

前言
抽象思维是我们工程师最重要的思维能力。因为软件技术 本质上就是一门抽象的艺术。我们的工作是存思维的“游戏”,虽然我们在使用键盘、显示器,打开电脑可以看到主板、硬盘等硬件。但我们即看不到程序如何被执行,也看不到 0101 是如何被 CPU 处理的。
我们工程师每天都要动用抽象思维,对问题域进行分析、归纳、综合、判断、推理。从而抽象出各种概念,挖掘概念和概念之间的关系,对问题域进行建模,然后通过编程语言实现业务功能。所以,我们大部分的时间并不是在写代码,而是在梳理需求,理清概念。当然,也包括尝试看懂那些“该死的、别人写的”代码。
在我接触的工程师中,能深入理解抽象概念的并不多,能把抽象和面向对象、架构设计进行有机结合,能用抽象思维进行问题分析、化繁为简的同学更是凤毛麟角。
对于我本人而言,每当我对抽象有进一步的理解和认知,我都能切身感受到它给我在编码和设计上带来的质的变化。同时,感慨之前对抽象的理解为什么如此肤浅。如果时间可以倒流的话,我希望我在我职业生涯的早期,就能充分意识到抽象的重要性,能多花时间认真的研究它,深刻的理解它,这样应该可以少走很多弯路。
什么是抽象
关于抽象的定义,百度百科是这样说的:
抽象是从众多的事物中抽取出共同的、本质性的特征,而舍弃其非本质的特征的过程。具体地说,抽象就是人们在实践的基础上,对于丰富的感性材料通过去粗取精、去伪存真、由此及彼、由表及里的加工制作,形成概念、判断、推理等思维形式,以反映事物的本质和规律的方法。
实际上,抽象是与具体相对应的概念,具体是事物的多种属性的总和,因而抽象亦可理解为由具体事物的多种属性中舍弃了若干属性而固定了另一些属性的思维活动。[1]
Wikipedia 的解释是:
抽象是指为了某种目的,对一个概念或一种现象包含的信息进行过滤,移除不相关的信息,只保留与某种最终目的相关的信息。例如,一个皮质的足球,我们可以过滤它的质料等信息,得到更一般性的概念,也就是球。从另外一个角度看,抽象就是简化事物,抓住事物本质的过程。[2]
简单而言,“抽”就是抽离,“象”就是具象,字面上理解抽象,抽象的过程就是从“具象”事物中归纳出共同特征,“抽取”得到一般化(Generalization)的概念的过程。英文的抽象——abstract 来自拉丁文 abstractio,它的原意是排除、抽出。
为了更好的方便你理解抽象,让我们先来看一幅毕加索的画,如下图所示,图的左边是一头水牛,是具象的;右边是毕加索画,是抽象的。怎么样,是不是感觉自己一下子理解了抽象画的含义。
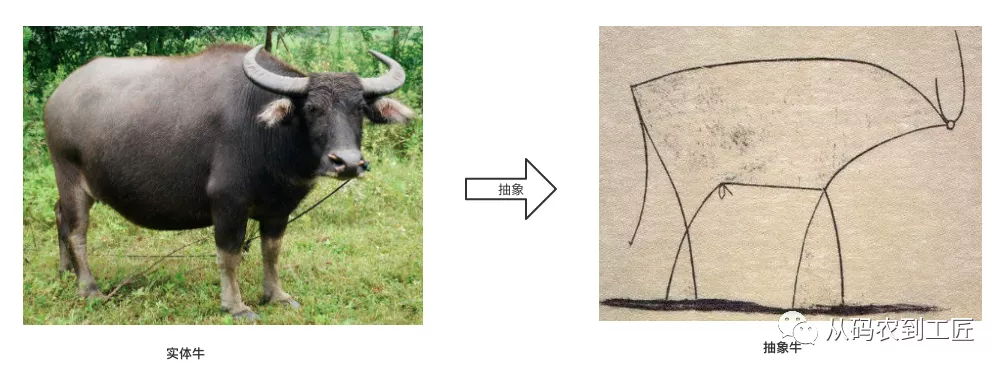
可以看到,抽象牛只有几根线条,不过这几根线条是做了高度抽象之后的线条,过滤了水牛的绝大部分细节,保留了牛最本质特征,比如牛角,牛头,牛鞭、牛尾巴等等。这种对细节的舍弃使得“抽象牛”具有更好的泛化(Generalization)能力。
可以说,抽象更接近问题的本质,也就是说所有的牛都逃不过这几根线条。
抽象和语言是一体的
关于抽象思维,我们在百度百科上可以看到如下的定义:
抽象思维,又称词(概念)的思维或者逻辑思维,是指用词(概念)进行判断、推理并得出结论的过程。抽象思维以词(概念)为中介来反映现实。这是思维的最本质特征,也是人的思维和动物心理的根本区别。[3]
之所以把抽象思维称为词思维或者概念思维,是因为语言和抽象是一体的。当我们说“牛”的时候,说的就是“牛”的抽象,他代表了所有牛共有的特征。同样,当你在程序中创建 Cow 这个类的时候,道理也是一样。在生活中,我们只见过一头一头具象的牛,“牛”作为抽象的存在,即看不见也摸不着。
这种把抽象概念作为世界本真的看法,也是古希腊哲学家柏拉图的最重要哲学思想。柏拉图认为,我们所有用感觉感知到的事物,都源于相应的理念。他认为具体事物的“名”,也就是他说的“理念世界”才是本真的东西,具体的一头牛,有大有小,有公有母,颜色、性情、外形各自不同。因此我们不好用个体感觉加以概括,但是这些牛既然都被统称为“牛”,则说明它们必然都源于同一个“理念”,即所谓“牛的理念”或者“理念的牛”,所以它们可以用“牛”加以概括。尚且不论“理念世界”是否真的存在,这是一个哲学问题,但有一点可以确定,我们的思考和对概念的表达都离不开语言。[4]
这也是为什么,我在做设计和代码审查(Code Review)的时候,会特别关注命名是否合理的原因。因为命名的好坏,在很大程度上反映了我们对一个概念的思考是否清晰,我们的抽象是否合理,反应在代码上就是,代码的可读性、可理解性是不是良好,以及我们的设计是不是到位。
有人做过一个调查,问程序员最头痛的事情是什么,通过 Quora 和 Ubuntu Forum 的调查结果显示,程序员最头疼的事情是命名。如果你曾经为了一个命名而绞尽脑汁,就不会对这个结果感到意外。
就像 Stack Overflow 的创始人 Joel Spolsky 所说的:“起一个好名字应该很难,因为,一个好名字需要把要义浓缩在一到两个词。(Creating good names is hard, but it should be hard, because a great name captures essential meaning in just one or two words)。”
是的,这个浓缩的过程就是抽象的过程。我不止一次的发现,当我觉得一个地方的命名有些别扭的时候,往往就意味着要么这个地方我没有思考清楚,要么是我的抽象弄错了。
关于如何命名,我在《代码精进之路》里已经有比较详尽的阐述,这里就不赘述了。
我想强调的是,语言是明晰概念的基础,也是抽象思维的基础,在构建一个系统时,值得我们花很多时间去斟酌、去推敲语言。在我做过的一个项目中,就曾为一个关键实体讨论了两天,因为那是一个新概念,尝试了很多名字,始终感觉到别扭、不好理解。随着我们讨论的深入,对问题域理解的深入,我们最终找到了一个相对比较合适的名字,才肯罢休。
这样的斟酌是有意义的,因为明晰关键概念,是我们设计中的重要工作。虽然不合理的命名、不合理的抽象也能实现业务功能。但其代价就是维护系统时需要极高的认知负荷。随着时间的推移,就没人能搞懂系统的设计了。
抽象的层次性
回到毕加索的抽象画,如下图所示,如果映射到面向对象编程,抽象牛就是抽象类(Abstract Class),代表了所有牛的抽象。抽象牛可以泛化成更多的牛,比如水牛、奶牛、牦牛等。每一种牛都代表了一类(Class)牛,对于每一类牛,我们可以通过实例化,得到一头具体的牛实例(Instance)。
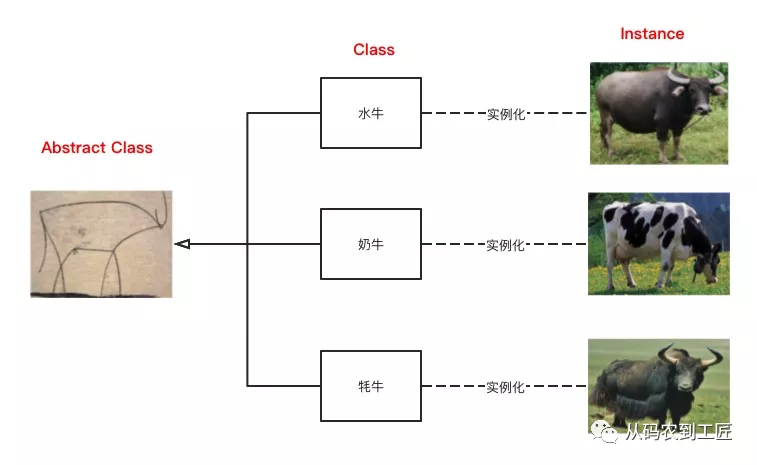
从这个简单的案例中,我们可以到抽象的三个特点:
1. 抽象是忽略细节的。抽象类是最抽象的,忽略的细节也最多,就像抽象牛,只是几根线条而已。在代码中,这种抽象可以是 Abstract Class,也可以是 Interface。
2. 抽象代表了共同性质。类(Class)代表了一组实例(Instance)的共同性质,抽象类(Abstract Class)代表了一组类的共同性质。对于我们上面的案例来说,这些共同性质就是抽象牛的那几根线条。
3. 抽象具有层次性。抽象层次越高,内涵越小,外延越大,也就是说它的涵义越小,泛化能力越强。比如,牛就要比水牛更抽象,因为它可以表达所有的牛,水牛只是牛的一个种类(Class)。
抽象的这种层次性,是除了抽象概念之外,另一个我们必须要深入理解的概念,因为小到一个方法要怎么写,大到 一个系统要如何架构,以及我们后面第三章要介绍的结构化思维,都离不开抽象层次的概念。
在进一步介绍抽象层次之前,我们先来理解一下外延和内涵的意思:
抽象是以概念(词语)来反映现实的过程,每一个概念都有一定的外延和内涵。概念的外延就是适合这个概念的一切对象的范围,而概念的内涵就是这个概念所反映的对象的本质属性的总和。例如“平行四边形”这个概念,它的外延包含着一切正方形、菱形、矩形以及一般的平行四边形,而它的内涵包含着一切平行四边形所共有的“有四条边,两组对边互相平行”这两个本质属性。
一个概念的内涵愈广,则其外延愈狭;反之,内涵愈狭,则其外延愈广。例如,“平行四边形”的内涵是“有四条边,两组对边互相平行”,而“菱形”的内涵除了这两条本质属性外,还包含着“四边相等”这一本质属性。“菱形”的内涵比“平行四边形”的内涵广,而“菱形”的外延要比“平行四边形”的外延狭。
所谓的抽象层次就体现在概念的外延和内涵上,这种层次性,基本可以体现在任何事物上,比如一份报纸就存在多个层次上的抽象,“出版品”最抽象,其内涵最小,但外延最大,“出版品”可以是报纸也可以是期刊杂志等。
-
一个出版品
-
一份报纸
-
《旧金山纪事报》
-
5 月 18 日的《旧金山纪事报》
当我要统计美国有多少个出版品,那么就要用到最上面第一层“出版品”的抽象,如果我要查询旧金山 5 月 18 日当天的新闻,就要用到最下面第四层的抽象。
每一个抽象层次都有它的用途,对于我们工程师来说,如何拿捏这个抽象层次是对我们设计能力的考验,抽象层次太高和太低都不行。
比如,现在要写一个水果程序,我们需要对水果进行抽象,因为水果里面有红色的苹果,我们当然可以建一个 RedApple 的类,但是这个抽象层次有点低,只能用来表达“红色的苹果”。来一个绿色的苹果,你还得新建一个 GreenApple 类。
为了提升抽象层次,我们可以把 RedApple 类改成 Apple 类,让颜色变成 Apple 的属性,这样红色和绿色的苹果就都能表达了。再继续往上抽象,我们还可以得到水果类、植物类等。再往上抽象就是生物、物质了。
你可以看到,抽象层次越高,内涵越小,外延越大,泛化能力越强。然而,其代价就是业务语义表达能力越弱。

具体要抽象到哪个层次,要视具体的情况而定了,比如这个程序是专门研究苹果的可能到 Apple 就够了,如果是卖水果的可能需要到 Fruit,如果是植物研究的可能要到 Plant,但很少需要到 Object。
我经常开玩笑说,你把所有的类都叫 Object,把所有的参数都叫 Map 的系统最通用,因为 Object 和 Map 的内涵最小,其延展性最强,可以适配所有的扩展。从原理上来说,这种抽象也是对的,万物皆对象嘛。但是这种抽象又有什么意义呢?它没有表达出任何想表达的东西,只是一句正确的废话而已。
越抽象,越通用,可扩展性越强,然而其语义的表达能力越弱。越具体,越不好延展,然而其语义表达能力很强。所以,对于抽象层次的权衡,是我们系统设计的关键所在,也是区分普通程序员和优秀程序员的关键所在。
软件中的分层抽象无处不在
越是复杂的问题越需要分层抽象,分层是分而治之,抽象是问题域的合理划分和概念语义的表达。不同层次提供不同的抽象,下层对上层隐藏实现细节,通过这种层次结构,我们才有可能应对像网络通信、云计算等超级复杂的问题。
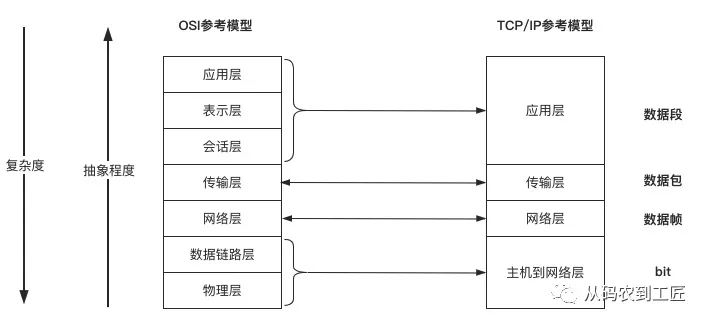
网络通信是互联网最重要的基础实施,但同时它又是一个很复杂的过程,你要知道把数据包传给谁——IP 协议,你要知道在这个不可靠的网络上出现状况要怎么办——TCP 协议。有这么多的事情需要处理,我们可不可以在一个层次中都做掉呢?当然是可以的,但显然不科学。因此,ISO 制定了网络通信的七层参考模型,每一层只处理一件事情,低层为上层提供服务,直到应用层把 HTTP、FTP 等方便理解和使用的协议暴露给用户。
编程语言的发展史也是一个典型的分层抽象的演化史。
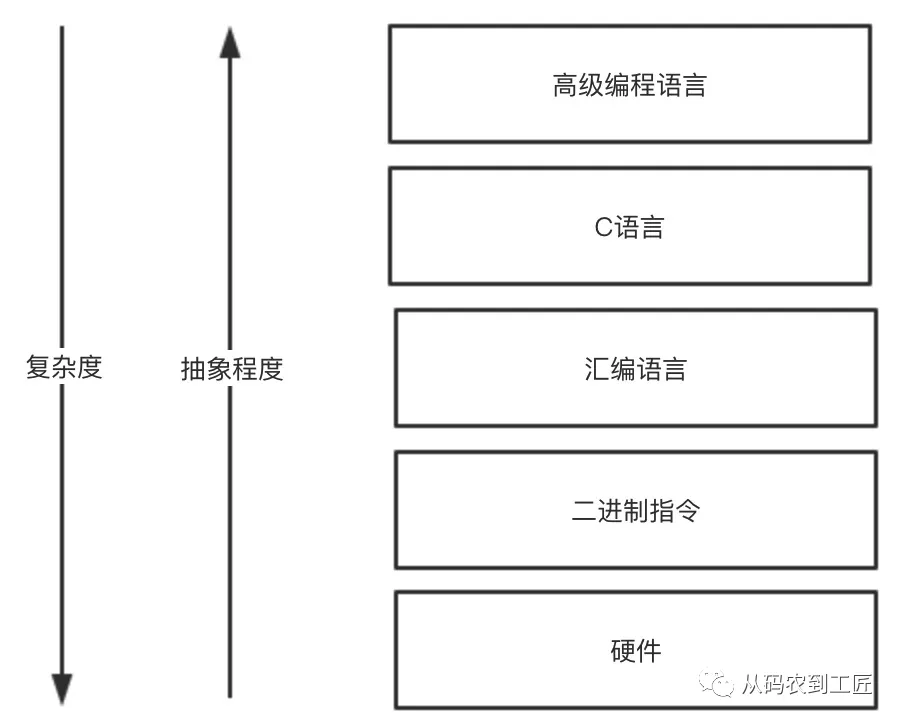
机器能理解的只有机器语言,即各种二进制的 01 指令。如果我们采用 01 的输入方式,其编程效率极低(学过数字电路的同学,体会下用开关实现加减法)。所以我们用汇编语言抽象了二进制指令。
然而汇编还是很底层,于是我们用 C 语言抽象了汇编语言。而高级语言 Java 是类似于 C 这样低级语言的进一步抽象,这种逐层抽象极大的提升了我们的编程效率。
重复代码是抽象的缺失
如果说抽象的本质是共性的话,那么我们代码中的重复代码,是不是就意味着抽象的缺失呢?
是这样的,重复代码是典型的代码坏味道,其本质问题就是抽象的缺失。因为我们 Ctrl+C 加 Ctrl+V 的工作习惯,导致没有对共性代码进行抽取;或者虽然抽取了,只是简单的用了一个 Util 名字,没有给到一个合适的名字,没有正确的反应这段代码所体现的抽象概念,都属于抽象不到位。
有一次,我在 Review 团队代码的时候,发现有一段组装搜索条件的代码,在几十个地方都有重复。这个搜索条件还比较复杂,是以元数据的形式存在数据库中,因此组装的过程是这样的:
-
首先,我们要从缓存中把搜索条件列表取出来;
-
然后,遍历这些条件,将搜索的值填充进去;
简单的重构无外乎就是把这段代码提取出来,放到一个 Util 类里面给大家复用。然而我认为这样的重构只是完成了工作的一半,我们只是做了简单的归类,并没有做抽象提炼。
简单分析,不难发现,此处我们是缺失了两个概念:一个是用来表达搜索条件的类——SearchCondition;另一个是用来组装搜索条件的类——SearchConditionAssembler。只有配合命名,显性化的将这两个概念表达出来,才是一个完整的重构。
重构后,搜索条件的组装会变成一种非常简洁的形式,几十处的复用只需要引用 SearchConditionAssembler 就好了。
由此可见,提取重复代码只是我们重构工作的第一步。对重复代码进行概念抽象,寻找有意义的命名才是我们工作的重点。
因此,每一次遇到重复代码的时候,你都应该感到兴奋,想着这是一次锻炼抽象能力的绝佳机会,当然,测试代码除外。
强制类型转换是抽象层次有问题
面向对象设计里面有一个著名的 SOLID 原则是由 Bob 大叔(Robert Martin)提出来的,其中的 L 代表 LSP,就是 Liskov Substitution Principle(里氏替换原则)。简单来说,里氏替换原则就是子类应该可以替换任何父类能够出现的地方,并且经过替换以后,代码还能正常工作。
思考一下,我们在写代码的过程中,什么时候会用到强制类型转换呢?当然是 LSP 不能被满足的时候,也就是说子类的方法超出了父类的类型定义范围,为了能使用到子类的方法,只能使用类型强制转换将类型转成子类类型。
举个例子,在苹果(Apple)类上,有一个 isSweet() 方法是用来判断水果甜不甜的;西瓜(Watermelon)类上,有一个 isJuicy() 是来判断水分是否充足的;同时,它们都共同继承一个水果(Fruit)类。
此时,我们需要挑选出甜的水果和有水分的西瓜,我们会写一个如下的程序:
因为 pick 方法的入参的类型是 Fruit,所以为了获得 Apple 和 Watermelon 上的特有方法,我们不得不使用 instanceof 做一个类型判断,然后使用强制类型转换转成子类类型,以便获得他们的专有方法,很显然,这是违背了里式替换原则的。
这里问题出在哪里?对于这样的代码我们要如何去优化呢?仔细分析一下,我们可以发现,根本原因是因为 isSweet 和 isJuicy 的抽象层次不够,站在更高抽象层次也就是 Fruit 的视角看,我们挑选的就是可口的水果,只是具体到苹果我们看甜度,具体到西瓜我们看水分而已。
因此,解决方法就是对 isSweet 和 isJuicy 进行抽象,并提升一个层次,在 Fruit 上创建一个 isTasty() 的抽象方法,然后让苹果和西瓜类分别去实现这个抽象方法就好了。
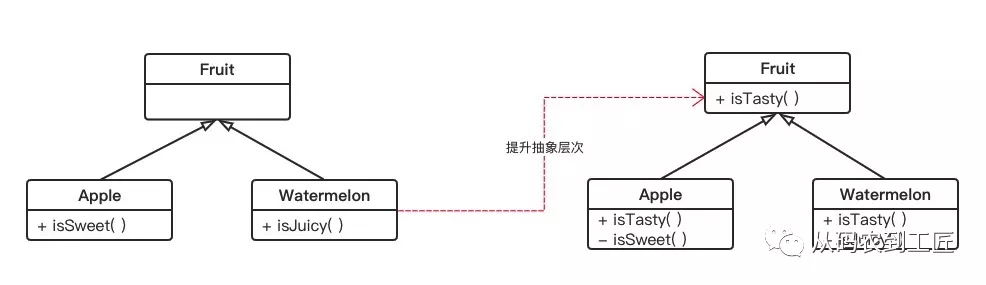
下面是重构后的代码,通过抽象层次的提升我们消除了 instanceof 判断和强制类型转换,让代码重新满足了里式替换原则。抽象层次的提升使得代码重新变得优雅了。
所以,每当我们在程序中准备使用 instanceof 做类型判断,或者用 cast 做强制类型转换的时候。每当我们的程序不满足 LSP 的时候。你都应该警醒一下,好家伙,这又是一次锻炼抽象能力的绝佳机会。
如何提升抽象思维能力
抽象思维能力是我们人类特有的、与生俱来的能力,除了上面说的在编码过程中可以锻炼抽象能力之外,我们还可以通过一些其他的练习,不断的提升我们的抽象能力。
多阅读
为什么阅读书籍比看电视更好呢?因为图像比文字更加具象,阅读的过程可以锻炼我们的抽象能力、想象能力,而看画面的时候会将你的大脑铺满,较少需要抽象和想象。
这也是为什么我们不提倡让小孩子过多的暴露在电视或手机屏幕前的原因,因为这样不利于他抽象思维的锻炼。
抽象思维的差别让孩子们的学习成绩从初中开始分化,许多不能适应这种抽象层面训练的,就去读技校了,因为技校比大学会更加具象:车铣刨磨、零部件都能看得见摸得着。体力劳动要比脑力劳动来的简单。
多总结沉淀
小时候不理解,语文老师为什么总是要求我们总结段落大意、中心思想什么的。现在回想起来,这种思维训练在基础教育中是非常必要的,其实质就是帮助学生提升抽象思维能力。
记录也是很好的总结习惯。就拿读书笔记来说,最好不要原文摘录书中的内容,而是要用自己的话总结归纳书中的内容,这样不仅可以加深理解,而且还可以提升自己的抽象思维能力。
我从四年前开始系统的记录笔记,做总结沉淀,构建自己的知识体系。这种思维训练的好处显而易见,可以说我之前写的《从码农到工匠》和现在正在写的《程序员必备的思维能力》都离不开我总结沉淀的习惯。
命名训练
每一次的变量命名、方法命名、类命名都是一次难得的抽象思维训练机会,前面已经说过了,语言和抽象是一体的,命名的好坏直接反应了我们的问题域思考的是否清晰,反映了我们抽象的是否合理。
现实情况是,我们很多的工程师常常忽略了命名的重要性,只要能实现业务功能,名字从来就不是重点。
实际上,这是对系统的不负责任,也是对自己的不负责任,更是对后期维护系统的人不负责任。写程序和写文章有很大的相似性,本质上都是在用语言阐述一件事情。试想下,如果文章中用的都是些词不达意的句子,这样的文章谁能看得懂,谁又愿意去看呢。
同样,我一直强调代码要显性化的表达业务语义,其中命名在这个过程中扮演了极其重要的角色。为了代码的可读性,为了系统的长期可维护性,为了我们自身抽象思维的训练,我们都不应该放过任何一个带有歧义、表达模糊、意不清的命名。
领域建模训练
对于技术同学,我们还有一个非常好的提升抽象能力的手段——领域建模。当我们对问题域进行分析、整理和抽象的时候,当我们对领域进行划分和建模的时候,实际上也是在锻炼我们的抽象能力。
我们可以对自己工作中的问题域进行建模,当然也可以通过阅读一些优秀源码背后的模型设计来学习如何抽象、如何建模。比如,我们知道 Spring 的核心功能是 Bean 容器,那么在看 Spring 源码的时候,我们可以着重去看它是如何进行 Bean 管理的?它使用的核心抽象是什么?不难发现,Spring 是使用了 BeanDefinition、BeanFactory、BeanDefinitionRegistry、BeanDefinitionReader 等核心抽象实现了 Bean 的定义、获取和创建。抓住了这些核心抽象,我们就抓住了 Spring 设计主脉。
除此之外,我们还可以进一步深入思考,它为什么要这么抽象?这样抽象的好处是什么?以及它是如何支持 XML 和 Annotation(注解)这两种关于 Bean 的定义的。
这样的抽象思维锻炼和思考,对提升我们的抽象能力和建模能力非常重要。关于这一点,我深有感触,初入职场的时候,当我尝试对问题域进行抽象和建模的时候,会觉得无从下手,建出来的模型也感觉很别扭。
然而,经过长期的、刻意的学习和锻炼之后,很明显可以感觉到我的建模能力和抽象能力都有很大的提升。不但分析问题的速度更快了,而且建出来的模型也更加优雅了。
小结
-
抽象思维是程序员最重要的思维能力,抽象的过程就是寻找共性、归纳总结、综合分析,提炼出相关概念的过程。
-
语言和抽象是一体的,抽象思维也叫词思维,因为抽象的概念只能通过语言才能表达出来。
-
抽象是有层次性的,抽象层次越高,内涵越小,外延越大,扩展性越好;反之,抽象层次越低,内涵越大,外延越小,扩展性越差,但语义表达能力越强。
-
对抽象层次的拿捏,体现了我们的设计功力,视具体情况而定,抽象层次既不能太高,也不能太低。
-
重复代码意味着抽象缺失,强制类型转换意味着抽象层次有问题,我们可以利用这些信号来重构代码,让代码重新变的优雅。
-
我们可以通过刻意练习来提升抽象能力,这些练习包括阅读、总结、命名训练、建模训练等。

