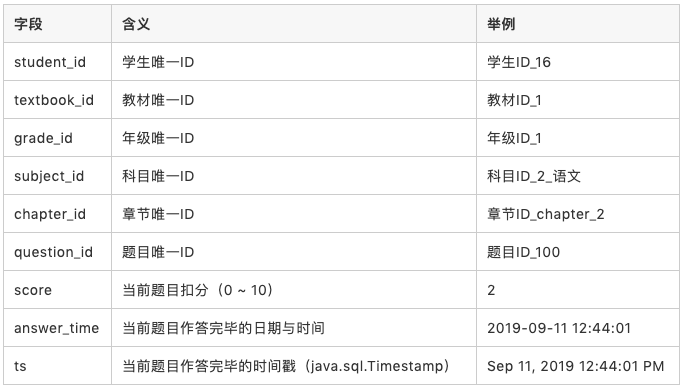
这套业务系统中,学生在手机 App 中对老师布置的作业进行答题训练,每次答题训练提交的数据格式如下表所示:
例如,传入到后台的单条答题记录数据格式如下:
|
{
|
|
|
"student_id": " 学生 ID_16",
|
|
|
"textbook_id": " 教材 ID_1",
|
|
|
"grade_id": " 年级 ID_1",
|
|
|
"subject_id": " 科目 ID_2_ 语文 ",
|
|
|
"chapter_id": " 章节 ID_chapter_2",
|
|
|
"question_id": " 题目 ID_100",
|
|
|
"score": 2,
|
|
|
"answer_time": "2019-09-11 12:44:01",
|
|
|
"ts": "Sep 11, 2019 12:44:01 PM"
|
|
|
}
|
然后,基于上述实时流入的数据,需要实现如下的分析任务:
- 实时统计每个题目被作答频次
- 按照年级实时统计题目被作答频次
- 按照科目实时统计每个科目下题目的作答频次
1.2 技术方案选型
针对上述几个需求点,设计了如下的方案。首先会将数据实时发送到 Kafka 中,然后再通过实时计算框架从 Kafka 中读取数据,并进行分析计算,最后将计算结果重新输出到 Kafka 另外的主题中,以方便下游框架使用聚合好的结果。
下游框架从 Kafka 中拿到聚合好的数据,并实时录入到 OLTP 的业务库中(例如:MySQL、UDW、HBase、ES 等),以便于接口将想要的结果实时反馈给前端。
中间的实时计算框架,则在 Flink 和 Spark 中选择。2018 年 08 月 08 日,Flink 1.6.0 推出,支持状态过期管理(FLINK-9510, FLINK-9938)、支持 RocksDB、在 SQL 客户端中支持 UDXF 函数,大大加强了 SQL 处理功能,同时还支持 DML 语句、支持基于多种时间类型的事件处理、Kafka Table Sink 等功能。随后推出的 Flink 1.6.x 系列版本中,进行了大量优化。这些使得 Flink 成为一个很好的选择。
早先 Spark 要解决此类需求,是通过 Spark Streaming 组件实现。为此需要先生成 RDD,然后通过 RDD 算子进行分析,或者将 RDD 转换为 DataSet\DataFrame、创建临时视图,并通过 SQL 语法或者 DSL 语法进行分析。相比之下显得不够便捷和高效。后来 Spark 2.0.0 新增了 Structured Streaming 组件,具有了更快的流式处理能力,可达到和 Flink 接近的效果。
架构如下图所示:
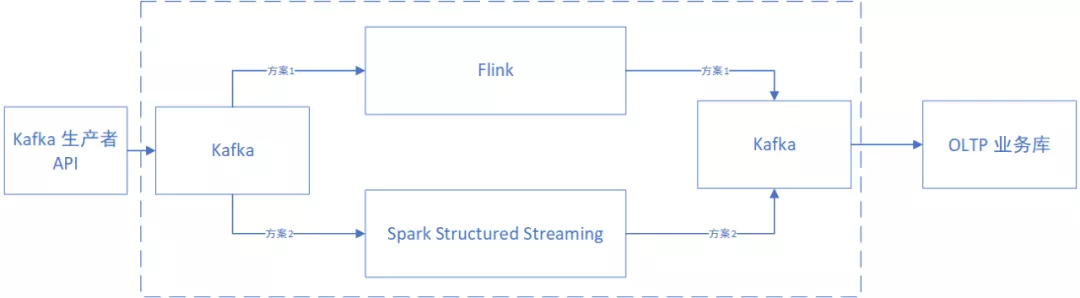
本篇将省略下游框架的操作,重点介绍 Flink 框架进行任务计算的过程(虚线框中的内容),并简述 Spark 的实现方法,便于读者理解其异同。
1.3 实时计算在学情分析系统中的具体实现
1.3.1 Flink 实践方案
1. 发送数据到 Kafka
后台服务通过 Flume 或后台接口触发的方式调用 Kafka 生产者 API,实时将数据发送到 Kafka 指定主题中。
例如发送数据如下所示:
|
{"student_id":" 学生 ID_16","textbook_id":" 教材 ID_1","grade_id":" 年级 ID_1","subject_id":" 科目 ID_2_ 语文 ","chapter_id":" 章节 ID_chapter_2","question_id":" 题目 ID_100","score":2,"answer_time":"2019-09-11 12:44:01","ts":"Sep 11, 2019 12:44:01 PM"}
|
|
|
………
|
提示:此处暂且忽略在 Kafka 集群中创建 Topic 的操作。
2. 编写 Flink 任务分析代码
使用 Flink 处理上述需求,需要将实时数据转换为 DataStream 实例,并通过 DataStream 算子进行任务分析,另外,如果想使用 SQL 语法或者 DSL 语法进行任务分析,则需要将 DataStream 转换为 Table 实例,并注册临时视图。
(1)构建 Flink env
env(StreamExecutionEnvironment) 是 Flink 当前上下文对象,用于后续生成 DataStream。代码如下所示:
|
val env = StreamExecutionEnvironment.getExecutionEnvironment
|
|
|
env.setParallelism(3)
|
(2)从 Kafka 读取答题数据
在 Flink 中读取 Kafka 数据需要指定 KafkaSource,代码如下所示:
|
val props = new Properties()
|
|
|
props.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
|
|
|
props.setProperty("group.id", "group_consumer_learning_test01")
|
|
|
val flinkKafkaSource = new FlinkKafkaConsumer011 String , props)
|
|
|
val eventStream = env.addSource String
|
(3)进行 JSON 解析
这里通过 map 算子实现 JSON 解析,代码示例如下:
|
val answerDS = eventStream.map(s => {
|
|
|
val gson = new Gson()
|
|
|
val answer = gson.fromJson(s, classOf[Answer])
|
|
|
answer
|
|
|
})
|
(4)注册临时视图
创建临时视图的目的,是为了在稍后可以基于 SQL 语法来进行数据分析,降低开发工作量。需要先获取 TableEnv 实例,再将 DataStream 实例转换为 Table 实例,最后将其注册为临时视图。代码如下所示:
|
val tableEnv = StreamTableEnvironment.create(env)
|
|
|
val table = tableEnv.fromDataStream(answerDS)
|
|
|
tableEnv.registerTable("t_answer", table)
|
(5)进行任务分析
接下来,便可以通过 SQL 语句来进行数据分析任务了,3 个需求对应的分析代码如下所示:
|
// 实时:统计题目被作答频次
|
|
|
|
|
|
"""SELECT
|
|
|
| question_id, COUNT(1) AS frequency
|
|
|
|FROM
|
|
|
| t_answer
|
|
|
|GROUP BY
|
|
|
| question_id
|
|
|
""".stripMargin)
|
|
|
// 实时:按照年级统计每个题目被作答的频次
|
|
|
|
|
|
"""SELECT
|
|
|
| grade_id, COUNT(1) AS frequency
|
|
|
|FROM
|
|
|
| t_answer
|
|
|
|GROUP BY
|
|
|
| grade_id
|
|
|
""".stripMargin)
|
|
|
// 实时:统计不同科目下,每个题目被作答的频次
|
|
|
|
|
|
"""SELECT
|
|
|
| subject_id, question_id, COUNT(1) AS frequency
|
|
|
|FROM
|
|
|
| t_answer
|
|
|
|GROUP BY
|
|
|
| subject_id, question_id
|
|
|
""".stripMargin)
|
此时得到的 result1、result2、result3 均为 Table 实例。
(6)实时输出分析结果
接下来,将不同需求的统计结果分别输出到不同的 Kafka 主题中即可。
在 Flink 中,输出数据之前,需要先将 Table 实例转换为 DataStream 实例,然后通过 addSink 算子添加 KafkaSink 即可。
因为涉及到聚合操作,Table 实例需要通过 RetractStream 来转换为 DataStream 实例。
该部分代码如下所示:
|
tableEnv.toRetractStream Result1
|
|
|
.filter(_._1)
|
|
|
.map(_._2)
|
|
|
.map(new Gson().toJson(_))
|
|
|
.addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092",
|
|
|
"test_topic_learning_2",
|
|
|
new SimpleStringSchema()))
|
|
|
tableEnv.toRetractStream Result2
|
|
|
.filter(_._1)
|
|
|
.map(_._2)
|
|
|
.map(new Gson().toJson(_))
|
|
|
.addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092",
|
|
|
"test_topic_learning_3",
|
|
|
new SimpleStringSchema()))
|
|
|
tableEnv.toRetractStream Result3
|
|
|
.filter(_._1)
|
|
|
.map(_._2)
|
|
|
.map(new Gson().toJson(_))
|
|
|
.addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092",
|
|
|
"test_topic_learning_4",
|
|
|
new SimpleStringSchema()))
|
(7)执行分析计划
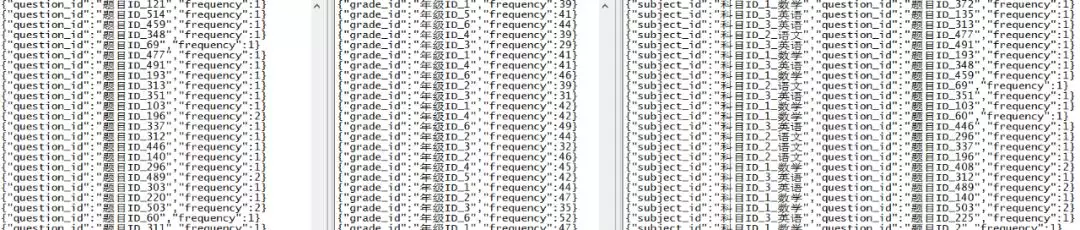
Flink 支持多流任务同时运行,执行分析计划代码如下所示:
|
env.execute("Flink StreamingAnalysis")
|
至此,编译并运行项目后,即可看到实时的统计结果,如下图所示,从左至右的 3 个窗体中,分别代表对应需求的输出结果。