

梯度回归三步走
模型训练的每个周期内我们会碰到以下固定的代码逻辑组合:
optimizer.no_grad()
loss.backward()
optimizer.step()
他们的作用分别为:
-
optimizer.no_grad(): 清空上一轮训练留下来的梯度值。
每一轮梯度训练过程中,针对模型的参数集,都会生成相应的梯度x.grad, 如果不显式清零,这些值会在后续梯度计算中累积。参考这里可以帮助理解累积过程:https://zhuanlan.zhihu.com/p/648538040 -
loss.backward():计算预测值附近的梯度值,保存到x.grad中。参考:https://zhuanlan.zhihu.com/p/648538040
具体来说,loss.backward() 的作用是对损失函数进行求导,得到每个模型参数关于损失函数的梯度。这个梯度可以表示模型参数在当前状态下对损失函数的贡献大小和方向,即参数更新的方向和大小。计算公式为:
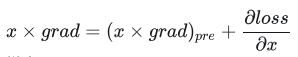
-
optimizer.step():执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。
具体来说,optimizer.step() 根据优化算法的规则,将梯度应用于网络参数。例如,常用的优化算法如 Adam、SGD 等,都有自己的更新规则,optimizer.step() 会按照相应的规则更新网络参数的值。更新后的参数将被用于下一次的前向传递计算和反向传播计算。更新公式:
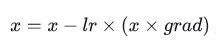


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!