深度学习(三)——Transforms的使用
 有关Transforms使用的简介
有关Transforms使用的简介
一、Transforms的结构及用法
- 导入transforms
from torchvision import transforms
- 作用:图片输入transforms后,可以得到一些预期的变换
1. Transforms的python用法
写在前面:tensor数据类型
通过transforms.ToTensor去说明两个问题:第一,transforms该如何使用;第二,Tensor数据类型相较于普通数据类型有什么区别,为什么需要tensor这个数据类型。
(1)将PIL或numpy.ndarray类型的图片转化为tensor数据类型
具体方法:transforms.Totensor()
from torchvision import transforms
tensor_trans=transforms.ToTensor() #创建transforms.ToTensor()工具
tensor_img=tensor_trans(pic) #pic为要转化为tensor类的PIL或numpy.ndarray类型的图像数据
举例:
from torchvision import transforms
from PIL import Image
#读入图像如果读取绝对路径要把\改为\\,如果读取相对路径,则没有这样的困扰
img_path="E:\\Desktop\\hymenoptera_data\\hymenoptera_data\\train\\ants\\0013035.jpg" #图片路径
img=Image.open(img_path)
print(img)
#将PIL类型图片转化为tensor类型的图片
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)
print(tensor_img)
#将numpy.ndarray类型的图片转化为tensor类型
import cv2
cv_img=cv2.imread(img_path) #将图片转化为ndarray数据
tensor_cv_img=tensor_trans(cv_img)
print(tensor_cv_img)
补充:如何读取tensor类型的图片数据
- 方法:同样是上一篇提到的SummaryWriter中的add_image函数。下面是一个代码实例。
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
writer.add_image("Tensor_img",tensor_img)
writer.close()
(2)为什么需要tensor数据类型?
- tensor数据类型内部包含了神经网络理论基础需要的一些参数
二、常见的Transforms
| 功能 | 数据类型 | 对应函数 |
|---|---|---|
| 输入 | PIL | Image.open() |
| 输出 | tensor | Totensor() |
| 作用 | narrays | cv.imread() |
1. Compose类详解
- 主要作用:将不同的transforms结合到一起,比如让不同类型的数据先经过一个中心裁剪,再合成一个tensor类型的数据
(1)关于Compose类中__call__函数的一些说明
随便写个类举例子:
class Person:
def __call__(self, name):
print("__call__ "+"Hello "+name)
def hello(self,name):
print("hello "+name)
person=Person()
person("zhangsan") #[Run] __call__ Hello zhangsan
person.hello("lisi") #[Run] hello lisi
总结:
-
像def __call__这样的函数是不需要用”.函数名“这样的方式去调用的,可以直接使用”对象名(参数)“这样的方法去调用
-
但def hello这样的函数需要用”对象名.函数(参数)“的形式调用
(2)Compose调用例子
from torchvision import transforms
img=transforms.compose([transforms.CenterCrop(10),transforms.ToTensor()])
2. ToTensor类详解
- 上面有提到,Totensor的主要作用为将图像数据转化为tensor类型
(1)ToTensor输入数据类型
只支持输入以下两类的数据:
-
PIL类型的图像数据
-
numpy.ndarray类型的图像数据
(2)Totensor的使用
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img=Image.open("E:\\Desktop\\hymenoptera_data\\hymenoptera_data\\train\\ants\\0013035.jpg") #读取图片
writer=SummaryWriter("logs")
#Totensor的使用
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img) #将PIL类型的图片转化为tensor类型
writer.add_image("ToTensor",img_tensor) #将tensor数据类型的图像可视化
writer.close()
3. ToPILImage类详解
-
主要作用:将tensor类型的图像数据转化为PIL类型
-
支持两种类型数据的输入:tensor、numpy.ndarray
-
返回:一个PIL的Image
4. Normalize类详解
-
主要作用:归一化tensor Image,并输入该组图像的均值或标准差,进行归一化处理
-
归一化公式:
\[input(channel)=\frac{input(channel)-mean(channel)}{std(channel)} \]
(1)Normalize输入图像数据类型
- 必须为tensor类型
(2)Normalize的使用
from PIL import Image
from torchvision import transforms
img=Image.open("E:\\Desktop\\hymenoptera_data\\hymenoptera_data\\train\\ants\\0013035.jpg") #读取图片
#Normalize的使用
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #设置mean和std,因为是三通道数据,所以输入维度有3维
img_norm=trans_norm(img_tensor) #标准化tensor图像数据类型
writer.add_image("Normalize",img_norm) #将标准化后的图像可视化
writer.close()
可以对比原来的图片(下)和标准化后的图片(上):颜色都变了诶!
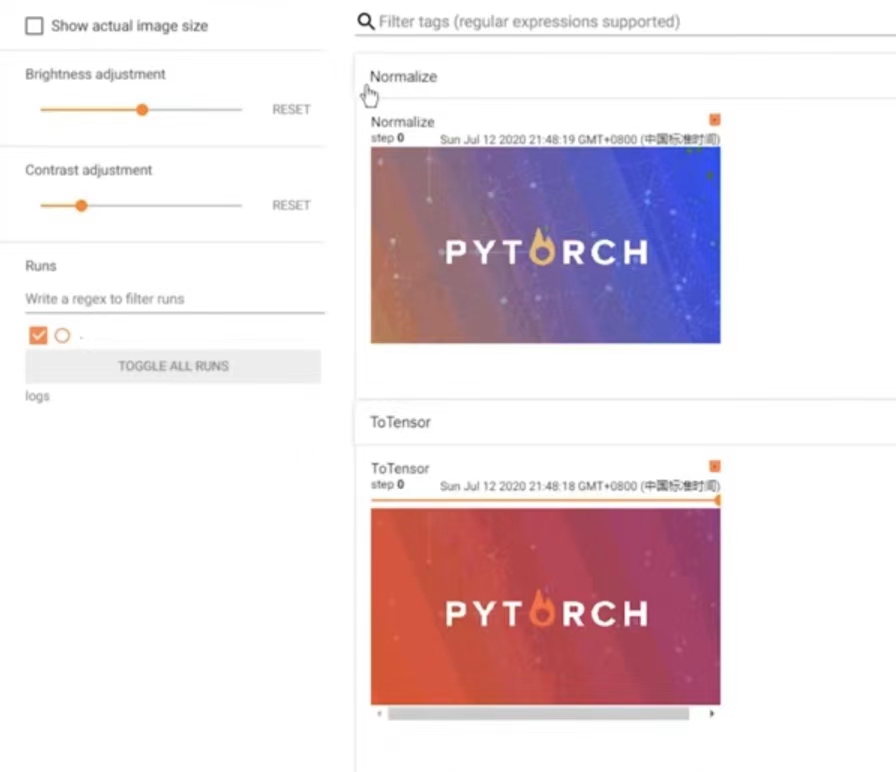
从代码上看不出啥东西,所以这里从标准化计算公式的角度去解释:
-
代码中设定的均值mean和标准差std都是0.5,那么有:
\[\frac{input-0.5}{0.5}=2×input-1 \] -
这条公式的意义在于:假如\(input\)图片像素值在\([0,1]\)这个范围内,那么标准化后会变成\([-1,1]\)这样一个范围内的图像数据
-
用下面的代码验证这条公式:
print(img_tensor[0][0][0]) #[Run] tensor(0.8275)
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #设置mean和std,因为是三通道数据,所以输入维度有3维
img_norm=trans_norm(img_tensor) #标准化tensor图像数据类型
print(img_norm[0][0][0]) #[Run] tensor(0.6549) 0.6549=2*0.8275-1
- 可以看出:\(input=0.8275, mean=0.5, std=0.5\),输出的结果恰好是\(2×0.8275=0.6549\)
5. Resize类详解
- 主要作用:输入PIL Image的时候,给定它的size;并输出根据size缩放的PIL图像数据
(1)Resize输入的数据类型
-
只能输入PIL类型的数据,并给定它的size
-
关于size的输入方式:
-
(h, w):输入数组(h,w)时,h为图像的高;w为图像的宽
-
int:输入一个整数时,图像最小的边将会匹配这个整数,另一条边会进行等比缩放
-
(2)Resize的使用
①将PIL图片缩放到指定尺寸
from PIL import Image
from torchvision import transforms
img=Image.open("E:\\Desktop\\hymenoptera_data\\hymenoptera_data\\train\\ants\\0013035.jpg") #读取图片
#Resize的使用——将图片缩放到指定尺寸
print(img.size) #size=3200×1800
trans_resize=transforms.Resize((512,512)) #将图片的size变为512×512
img_resize=trans_resize(img) #注意img的数据格式是PIL
print(img_resize) #size=512×512; type: PIL
- 将结果进行可视化时需要注意,\(img\_resize\)属于\(PIL\)格式的数据,需要转化为\(tensor\)格式的数据类型,才能使用\(add\_image\)。具体如下
trans_totensor=transforms.ToTensor()
img_resizeToTensor=trans_totensor(img_resize) #将PIL类型的图像数据转为tensor型
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
writer.add_image("Resize",img_resizeToTensor) #将tensor数据类型的图像可视化
writer.close()
②将PIL图片等比缩放(最小边=int,另一条边等比缩放)
-
这里需要使用Compose类去辅助
-
Compose() 用法:
-
Compose() 中的参数需要一个列表
-
并且列表中的数据类型为transforms类型
-
所以得到:\(Compose([transforms参数1,transforms参数2, \dots])\)
-
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transfor
img=Image.open("E:\\Desktop\\hymenoptera_data\\hymenoptera_data\\train\\ants\\0013035.jpg") #读取图片
writer=SummaryWriter("logs")
trans_totensor=transforms.ToTensor()
#Compose--resize的第2种用法
#输入一个序列,输出等比缩放比例的图片
trans_resize2=transforms.Resize(512)
trans_compose=transforms.Compose([trans_resize2,trans_totensor]) #让图像数据先经过Resize的处理,再转化为tensor格式
img_resize2=trans_compose(img) #在Compose中的这两个函数都需要输入PIL的数据类型。所以这里是先输入PIL图像进行缩放,再转换为tensor数据
writer.add_image("Resize2",resize2) #将tensor数据类型的图像可视化
writer.close()
补充:\(Compose\)的运行逻辑
-
Compose输入列表中,前面函数的输出,就是后面函数的输入。最后一个函数的输出,就是Compose函数的返回值
-
比如说上面的
transforms.Compose([trans_resize2,trans_totensor]),运行逻辑为:首先向Compose函数输入一个PIL类型的图像数据 --> PIL数据被传入Resize函数中进行处理 --> Resize将处理完的PIL数据输入ToTensor函数中 --> ToTensor函数将PIL数据转换为tensor类型输出 --> Compose函数返回处理完后的tensor数据 -
也就是说,Compose中调用的transform函数先后顺序,一定要跟数据类型一一对应。比如说,上面的Resize函数输出的是PIL类型数据,后一个ToTensor函数刚好能接受PIL类型数据的输入。如果Resize后面的函数只能接受tensor类型的数据,那寄...
6. RandomCrop类详解
-
主要作用:随机裁剪图像;Crop the given PIL Image at a random location
-
对随机的理解:根据指定的size,随机裁剪掉图像的某个区域,使裁剪后的图像在size的范围内
-
Resize的主要作用是缩放,RandomCrop的主要作用是裁剪。
(1)输入参数
拆开class RandomCrop,可以看到:
def __init__(self, size, padding=None, pad_if_need=False, fill=0, padding_mode='constant')
这里很多参数都有默认值,所以只介绍参数size的输入:
-
\(size\)可以输入一个序列,格式跟\(Resize\)一样:(h,w)
-
\(size\)还可以输入一个整数\(int\),区别于\(Resize\),这里会输出一个size为int×int的正方形图像
此外,\(RandomCrop\)需要输入一个格式为PIL类型的图像
(2)RandomCrop的用法
- 随机裁剪为正方形:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transfor
img=Image.open("E:\\Desktop\\hymenoptera_data\\hymenoptera_data\\train\\ants\\0013035.jpg") #读取图片
writer=SummaryWriter("logs")
#RandomCrop的用法(裁剪为正方形)
trans_random=transforms.RandomCrop(512) #将图像随机裁剪为size=512×512尺寸的正方形
trans_compose2=transforms.Compose([trans_random,trans_totensor]) #先裁剪PIL图像,再转换为tensor类型数据
for i in range(10): #随机裁剪10次图像
img_crop=trans_compose2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
- 随机裁剪为指定size:只需要更改下面这条代码
#RandomCrop的用法(裁剪为指定size)
trans_random=transforms.RandomCrop((512,1200)) #将图像随机裁剪为size=512×1200尺寸的正方形
三、总结
-
关注函数的输入、输出的数据类型
-
多看官方文档,比网上文档准确得多
-
关注方法需要什么参数。关注每个函数的
__init__,比如def __init__(self,padding,fill=0,padding_mode='constant'),一般情况下,需要输入的参数为\(padding\),其他参数使用默认值即可。这时候还需要了解一下\(padding\)的作用及输入的数据类型。 -
不知道输出数据类型的时候,可以用\(type()\)函数去查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号