
RabbitMq 入门应用 提升性能 : 算法多阶段并行 (Python)
大问题: 我们有一个算法,它可以被分为多个阶段进行(顺序不可颠倒),每个阶段的性能和资源要求不同(且不均衡程度比较高);
假设我们现在可以堆资源(较多的CPU和内存),如何将算法各个步骤拆分并进行性能均衡和实现,使得算法性能最大化以满足生产要求?
多进程:
由于算法有严格的顺序要求,如果是针对视频、自然语言等前后关联较强的数据,一次算法运行只能顺序处理一个问题;
比如一段视频只能读入并处理,多进程并不解决单个进程处理缓慢的问题;
同时Python自带的多进程数据共享堪称地狱(Manager)比较难以使用;
多线程:
多线程的数据共享度高(内存上并不分离),如果并行很容易出现争抢关键数据的情况,各种锁导致性能下降严重;
因此我们的选择的方法是异步+中间件(RabbitMq)
单纯地异步可以吗?但是Python/Java等语言天生对异步的支持就很差,想提升性能?想都别想!
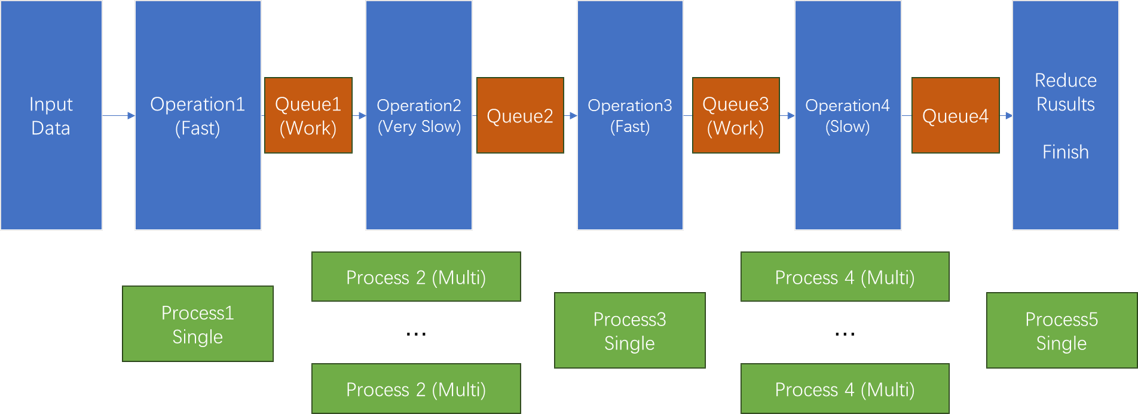
我们只能像上面这样把算法拆开,在关键的节点处堆性能,减少算法从输入到输出的时延,同时避免单个进程导致的资源请求冲突问题。
那么怎么很方便地使用queue传递数据呢?中间件或者TCP只能传递bytes类型的数据?
对于Python而言有个非常好的方案:Pickle import pickle, pickle.dumps(),pickle.loads() 就足以解决大部分问题(而且足够快!),我们就能得到某些数据的bytes信息,然后直接把它丢进队列就好啦!
注意,对于某些指针对象,如高维 numpy.ndarray 的情形,如果它被封装在字典(dict) 或者 链表 (list) 里面,pickle 很可能只会序列化指针的地址(彻彻底底地浅拷贝),导致数据丢失,需要特别注意!
有关Rabbitmq我们需要掌握的技能
由于本篇Blog侧重工程开发和快速入门,我们只需要知道RabbitMq能够帮我们准确无误的传递消息(bytes);
RabbitMq在Linux上的安装 https://www.rabbitmq.com/docs/install-debian 里面这一块(无脑执行就可以了)
之后的启动,命令行输入: rabbitmq-server /etc/rabbitmq/rabbitmq-env.conf
/etc/rabbitmq/rabbitmq-env.conf 是默认的配置文件的位置,简单的操作我们不需要修改配置文件;
一些常用的操作:命令行输入
查看现在的队列的情况 (能看到现在队列里面消息的情况)
rabbitmqctl list_queues
删除队列
rabbitmqctl delete_queue $Your_queue_name
清空队列消息
rabbitmqctl purge_queue $Your_queue_name
详细内容请参考:
https://www.cnblogs.com/thomas-fan/p/15888556.html (比较齐全)
之后建议去看一看 HelloWorld和第一个工作模式(Worker),不过大部分的参数都不需要改动就能满足简单的需求
Python 使用
首先安装pika pip inistall pika 就可以
其实我们只要学会Hello World里面的内容就能做很多事情了!
newTask.py
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=pika.DeliveryMode.Persistent
))
print(f" [x] Sent {message}")
connection.close()
worker.py
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue',on_message_callback=callback)
channel.start_consuming()
这两个程序运行起来(其中 worker.py 多跑几个,然后不停地运行 newTask.py 发送带有 '.' 的消息 如 '123...' 你就能观察到队列的运行啦(多个进程分别处理消息)!)
程序中重点语句:
channel.basic_consume(queue='task_queue',on_message_callback=callback) 监听队列,当有消息产生的时候调用 callback函数! ‘task_queue’是监听的队列
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=pika.DeliveryMode.Persistent
))
发消息,往 'task_queue' 里面发
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
启动和注册队列;
更加进阶的知识:
https://www.rabbitmq.com/tutorials/tutorial-two-python
https://www.cnblogs.com/guyuyun/p/14970592.html
总结:
例子中的消息是持久化的,消息和队列若不被处理和删除就会一直存在于队列当中
对于大部分的上手的调试工作,清除队列消息再重启或者在保留消息的情形下进入消息处理程序进行Debug都是非常方便且常用的方法!
其他的一些小TIPS
删除消息删不掉的时候,请注意是不是有与队列相关的进程没有释放或者程序卡住造成锁死
如果worker进程处理时间过长(超过一分钟,不得不关闭心跳时,这样关掉心跳)
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost',heartbeat =0))

