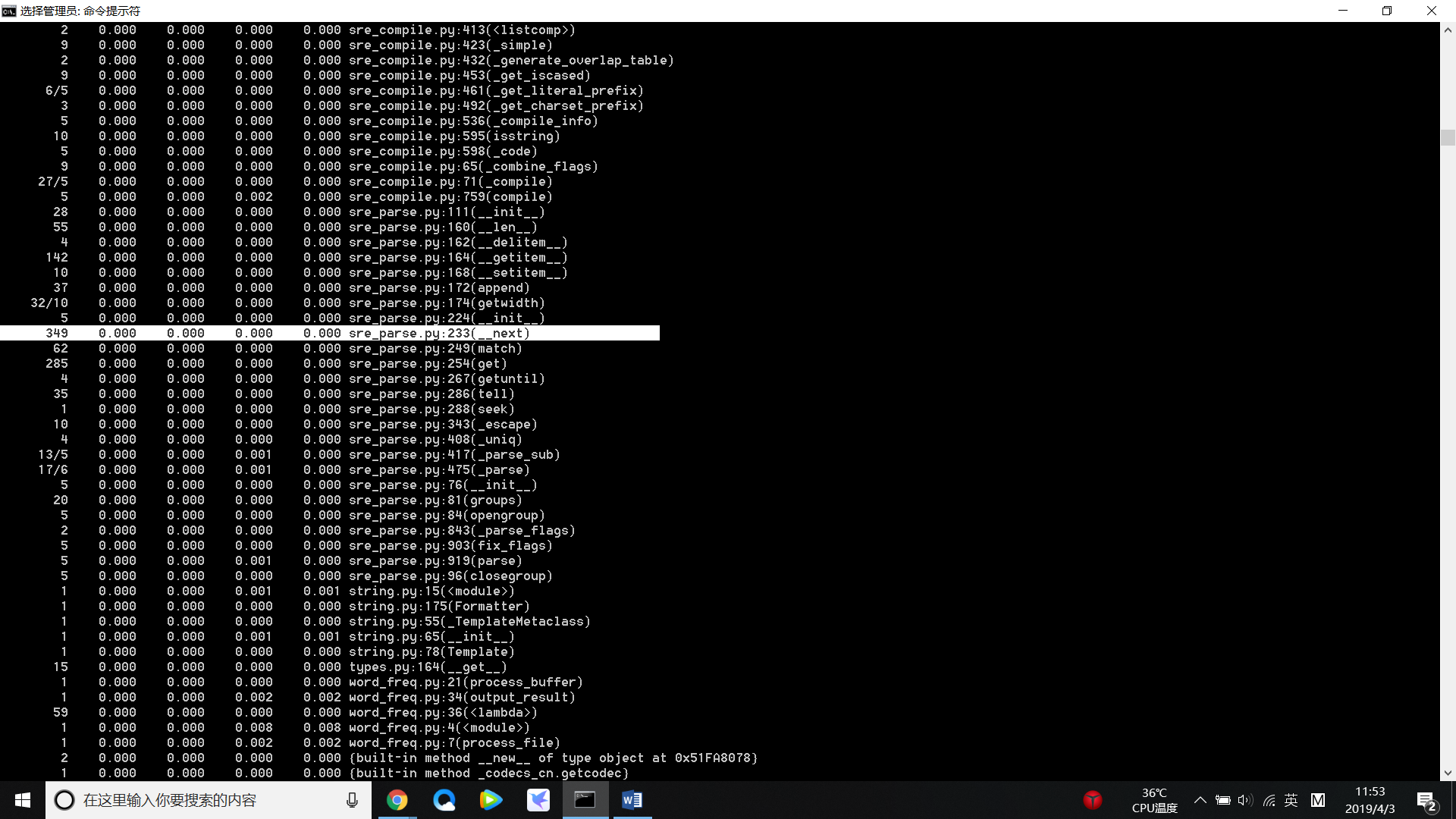
3.代码改进
把执行时间最长的代码进行优化改进,可以使其速度更快,用时更少
1.将
def process_buffer(bvffer):
函数中的代码:
5 for item in bvffer.strip().split(): 6 word = item.strip(punctuation+' ') 7 if word in word_freq.keys(): 8 word_freq[word] += 1 9 else: 10 word_freq[word] = 1
更改为
bvffer=bvffer.lower()
for x in '~!@#$%^&*()_+/*-+\][':
bvffer=bvffer.replace(x, " ")
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0)+1
改进后速度截图
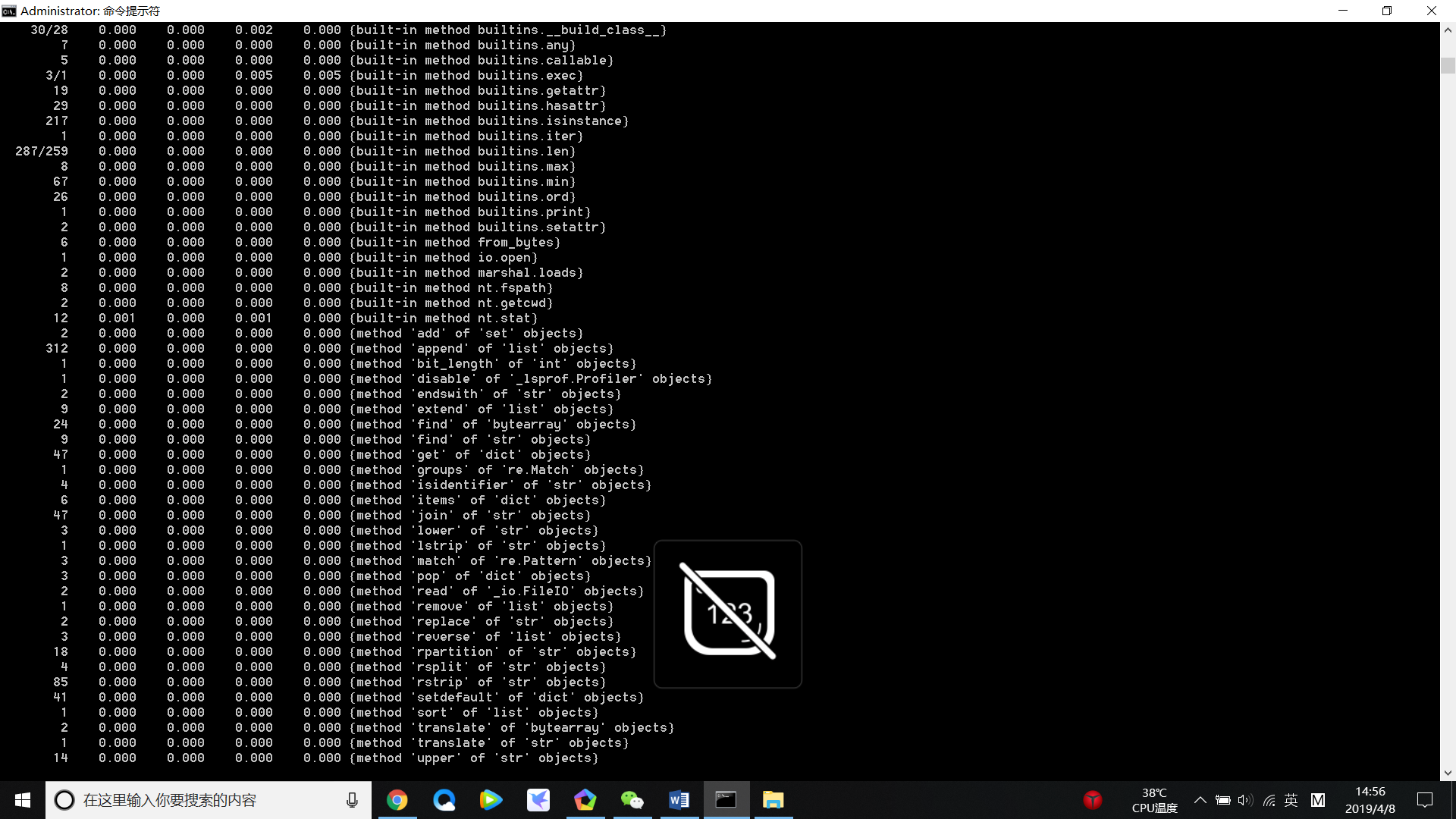
更改后速度会有明显提升
4.总结
在本次课后作业中,使我更加熟练的掌握了码云以及博客网的使用,并且复习了上次作业中git传输远程仓库的操作,又新学会了如何创建git分支。在python中,又学会了新的函数与语句
并且学会了如何使用使用cProfile进行性能分析已经明白了什么是性能分析器,相信在以后的学习中,我会更加努力,学到更多的知识。
如
for x in '~!@#$%^&*()_+/*-+\][': bvffer=bvffer.replace(x, " ") words=bvffer.strip().split()
这个代码中,经过学习,知道了 它的作用是去除文件中的符号,并且也从新的复习了一边python中的 for 循环。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号