8_集合框架
概述
1、集合的概念
概念:对象的容器,定义了多个对象进行操作的常用方法。可实现数组的功能。
和数组的区别:
- 数组长度固定,集合长度不固定
- 数组可以存储基本类型和引用类型,集合只能存储引用类型
位置:java.util.*;
2、Collection 体系集合
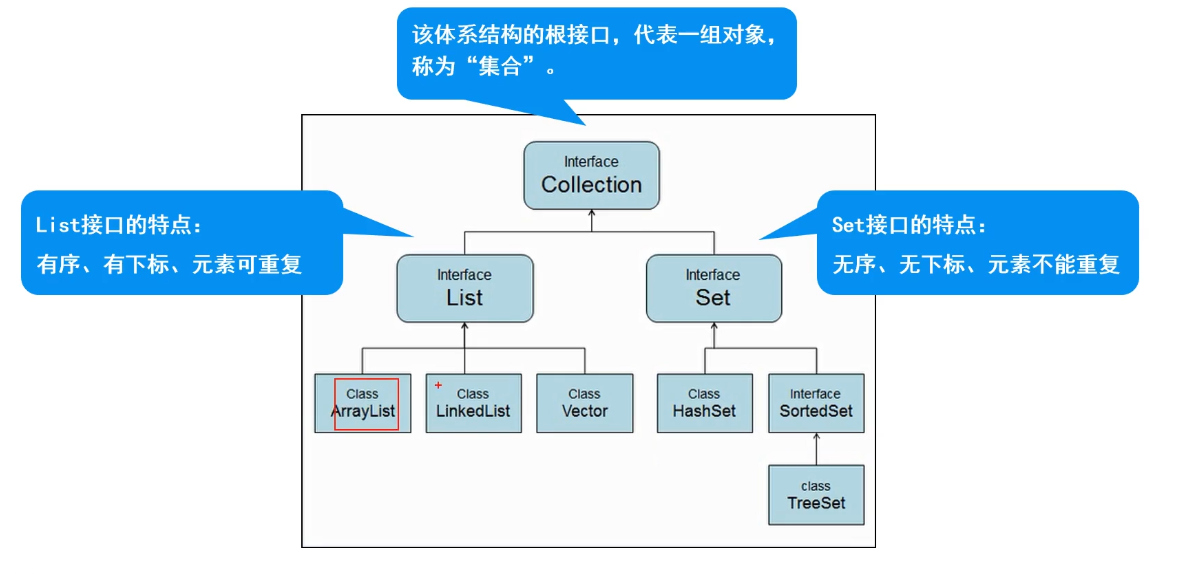
Collection 接口
Collection 父接口:
- 特点:代表一组任意类型的对象,无序,无下标,不能重复。
- 方法:
boolean add(Object obj)// 添加一个对象boolean addAll(Connection c)// 将一个集合中所有对象添加到此集合中void clear()// 清空此集合中的所有对象boolean contains(Object o)// 判断此集合中是否包含 o 对象boolean equals(Object o)// 比较两个集合boolean isEmpty()// 判断此集合是否为空boolean remove(Object o )// 在此集合中移除 o 对象int size()// 返回此集合中的元素个数Object[] toArray()// 将此集合转换成数组
1、Collection 接口使用
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
* Collection 接口的使用 保存字符串
* (1)添加元素
* (2)删除元素
* (3)遍历元素
* (4)判断
* */
public class Demo01 {
public static void main(String[] args) {
// 创建一个集合
Collection collection = new ArrayList();
//(1)添加元素
collection.add("西瓜");
collection.add("榴莲");
collection.add("苹果");
System.out.println("元素个数:" + collection.size() );
System.out.println(collection);
/* 结果:
元素个数:3
[西瓜, 榴莲, 苹果]
*/
//(2)删除元素
/* collection.remove("榴莲");
System.out.println("删除之后:" + collection);
// 清空此集合中的所有对象
collection.clear();
System.out.println("清理之后:" + collection + "\t" + "元素个数" + collection.size());*/
//(3)遍历元素【重点】 不使用 for 是因为没有下标
// 3.1 使用 forEach
System.out.println("=======3.1============");
for (Object o : collection) {
System.out.println(o);
}
// 3.2 使用迭代器 (迭代器是专门用来遍历集合的一种方式)
// hasNext() 有没有下一个元素
// next() 获取下一个元素
// remove() 删除当前元素
System.out.println("=======3.2===============");
Iterator it = collection.iterator();
while (it.hasNext()){
Object next = it.next();
System.out.println(next);
//String next = (String) it.next();
// System.out.println(next);
it.remove();
}
System.out.println("元素数量:" +collection.size() );
//(4)判断
System.out.println(collection.contains("西瓜"));
System.out.println(collection.isEmpty());
}
}
结果:
/*
* Collection 的使用:用来保存学生信息 保存对象
*
* */
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo02 {
public static void main(String[] args) {
// 新建 Collection 对象
Collection collection = new ArrayList();
Student s1 = new Student("张三",20);
Student s2 = new Student("王德发",20);
Student s3 = new Student("苗毅",20);
// 1 添加数据
collection.add(s1);
collection.add(s2);
collection.add(s3);
System.out.println("元素个数:" + collection.size());
System.out.println(collection.toString());
/* 元素个数:3
[Student{name='张三', age=20}, Student{name='王德发', age=20}, Student{name='苗毅', age=20}]*/
// 2 删除
// collection.remove(s1);
// collection.clear();
// System.out.println("删除之后:"+collection.size());
// 3 遍历
// 3.1 forEach
System.out.println("====forEach======");
for (Object o : collection) {
System.out.println(o);
}
/* ====forEach======
Student{name='张三', age=20}
Student{name='王德发', age=20}
Student{name='苗毅', age=20}*/
// 3.2 迭代器 :hasNext(),next(),remove(); 迭代过程中不能使用,collection 的删除方法
System.out.println("====Iterator======");
Iterator it = collection.iterator();
while (it.hasNext()){
Student s = (Student) it.next();
System.out.println(s);
}
/* ====Iterator======
Student{name='张三', age=20}
Student{name='王德发', age=20}
Student{name='苗毅', age=20}*/
// 4. 判断
System.out.println(collection.contains(s1));
// true
}
}
【注意】 用 迭代器遍历的时候,不能用 collection 的删除方法
小问题:collection 的 toString 是哪里的?
System.out.println(collection.toString());
这里建立了一个实体类,并重写了,toString 方法。
这里的collection 添加了3个对象,输出集合调用的 toString,是哪里的toString?
解答:
我们知道输出一个对象,实质上就是调用对象的toString() 方法,既
System.out.println(obj); // 调用obj.toString()
具体jdk是如何实现的呢 请跟我一步一步探个究竟:
找到System.out.println()的源码:
public void print(Object obj) {
write(String.valueOf(obj));
}
调用了String.valueOf(); 继续查看源码:
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
关键部分看到了,如果对象不为空,就取对象的 toString 方法。
collection本身是没有toString(), 但ArrayList实现了 toString()方法.而这个toString 也同样有这样的代码。 return (obj == null) ? "null" : obj.toString();
List 接口和实现类
特点: 有序、有下标、元素可以重复
(又称为有序的 collection) 此接口的用户可以对列表中的每个元素的插入位置进行精确的控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素
方法:
void add(int index,Object o)// 在 index 位置插入对象 oboolean addAll(int index,Collection c )// 将一个集合中的元素添加到此集合中的 index 位置Object get(int index)// 返回集合中指定位置的元素List subList(int fromIndex, int toIndex)// 返回 fromIndex 和 toIndex 之间的集合元素。
1、list 接口使用
代码实现:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
/*
* Lsit 子接口的使用: 保存字符串数据
* 特点: 有序,有下标,可重复
*
* */
public class Demo03 {
public static void main(String[] args) {
// 先创建集合对象
List list = new ArrayList<>();
// 1. 添加元素
list.add("苹果");
list.add("小米");
list.add(0, "华为");
System.out.println("元素个数:" + list.size());
System.out.println(list);
/* 元素个数:3
[华为, 苹果, 小米]*/
// 2.删除元素
list.remove(0);
System.out.println("元素个数:" + list.size());
System.out.println(list);
/*
元素个数:2
[苹果, 小米]
* */
// 3. 遍历
// 3.1 使用 for 来进行遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
/*苹果
小米 */
// 3.2 使用 forEach
System.out.println("========使用forEach==========");
for (Object o : list) {
System.out.println(o);
}
// 3.3 使用迭代器
System.out.println("=========使用 Iterator===========");
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
/*========使用forEach==========
苹果
小米
=========使用 Iterator===========
苹果
小米
*/
// 3.4 使用列表迭代器 和 Iterator 的区别,ListIterator 可以向前或向后遍历、添加、删除、修改元素
ListIterator lit = list.listIterator();
System.out.println("======3.4 使用列表迭代器从前往后==========");
while (lit.hasNext()) {
System.out.println(lit.nextIndex() + ":" + lit.next());
}
System.out.println("======3.4 使用列表迭代器从后往前==========");
while (lit.hasPrevious()) {
System.out.println(lit.previousIndex() + ":" + lit.previous());
}
// 4.判断
System.out.println(list.contains("苹果"));
System.out.println(list.isEmpty());
// 5. 获取位置 即下标
System.out.println(list.indexOf("小米"));
// 6. 替换元素
list.set(1,"老王");
for (Object o : list) {
System.out.println(o);
}
}
}
import java.util.ArrayList;
import java.util.List;
/*list 的使用: 保存数字数据*/
public class Demo04 {
public static void main(String[] args) {
// 创建集合
List list = new ArrayList<>();
// 1 添加数字数据(自动装箱)
// 这里隐含一个操作,集合是对象的容器,不能存放基本数据类型,实际上这里的数字已经不是基本数据类型,包含了一个基本数据类型,包装类的数字
list.add(20);
list.add(30);
list.add(40);
list.add(50);
list.add(60);
System.out.println("元素个数:" + list.size());
System.out.println(list);
/*元素个数:5
[20, 30, 40, 50, 60]*/
// 2. 删除操作
// list.remove(20); // remove(int index) 是根据下标来删除的 ,这里要注意数组下标越界
list.remove(new Integer(20)); // 这里包装类的 equals 方法被重写,默认比较两边的值是否相等
System.out.println("删除之后的:" + list);
/*删除之后的:[30, 40, 50, 60] */
// 3 补充方法 subList :返回子集合 索引之间的对象
List list1 = list.subList(0, 2);
System.out.println(list1);
}
/* [30, 40] */
}
2、List 实现类
ArrayList【重点】【常用】:
- 数组结构实现,查询块,增删慢;
- JDK1.2 版本,运行效率块,线程不安全
LinkedList 【常用】
- 链表结构实现,增删快,查询慢
**Vector 【不常用】: ** 和 ArrayList 很像,(用的不多了,但是要知道)
- 数组结构实现,查询块,增删慢;
- JDK1.0 版本,运行效率慢、线程安全。(因为它线程安全,所以它要比 ArrayList 要快一点)
ArrayList 使用
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
/*ArrayList 的使用:
* 特点:有序,有下标,可重复
* 存储结构:数组,查找遍历速度快,增删慢
* */
public class Demo05 {
public static void main(String[] args) {
// 创建一个集合
ArrayList arrayList = new ArrayList<>();
// 1.添加元素
Student s1 = new Student("张紫峰", 29);
Student s2 = new Student("天明", 15);
Student s3 = new Student("凌琼", 17);
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
arrayList.add(s3);
System.out.println("元素个数:" + arrayList.size());
System.out.println(arrayList);
/*元素个数:4
[Student{name='张紫峰', age=29}, Student{name='天明', age=15}, Student{name='凌琼', age=17}, Student{name='凌琼', age=17}]*/
// 2. 删除元素
// 这里显然移除的元素不是同一个对象
// arrayList.remove(new Student("天明",15));
//System.out.println(arrayList);
// 3. 遍历元素
// 3.1 使用迭代器
System.out.println("====3.1====");
Iterator it = arrayList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
/*====3.1====
Student{name='张紫峰', age=29}
Student{name='天明', age=15}
Student{name='凌琼', age=17}
Student{name='凌琼', age=17}*/
// 3.2 列表迭代器
System.out.println("========列表迭代器 --正序=======");
ListIterator lit = arrayList.listIterator();
while (lit.hasNext()) {
System.out.println(lit.next());
}
/*========列表迭代器 --正序=======
Student{name='张紫峰', age=29}
Student{name='天明', age=15}
Student{name='凌琼', age=17}
Student{name='凌琼', age=17}*/
System.out.println("=======逆序==========");
while (lit.hasPrevious()) {
System.out.println(lit.previous());
}
/*=======逆序==========
Student{name='凌琼', age=17}
Student{name='凌琼', age=17}
Student{name='天明', age=15}
Student{name='张紫峰', age=29}
*/
// 4. 判断
System.out.println(arrayList.contains(s1)); // true
System.out.println(arrayList.isEmpty()); // false
// 5. 查找
System.out.println(arrayList.indexOf(s1)); // 0
}
}
【注意】 list 存储数字类型的数据,在使用list.remove() 方法去移除指定元素,法1:通过元素下标移除,直接传入一个数字,这里要注意数组下标越界。法2 :new 一个包装类型的数据,比如:new Integer(value) 这里 remove() 里的 equals 方法是Integer 重写之后的,默认比较的是两边的值是否相等。
arrayList.remove(new Student("天明",15));
这样直接删是不行的。可以在JavaBean 中重写 equals 方法。
ArrayList 源码分析
默认容量:DEFAULT_CAPACITY = 10; 【注意】没有想集合中添加元素时,容量 是 0 ,添加任意一个元素的时候,容量就是 10。 每次扩容的大小是原来的 1.5 倍。
存放元素的数组:transient Object[] elementData
实际的元素个数:private int size;
添加元素的方法: add()
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
LinkedList 使用
package com.kang.c1;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
/*LinkedList 的使用
* 存储结构:双向链表
* */
public class Demo07 {
public static void main(String[] args) {
// 创建集合
LinkedList linkedList = new LinkedList<>();
// 添加元素
Student s1 = new Student("张安", 33);
Student s2 = new Student("檬观", 33);
Student s3 = new Student("姜命", 33);
linkedList.add(s1);
linkedList.add(s2);
linkedList.add(s3);
System.out.println("元素个数:" + linkedList.size());
System.out.println(linkedList);
// 2. 删除
// linkedList.remove(2);
// System.out.println("删除之后:"+ linkedList);
// // 清空
// linkedList.clear();
// 3. 遍历
// 3.1 for 循环
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
// 3.2 增强 for
System.out.println("====增强 for=======");
for (Object o : linkedList) {
System.out.println(o);
}
// 3.3 使用迭代器
Iterator it = linkedList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// 3.4 使用 列表迭代器:可以从前往后,也可以从后往前
ListIterator lit = linkedList.listIterator();
while (lit.hasNext()) {
System.out.println(lit.next());
}
// 4. 判断
System.out.println(linkedList.contains(s1));
System.out.println(linkedList.isEmpty());
// 5. 获取
System.out.println(linkedList.indexOf(s1));
}
}
LinkedList 源码分析
略~~~~~~~~~~
Vector 使用
package com.kang.c1;
import java.util.Enumeration;
import java.util.Vector;
/*
* 演示 Vector集合的使用
* 存储结构:数组
* */
public class Demo06 {
public static void main(String[] args) {
// 创建集合
Vector vector = new Vector<>();
// 1. 添加元素
vector.add("草莓");
vector.add("西瓜");
vector.add("蓝莓");
System.out.println(vector.size());
// 2. 删除
vector.remove(0);
vector.remove("西瓜");
vector.clear();
// 3. 遍历
// 使用枚举器
Enumeration en = vector.elements();
while (en.hasMoreElements()){
System.out.println(en.nextElement());
}
// 4. 判断
System.out.println(vector.contains("西瓜"));
System.out.println(vector.isEmpty());
// 5. vector 其它方法
// firstElement() lastElement() ElementAt()
}
}
ArrayList 和 LinkedList 的区别
ArrayList: 必须要开辟连续的空间,查询快,增删慢。
LinkedList: 无需开辟连续空间,查询慢,增删快。
泛型
1、概述
- Java 泛型是 JDK 1.5 中引入的一个新特性,其本质是参数化类型,把类型作为参数传递。
- 常见形式有,泛型类、泛型接口、泛型方法
- <T...> T 称为类型占位符,表示一种引用类型
- 好处:
- (1)提高代码的重用性
- (2)防止类型转换异常,提高代码的安全性
2、 泛型类
/*
* 泛型类:
* 语法:类名<T> 写多个的话,<T,E,K>
T 是占位符,表示一种引用类型,如果编写多个使用逗号隔开
* */
public class MyGeneric<T> {
// 使用泛型
// 1. 创建变量
T t;
// 2. 泛型作为方法的参数 , 使用的时候可以创建变量,但是不能实例化,不能new ,因为我没法保证你传过来的这个类型一定能实例化,也没法保证它一定有无参构造
public void show(T t){
System.out.println(t);
}
// 3. 泛型作为方法的返回值
public T getT(){
return t;
}
}
// 测试
public static void main(String[] args) {
// 使用泛型类创建对象
// 注意:1. 泛型只能使用引用类型,
// 2. 不同类型泛型的对象不能相互赋值,因为泛型类型不同。
MyGeneric<String> myGeneric = new MyGeneric<>(); // 后面尖括号的类型在jdk 之后就不用写了
myGeneric.t = "hello";
myGeneric.show("你好!");
System.out.println(myGeneric.getT());
MyGeneric<Integer> myGeneric1 = new MyGeneric<>();
myGeneric1.t = 100;
myGeneric1.show(200);
System.out.println(myGeneric1.getT());
}
3、泛型接口
/*
* 泛型接口
* 语法: 接口名<T>
* 注意: 不能使用泛型,来创建静态常量,因为在没有使用之前,我们不知道它的具体类型
* */
public interface MyInterface<T> {
String name = "张三";
T server(T t);
}
// 测试
public static void main(String[] args) {
// 泛型接口的使用
// 这种方式在实现接口的时候就确定泛型的类型了
MyInterfaceImpl impl = new MyInterfaceImpl();
impl.server("xxxxxxxxxx");
// 这种在实现接口的时候不确定参数的类型,在使用的时候才能确定类型
System.out.println("=====myImpl2======");
MyInterfaceImpl2<Integer> impl2 = new MyInterfaceImpl2<>();
impl2.server(10012);
}
4、泛型方法
/*
* 泛型方法
* 语法:<T> 返回值类型
* */
public class MyGenericMethod {
// 泛型方法 这个泛型只能在方法里面使用
public <T> T show(T t) {
System.out.println(t);
return t;
}
}
// 测试
public static void main(String[] args) {
// 泛型方法 它的类型是由我们传递的类型来决定的
MyGenericMethod method = new MyGenericMethod();
method.show("自由飞翔!");
method.show(200);
}
5、泛型好处
(1)提高代码的重用性,比如说:泛型方法
(2)防止类型转换异常,提高代码的重用性 在和里面说
6、泛型集合
概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
特点:
- 编译是即可检查,而非运行是抛出异常。
- 访问时,不必类型转换,(拆箱)
- 不同泛型之间引用不能相互赋值,泛型不存在多态。
package com.kang.c2;
import com.kang.c1.Student;
import java.util.ArrayList;
import java.util.Iterator;
public class Demo01 {
public static void main(String[] args) {
// 在泛型中添加类型,可以提前确定集合的类型,避免出现类型转换异常
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("xxx");
arrayList.add("yyy");
// 在确定集合之后,int 类型的数据就不能添加倒集合里面了
// arrayList.add(12);
// arrayList.add(232);
for (String s : arrayList) {
System.out.println(s);
}
//
ArrayList<Student> arrayList1 = new ArrayList<>();
Student s1 = new Student("张三",34);
Student s2 = new Student("张三",34);
Student s3 = new Student("张三",34);
arrayList1.add(s1);
arrayList1.add(s2);
arrayList1.add(s3);
Iterator<Student> it = arrayList1.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
// arrayList1 = arraylist; 这样是错误的,虽然都是ArrayList , 但是他们的泛型不一样。
}
}
Set 接口与实现类
1、set 接口使用
特点:无序,无下标,元素不可重复
方法:全部继承自 Collection 中的方法。
package com.kang.c2;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/*
* set接口的使用
* */
public class Demo02 {
public static void main(String[] args) {
// 创建集合
Set<String> set = new HashSet<>();
// 1.添加数据
set.add("小米");
set.add("华为");
set.add("苹果");
// set.add("华为"); // 这个数据没有添加进去,
System.out.println("数据个数:" + set.size());
System.out.println(set);
// 2. 删除数据
set.remove("小米");
System.out.println(set);
// 3. 遍历
// 3.1 使用增强 for
System.out.println("========增强 for=======");
for (String s : set) {
System.out.println(s);
}
// 3.2 使用迭代器
Iterator<String> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
// 4. 判断
System.out.println(set.contains("华为"));
System.out.println(set.isEmpty());
/*
* 数据个数:3
[苹果, 华为, 小米]
[苹果, 华为]
========增强 for=======
苹果
华为
苹果
华为
true
false
Process finished with exit code 0
*
* */
}
}
2、 Set 实现类
- HashSet【重点】:
- 基于
HashCode实现元素不重复,(一般要重写hashcode 和 equals 方法) - 当存入元素的哈希码相同时,会调用 equals 进行确认,如结果为 true ,则拒绝后者存入。(具体看下面实例)元素重复了,主要还是 equals 没判断到位
- 基于
- TreeSet:(二叉查找树,红黑树就是在此之上,加一些颜色,根节点必须是黑色的,为什么呢? 因为要保证平衡,不会出现,一边元素多,一边元素少的情况,导致查找效率变慢,具体的以后再说,红黑树实现起来非常复杂的)
- 基于排序顺序实现元素不重复。
- 实现
SortedSet接口,对集合元素自动排序。 - 元素对象的类型必须实现
Comparable接口,指定排序规则。 - 通过
CompareTo方法确定是否为重复元素。
1、HashSet
简单使用:
package com.kang.c2;
import java.util.HashSet;
import java.util.Iterator;
/*
* HashSet 集合的使用
* 存储结构:哈希表 JDK 1.7 (数组 + 链表) JDK 1.8 之后(数组 + 链表 + 红黑树)
* */
public class Demo03 {
public static void main(String[] args) {
// 新建一个集合
HashSet<String> hashSet = new HashSet<>();
// 1. 新建元素
hashSet.add("战三");
hashSet.add("蒋柳申");
hashSet.add("钟无艳");
// hashSet.add("钟无艳"); // 这个元素没有添加进去,因为 HashSet 是无序的
System.out.println("元素个数:" + hashSet.size());
System.out.println(hashSet);
// 2. 删除数据
// hashSet.remove("战三");
// System.out.println("删除之后:" + hashSet.size());
// 3. 遍历操作
// 3.1 增强 for
for (String s : hashSet) {
System.out.println(s);
}
// 3.2 使用迭代器
System.out.println("=======迭代器==========");
Iterator<String> it = hashSet.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
// 4. 判断
System.out.println(hashSet.contains("李云佛"));
System.out.println(hashSet.isEmpty());
/*
*
* 元素个数:3
[蒋柳申, 钟无艳, 战三]
蒋柳申
钟无艳
战三
=======迭代器==========
蒋柳申
钟无艳
战三
false
false
Process finished with exit code 0
* */
}
}
HashSet 存储过程(重复依据)
Person 类
package com.kang.c2;
import java.util.Objects;
/*
* 人类
* */
public class Person {
private String name;
private Integer age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
// @Override
// public int hashCode() {
//
// int n1 = this.name.hashCode();
// int n2 = this.age;
//
//
// return n1 + n2;
// }
//
// @Override
// public boolean equals(Object o) {
// if (this == o){
// return true;
// }
// if (o == null){
// return false;
// }
// if (o instanceof Person){
// Person p = (Person)o;
//
// if (this.name.equals(p.getName())&&this.age == p.getAge()){
// return true;
// }
// }
// return false;
// }
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name) &&
Objects.equals(age, person.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
package com.kang.c2;
import java.util.HashSet;
import java.util.Iterator;
/*
* HashSet 的使用
* 存储结构: 哈希表(数组 + 链表 + 红黑树)
* 存储过程:(重复的依据)
* (1)根据 hashcode, 计算保存的位置,如果此位置为空,则直接保存,如果不为空,则执行第二部
* (2)再执行 equals 方法,如果 equals 方法也为 true.则认为是重复。否则,形成链表
* */
public class Demo04 {
public static void main(String[] args) {
// 创建集合
HashSet<Person> persons = new HashSet<>();
// 添加数据
Person p1 = new Person("张涛", 54);
Person p2 = new Person("钟无艳", 34);
Person p3 = new Person("蒋柳申", 44);
persons.add(p1);
persons.add(p2);
persons.add(p3);
// persons.add(p3); // 重复,显然没有添加进去
/*
* 需求:现在要让集合认为它是相同元素,不添加, 解决:重写 HashCode 方法 和 equals 方法,只重写一个是不能的,
* hashcode 确定元素存储的位置,而equals 判断它能不能存
* */
persons.add(new Person("蒋柳申", 44)); // 相同元素,加入到了集合,默认,这是两个不同的对象,可以加入到集合里面
System.out.println("元素个数:" + persons.size());
System.out.println(persons);
// 2 删除操作
// persons.remove(p1);
//persons.remove(new Person("蒋柳申",44)); // 这样也是可以删掉的,删不删的掉,主要是看能不能精确的找到元素的位置,若是能找到,则可以删,若是不能精确定位,则不能删掉
// 3.遍历【重点】
// 3.1 使用增强 for
for (Person person : persons) {
System.out.println(person);
}
// 3.2 迭代器
Iterator<Person> it = persons.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
// 4. 判断
System.out.println(persons.contains(p1));
System.out.println(persons.isEmpty());
}
/*
元素个数:3
[Person{name='蒋柳申', age=44}, Person{name='张涛', age=54}, Person{name='钟无艳', age=34}]
Person{name='蒋柳申', age=44}
Person{name='张涛', age=54}
Person{name='钟无艳', age=34}
Person{name='蒋柳申', age=44}
Person{name='张涛', age=54}
Person{name='钟无艳', age=34}
true
false
Process finished with exit code 0*/
}
2、TreeSet
简单使用,存储字符串类型
package com.kang.c2;
import java.util.Iterator;
import java.util.TreeSet;
/*
* TreeSet 的使用
* 存储结构:红黑树
* */
public class Demo05 {
public static void main(String[] args) {
// 创建集合
TreeSet<String> treeSet = new TreeSet<>();
// 1. 添加元素
treeSet.add("xxx");
treeSet.add("aaa");
treeSet.add("gggg");
treeSet.add("xwer");
System.out.println("元素个数:" + treeSet.size());
System.out.println(treeSet);
// 删除
treeSet.remove("xxx");
System.out.println("删除之后:" + treeSet.size());
// 3. 遍历
// 3.1 使用增强 for
for (String s : treeSet) {
System.out.println(s);
}
// 3.2 使用迭代器
Iterator<String> it = treeSet.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
// 4.判断
System.out.println(treeSet.contains("xxx"));
}
/*元素个数:4
[aaa, gggg, xwer, xxx]
删除之后:3
aaa
gggg
xwer
aaa
gggg
xwer
false
Process finished with exit code 0
*/
}
存储复杂类型
集合中的对象比较方案:

package com.kang.c2;
import java.util.TreeSet;
/*
* 使用 TreeSet 保存数据 复杂类型
* 存储结构:红黑树
* 要求:元素必须要实现 Comparable 接口, CompareTo() 方法的返回值为 0 ,认为是重复元素,
* */
public class Demo06 {
public static void main(String[] args) {
// 创建集合
TreeSet<Person> persons = new TreeSet<>();
// 1. 添加元素
Person p1 = new Person("hello", 34);
Person p2 = new Person("江城", 34);
Person p3 = new Person("李笑笑", 34);
persons.add(p1);
persons.add(p2);
persons.add(p3);
System.out.println("元素个数:" + persons.size());
//Person cannot be cast to java.lang.Comparable TreeSet集合是基于二叉查找树实现的,左边的元素一定比右边的小,
// 但是,怎么比呢,按照什么方法比呢?对于复杂类型来说,程序不知道 这个时候就需要实现 Comaprable 接口,重写它的 compareTo()
// 2. 删除
// persons.remove(p1);
// System.out.println(persons.size());
// 3 遍历
// 3.1 使用增强 for
for (Person person : persons) {
System.out.println(persons);
}
// 3.2 迭代器
}
}
// 重写的方法
// 先按姓名来比,然后在按年龄比
@Override
public int compareTo(Person o) {
int n1 = this.getName().compareTo(o.getName());
int n2 = this.age - o.getAge();
// 如果名字一样,就比较年龄,=0,认为是重复元素,正数o1 比 o2大,负数 o1 比 o2 小。以此来判断,此元素在二叉查找树的位置,(左边还是右边)
return n1 == 0 ? n2 : n1;
*** Comparator : 实现定制比较(比较器) 通过匿名内部类的方式进行比较**
package com.kang.c2;
import java.util.Comparator;
import java.util.TreeSet;
/*
* TreeSet 集合的使用
* Comparator : 实现定制比较(比较器) 通过匿名内部类的方式进行比较
* Comparable : 可比较的
* */
public class Demo07 {
public static void main(String[] args) {
// 创建集合 并指定比较规则 通过匿名内部类的方式
TreeSet<Person> persons = new TreeSet<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
//
int n1 = o1.getAge() - o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1 == 0 ? n2 : n1;
}
});
Person p1 = new Person("hello", 32);
Person p2 = new Person("lisi ", 33);
Person p3 = new Person("zhangming", 34);
Person p4 = new Person("wangwu", 34);
persons.add(p1);
persons.add(p2);
persons.add(p3);
persons.add(p4);
System.out.println("元素个数:" + persons.size());
System.out.println(persons);
/*
* 元素个数:4
[Person{name='hello', age=32}, Person{name='lisi ', age=33}, Person{name='wangwu', age=34}, Person{name='zhangming', age=34}]*/
// 先按年龄比,相同年龄,按名字,zhangming 比 wangwu 大,在 wangwu 后面
}
}
使用 comparator 案例:
package com.kang.c2;
import java.util.Comparator;
import java.util.TreeSet;
/*
*要求: 使用 TreeSet 集合实现字符串按照长度进行排序
* hello zhang list wangwu beijin xian nanjing
* 这时候就需要定制比较规则了,需要用到 comparator
* */
public class Demo08 {
public static void main(String[] args) {
// 创建集合指定比较规则
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int n1 = o1.length()-o2.length();
int n2 = o1.compareTo(o2);
return n1 == 0 ? n2 : n1;
}
});
// 添加数据
treeSet.add("helloWorld");
treeSet.add("xian");
treeSet.add("lisi");
treeSet.add("zhangsan");
treeSet.add("wangwu");
System.out.println(treeSet);
//[lisi, xian, wangwu, zhangsan, helloWorld]
}
}
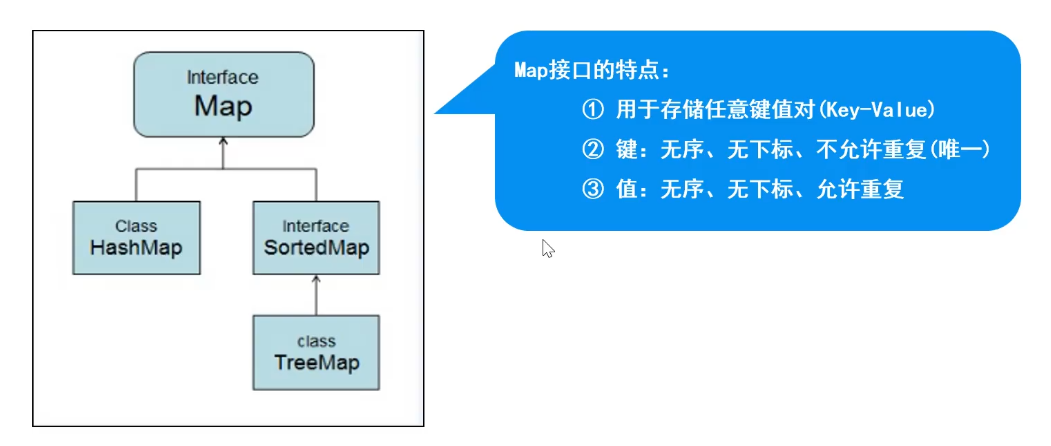
Map 接口与实现类
map 体系集合
1、map 接口使用
特点:存储一对数据(Key-Value),无序、无下标,键不可重复,值可重复
方法:
V put(K key,V value)// 将对象存入到集合中,关联键值。key 重复则覆盖原值。Object get(Object key)// 根据键获取对应的值KeySet()// 返回所有的 KeyCollection<V> values()// 返回包含所有值的 Collection 集合Set<Map.Entry<K,V>>//键值匹配的 Set 集合
案例:
package com.kang.c3;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* Map 接口的使用
* 特点:(1)存储键值对 (2)键不能重复 (3)无序
* */
public class Demo01 {
public static void main(String[] args) {
// 创建 Map 集合
Map<String, String> map = new HashMap<>();
// 1. 添加元素
map.put("cn","中国");
map.put("uk","英国");
map.put("usa","美国");
map.put("cn","zhognguo");
System.out.println(map.size());
System.out.println(map);
// 2. 删除
//map.remove("usa");
//System.out.println("删除之后:" + map.size());
// 3. 遍历
// 3.1 使用 keySet() 返回所有 key 的 set集合
// Set<String> keySet = map.keySet();
// for (String s : keySet) {
// System.out.println(s+"---"+map.get(s));
// }
// 或者写成这样
for (String s : map.keySet()) {
System.out.println(s+"---"+map.get(s));
}
// 3.2 使用 entry ,返回的是个entry 对象 ,什么是 entry ?一个entry ,就是一个键值对,映射对
System.out.println("========entry===========");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry);
System.out.println(entry.getKey() + "---" + entry.getValue());
}
// 4.判断
System.out.println(map.containsKey("cn"));
System.out.println(map.containsValue("中国"));
}
/*
*
* 3
{usa=美国, uk=英国, cn=zhognguo}
usa---美国
uk---英国
cn---zhognguo
========entry===========
usa=美国
usa---美国
uk=英国
uk---英国
cn=zhognguo
cn---zhognguo
true
false
Process finished with exit code 0
* */
}
遍历方式:
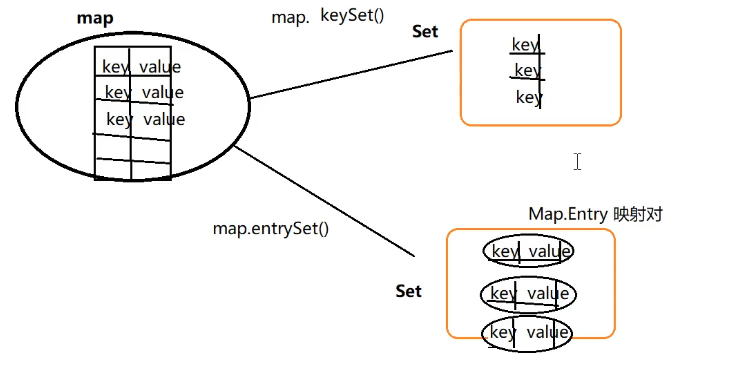
使用 entry 效率更高,步骤少一点。
2、map 集合 实现类
HashMap 【重点】
- JDK 1.2 版本,线程不安全,运行效率块;允许用 null 作为 key 或 value
HashMap()构造一个默认初始容量(16) 和默认加载因子(0.75)的空HashMap
package com.kang.c3;
import java.util.HashMap;
import java.util.Map
/*
* HashMap 集合的使用
* 存储结构:哈希表(数组 + 链表 + 红黑树)
* 使用 key hashCode 和 equals 作为重复依据,没有重写hashcode 和 equals ,所以默认的 Hashcode 就是地址,所以放的位置就不一样,equals 比较的也是地址,不一样,
* */
public class Demo02 {
public static void main(String[] args) {
// 创建集合
HashMap<Student, String> sss = new HashMap<>();
// 添加元素
Student s1 = new Student(10, "钟无艳");
Student s2 = new Student(20, "蒋柳申");
Student s3 = new Student(30, "无妄");
sss.put(s1,"北京");
sss.put(s2,"天津");
sss.put(s3,"南极");
// 使用 key hashCode 和 equals 作为重复依据,没有重写hashcode 和 equals ,所以默认的 Hashcode 就是地址,所以放的位置就不一样,equals 比较的也是地址,不一样,
sss.put(new Student(30,"无妄"),"江苏");
System.out.println("元素个数:" + sss.size());
System.out.println(sss);
// 2. 删除
// sss.remove(s3);
// System.out.println("删除之后:" + sss.size());
// 3. 遍历
// 3.1 使用keySet
System.out.println("========keySet==========");
for (Student student : sss.keySet()) {
System.out.println(student + "---" + sss.get(student));
}
// 3.2 entrySet()
System.out.println("============entrySet===========");
for (Map.Entry<Student, String> entry : sss.entrySet()) {
System.out.println(entry.getKey() + "---" + entry.getValue());
}
// 4. 判断
System.out.println(sss.containsKey(s1));
System.out.println(sss.containsValue("南极"));
}
/*元素个数:4
{Student{stuNo=20, name='蒋柳申'}=天津, Student{stuNo=30, name='无妄'}=江苏, Student{stuNo=10, name='钟无艳'}=北京, Student{stuNo=30, name='无妄'}=南极}
========keySet==========
Student{stuNo=20, name='蒋柳申'}---天津
Student{stuNo=30, name='无妄'}---江苏
Student{stuNo=10, name='钟无艳'}---北京
Student{stuNo=30, name='无妄'}---南极
============entrySet===========
Student{stuNo=20, name='蒋柳申'}---天津
Student{stuNo=30, name='无妄'}---江苏
Student{stuNo=10, name='钟无艳'}---北京
Student{stuNo=30, name='无妄'}---南极
true
true
Process finished with exit code 0
*/
}
HashMap 源码分析
Hashtable[非重点]
JDK 1.0 版本,线程安全,运行效率快;不允许用 null 作为 key 或是 value
此类实现了一个 哈希表 (数组 + 链表)
现在一般不用了,了解一下。。。^ - ^
Properties
HashTable 的子类,要求 key 和 values 都是 String,通常用于配置文件的读取,和 IO 关系很近。
TreeMap
- 实现了 SortedMap 接口,(是 Map 的子接口),可以对 key 自动排序。
package com.kang.c3;
import java.util.Map;
import java.util.TreeMap;
/*
* TreeMap 的使用
* 存储结构:红黑树
* */
@SuppressWarnings("all")
public class Demo03 {
public static void main(String[] args) {
// 新建集合(定制比较)
TreeMap<Student, String> treeMap = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int n1 = o1.compareTo(o2);
return n1;
}
});
// 1. 添加元素
Student s1 = new Student(10, "钟无艳");
Student s2 = new Student(20, "蒋柳申");
Student s3 = new Student(30, "无妄");
treeMap.put(s1,"北京");
treeMap.put(s2,"天津");
treeMap.put(s3,"南极");
System.out.println("元素个数:" + treeMap.size());
System.out.println(treeMap);
/*
* 元素个数:3
{Student{stuNo=30, name='无妄'}=南极, Student{stuNo=20, name='蒋柳申'}=天津, Student{stuNo=10, name='钟无艳'}=北京}
* */
//2. 删除
//treeMap.remove(s1);
// treeMap.remove(new Student(10,"钟无艳"),"北京"); 这样的也是可以删掉的,因为comparaTo方法比较的就是名字 定位准确,直接删
// System.out.println("元素个数:" + treeMap.size());
// System.out.println(treeMap);
/*
* 元素个数:2
{Student{stuNo=30, name='无妄'}=南极, Student{stuNo=20, name='蒋柳申'}=天津}*/
// 3 遍历
// 3.1 使用 keySet (返回 key 的 Set 集合)
System.out.println("=======keySet===========");
for (Student key : treeMap.keySet()) {
System.out.println(key + "---" +treeMap.get(key));
}
System.out.println("------------entrySet---------------");
// 3.2 entrySet
for (Map.Entry<Student, String> entry : treeMap.entrySet()) {
System.out.println(entry);
}
// 4.判断
System.out.println(treeMap.containsKey(s1));
System.out.println(treeMap.containsValue("南极"));
}
/*
*
* 元素个数:3
{Student{stuNo=30, name='无妄'}=南极, Student{stuNo=20, name='蒋柳申'}=天津, Student{stuNo=10, name='钟无艳'}=北京}
=======keySet===========
Student{stuNo=30, name='无妄'}---南极
Student{stuNo=20, name='蒋柳申'}---天津
Student{stuNo=10, name='钟无艳'}---北京
------------entrySet---------------
Student{stuNo=30, name='无妄'}=南极
Student{stuNo=20, name='蒋柳申'}=天津
Student{stuNo=10, name='钟无艳'}=北京
true
true
Process finished with exit code 0
*/
}
// 法1 :
实现 compareable 接口,重写 compareTo() 方法
@Override
public int compareTo(Student o) {
int n1 = this.name.compareTo(o.getName());
return n1;
}
// 法2: 定制比较
在代码中。。。
TreeSet 和 TreeMap 的关系
当我们 new TreeMap 的时候,把TreeMap 给NavigableMap,接口是 SortedMap 的子接口,当我们用 TreeSet 添加数据的时候,是用的是 treeMap 的key 保存的数据。
Collections 工具类
集合工具类,定义了除了存取以外的集合常用方法。
方法:
public static void reverse(List<?> list )// 反转集合中的元素public static void shuffle(List<?>) list)// 打乱元素 顺序,每次运行,顺序都不一样public static void sort(List<T> list)// 升序排序(元素类型必须实现 Comparable 接口)
package com.kang.c3;
import java.util.*;
/*
* 演示 Collection 工具类的使用
* */
public class Demo04 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(20);
list.add(5);
list.add(13);
list.add(7);
// sort 排序
System.out.println("排序之前:" + list);
Collections.sort(list);
System.out.println("排序之后:" + list);
// bniarySearch 二分查找
int i = Collections.binarySearch(list, 13);
System.out.println(i);
// copy 复制 这里 copy的不好,不好用,集合容量不一样,复制会报错,先占位,然后才能复制成功
ArrayList<Integer> dest = new ArrayList<>();
for (int k = 0; k < list.size(); k++) {
dest.add(0);
}
Collections.copy(dest, list);
System.out.println(dest);
// reverse 反转
Collections.reverse(list);
System.out.println("反转之后:" + list);
// shuffle 打乱
Collections.shuffle(list);
System.out.println("打乱之后:" + list);
// 补充: list 转数组 长度给多少都行,实际上使用的就是 Integer 这个类型
System.out.println("----list 转数组-------");
Integer[] arr = list.toArray(new Integer[0]);
System.out.println(arr.length);
System.out.println(Arrays.toString(arr));
// 数组转集合
System.out.println("----------数组转集合----------------");
String[] names = {"张三", "李四", "王五"};
List<String> list1 = Arrays.asList(names);
// 【注意】数组转成集合,这个集合是一个受限集合,不能添加和删除
// list1.add("赵柳"); // UnsupportedOperationException 不支持操作
System.out.println(list1);
// 【注意】 基本类型的数组转成集合,要将 类型修改为包装类型,否则添加进去的就是一个数组的数据了
Integer[] nums = {100, 30, 200, 400, 599};
List<Integer> list2 = Arrays.asList(nums);
System.out.println(list2);
}
/*
*
*
排序之前:[20, 5, 13, 7]
排序之后:[5, 7, 13, 20]
2
[5, 7, 13, 20]
反转之后:[20, 13, 7, 5]
打乱之后:[5, 13, 7, 20]
----list 转数组-------
4
[5, 13, 7, 20]
----------数组转集合----------------
[张三, 李四, 王五]
[100, 30, 200, 400, 599]
Process finished with exit code 0*/
}
总结
-
集合的概念:
对象的容器,和数组类似,定义了多个对象进行操作的常用方法。
-
List 集合:
有序、有下标、元素可重复。 (
ArrayList(数组)、LinkedList(链表)、Vector) -
Set 集合:
无序、无下标、元素不可重复。(
HashSet(1.7哈希表,1.7之后哈希表+红黑树)、TreeSet(红黑树,会对元素进行一个排序,所以会实现一个 Comparable 接口,其次还要个compator 比较器 定制比较规则,通过匿名内部类的方式实现)) -
Map 集合:
存储一对数据,无序,无下标,键不可重复,值可重复。(
HashMap(哈希表,重写 hashcode,equals 方法,重复依据)、HashTable(老集合,不用了)、TreeMap(红黑树)) -
Collections 工具类:
集合的工具类,定义了除了存取以外集合的常用方法
本文来自博客园,作者:走马!,转载请注明原文链接:https://www.cnblogs.com/zou-ma/p/16101657.html


· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术