MyBatis 入门(二):复杂使用
环境配置
☕️ 数据库脚本
DROP TABLE IF EXISTS `tb_user`;
CREATE TABLE `tb_user` (
`id` INT PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`username` VARCHAR(32) COMMENT '用户名',
`birthday` DATE COMMENT '生日',
`sex` CHAR(1) COMMENT '性别',
`address` VARCHAR(256) COMMENT '地址'
) COMMENT '用户表';
INSERT INTO `tb_user` VALUES(1, '小米', '1996-01-27', '男', '北京');
INSERT INTO `tb_user` VALUES(2, '小明', '1996-02-02', '女', '上海');
INSERT INTO `tb_user` VALUES(3, '小红', '1996-03-04', '女', '天津');
INSERT INTO `tb_user` VALUES(4, '小黑', '1996-04-04', '男', '广州');
INSERT INTO `tb_user` VALUES(5, '小绿', '1996-05-04', '女', '南京');
INSERT INTO `tb_user` VALUES(6, '小紫', '1996-06-04', '男', '成都');
DROP TABLE IF EXISTS `tb_order`;
CREATE TABLE `tb_order` (
`id` INT PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`time` TIMESTAMP COMMENT '下单时间',
`money` DOUBLE COMMENT '订单总价格',
`user_id` INT COMMENT '用户编号'
) COMMENT '订单表';
INSERT INTO `tb_order` VALUES(1, '2018-1-12 14:47:08', 40.0, 1);
INSERT INTO `tb_order` VALUES(2, '2018-2-12 17:41:08', 30.0, 1);
INSERT INTO `tb_order` VALUES(3, '2018-3-12 12:39:08', 20.0, 2);
DROP TABLE IF EXISTS `tb_product`;
CREATE TABLE `tb_product` (
`id` INT PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`name` VARCHAR(32) COMMENT '商品名',
`price` DOUBLE COMMENT '价格'
) COMMENT '商品表';
INSERT INTO `tb_product` VALUES(1, '商品1', 10.0);
INSERT INTO `tb_product` VALUES(2, '商品2', 20.0);
INSERT INTO `tb_product` VALUES(3, '商品3', 30.0);
DROP TABLE IF EXISTS `tb_order_product`;
CREATE TABLE `tb_order_product` (
`id` INT PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`order_id` INT COMMENT '订单编号',
`product_id` INT COMMENT '商品编号'
) COMMENT '订单和商品中间表';
INSERT INTO `tb_order_product` VALUES(1, 1, 1);
INSERT INTO `tb_order_product` VALUES(2, 1, 3);
INSERT INTO `tb_order_product` VALUES(3, 2, 3);
INSERT INTO `tb_order_product` VALUES(4, 3, 2);
☕️ 在 pom.xml 文件中添加相关依赖
<dependencies>
<!-- MyBatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.5</version>
</dependency>
<!-- MySql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- junit4 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
☕️ 编写 jdbc.properties 配置数据库连接信息
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/learning?characterEncoding=utf-8&useSSL=false&serverTimezone=Hongkong
jdbc.username=root
jdbc.password=123456
☕️ 编写 MyBatis 核心配置文件 mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration 是 MyBatis 配置文件的根标签 -->
<configuration>
<!-- 设置 -->
<settings>
<!-- 是否开启自动驼峰命名规则(camel case)映射,默认值为 false -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- 是否开启延迟加载的全局开关,默认值为 false -->
<!-- <setting name="lazyLoadingEnable" value="true"/> -->
<!-- 设置为 false 表示按需加载。默认值在 3.4.1 版本之前为 true,之后为 false -->
<!-- <setting name="aggressiveLazyLoading" value="false"/>-->
<!-- 是否开启二级缓存,默认为 true,所以不需要配置 -->
<!-- <setting name="cacheEnabled" value="true"/> -->
</settings>
<!-- 定义别名 -->
<typeAliases>
<!-- 扫描指定包,报下所有类的别名为类名(首字母大写或小写都可以)-->
<package name="com.example.entity"/>
</typeAliases>
<!-- environments 标签:配置 MyBatis 的运行环境,内部可配置多个环境
default 属性:指定要运行的那个环境的 id
-->
<environments default="development">
<!-- 配置 id 为 development 的环境 -->
<environment id="development">
<!-- 使用 JDBC 的事务管理 -->
<transactionManager type="JDBC"/>
<!-- 配置数据库连接池 -->
<dataSource type="POOLED">
<!-- 配置连接数据库的4个基本信息 -->
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!-- 配置 XML 映射文件位置 -->
<mappers>
<!-- 使用相对于 classpath 路径的资源 -->
<mapper resource=""/>
</mappers>
</configuration>
☕️ 编写 log4j.properteis 配置日志
# 配置日志的目的是在控制台输出 SQL 语句
# 将总体日志级别设置为 warn,com.example.mapper包的日志级别设置为 trace
log4j.rootCategory=warn,stdout
log4j.logger.com.example.mapper=trace
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
一对一关联查询
对于订单和用户而言,一个订单(order)只能对应着一个用户(user),也就是从查询订单信息出发关联查询用户信息为一对一查询。
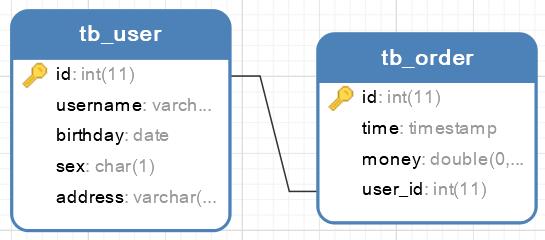
Mybatis 一般使用<resultMap>的子标签<association>处理一对一关联关系。
前期准备
⭐️ 创建订单和用户的实体类
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order implements Serializable { // 订单实体类
private Integer id; // 编号
private Date time; // 下单时间
private Double money; // 订单总价格
private User user; // 关联的用户
}
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable { // 用户实体类
private Integer id; // 编号
private String username; // 用户名
private Date birthday; // 生日
private String sex; // 性别
private String address; // 地址
}
⭐️ 创建接口 OrderMapper
package com.example.mapper;
public interface OrderMapper {
}
⭐️ 编写接口对应的 XML 映射文件 OrderMapper.xml
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.OrderMapper">
</mapper>
该映射文件位于resources/mapper目录下
⭐️ 在 mybatis-config.xml 文件中配置 XML 映射文件位置
<!-- 配置 XML 映射文件位置 -->
<mappers>
<!-- 使用相对于 classpath 路径的资源 -->
<mapper resource="mapper/OrderMapper.xml"/>
</mappers>
查询方式
查询方式可分为嵌套结果和嵌套查询两种。嵌套结果是多表联合查询,将所有需要的值一次性查询出来;嵌套查询是通过多次查询,一般为多次单表查询,最终将结果进行组合。
嵌套结果(一次查询)
✏️ 在 OrderMapper 接口中定义查询方法:
// 嵌套结果
Order selectById(Integer id);
✏️ 在 OrderMapper.xml 映射文件添加相应的 SQL 语句:
<!-- 方式一:嵌套结果 -->
<resultMap id="OrderWithUserResult" type="com.example.entity.Order">
<id property="id" column="id"/>
<result property="time" column="time"/>
<result property="money" column="money"/>
<!-- 对于 pojo 类属性,使用 <association> 标签进行映射 -->
<association property="user" javaType="com.example.entity.User">
<id property="id" column="uid"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
</association>
</resultMap>
<!-- 多表联合查询,一次性将所需要的值查询出来 -->
<select id="selectById" resultMap="OrderWithUserResult">
select o.id, o.time, o.money, o.user_id uid,
u.username, u.birthday, u.sex, u.address
from tb_order o, tb_user u
where o.user_id = u.id and o.id = #{id}
</select>
<association>标签的嵌套结果常用属性如下:
- property:对应实体类中的属性名,必填项。
- javaType: 属性对应的 Java 类型。
- resultMap:可以直接使用现有的 resultMap,而不需要在这里配置。
- columnPrefix:查询列的前缀,配置前缀后,在子标签配置 result 的 column 时可以省略前缀。
除了这些属性外,还有其他属性,此处不做介绍。
✏️ 对 selectById() 方法进行测试:
public class OrderMapperTest {
private SqlSession sqlSession;
private OrderMapper orderMapper;
@Before
public void init() throws IOException {
// 读取 MyBatis 核心配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
// 创建 SqlSessionFactory 工厂对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 关闭输入流
resourceAsStream.close();
// 使用 SqlSessionFactory 生产 SqlSession 对象
sqlSession = sqlSessionFactory.openSession();
// 使用 SqlSession 创建 Mapper 接口的代理对象
orderMapper = sqlSession.getMapper(OrderMapper.class);
}
@After
public void end() {
// 关闭资源
sqlSession.close();
}
@Test
public void selectById() {
Order order = orderMapper.selectById(1);
System.out.println(order);
}
}
==> Preparing: select o.id, o.time, o.money, o.user_id uid, u.username, u.birthday, u.sex, u.address from tb_order o, tb_user u where o.user_id = u.id and o.id = ?
==> Parameters: 1(Integer)
<== Columns: id, time, money, uid, username, birthday, sex, address
<== Row: 1, 2018-01-12 14:47:08, 40.0, 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
Order(id=1, time=Fri Jan 12 14:47:08 CST 2018, money=40.0, user=User(id=1, username=小米, birthday=Sat Jan 27 00:00:00 CST 1996, sex=男, address=北京))
像这种通过一次查询将结果映射到不同对象的方式, 称之为关联的嵌套结果映射。这种方式的好处很明显,多表联合一次性将所有需要的值查询出来,减少了数据库查询次数,减轻了数据库额压力;缺点是写很复杂的 SQL,并且当嵌套结果更复杂时,不容易一次写正确。但是也需要注意,由于要在应用服务器上将结果映射到不同的类上,因此也会增加应用服务器的压力。
嵌套结果映射也可以通过设置查询结果列别名的方式实现,不使用 resultMap:
<select id="selectById" resultType="com.example.entity.Order">
select o.id, o.time, o.money, o.user_id "user.id",
u.username "user.username",
u.birthday "user.birthday",
u.sex "user.sex",
u.address "user.address"
from tb_order o, tb_user u
where o.user_id = u.id and o.id = #{id}
</select>
需要注意,上面的user.id、user.username这类多级别名设置必须加""号。
嵌套查询(多次查询)
📚 在 OrderMapper 接口中定义查询方法:
// 嵌套查询
Order selectById2(Integer id);
📚 在 OrderMapper.xml 映射文件添加相应的 SQL 语句:
<!-- 方式二:嵌套查询 -->
<resultMap id="OrderWithUserResult2" type="com.example.entity.Order">
<id property="id" column="id"/>
<result property="time" column="time"/>
<result property="money" column="money"/>
<!-- 通过引用另一条查询 SQL 设置该 pojo 类属性 -->
<association property="user" column="user_id" select="selectUserById"/>
</resultMap>
<!-- 被引用的查询 SQL -->
<select id="selectUserById" resultType="com.example.entity.User">
select id, username, birthday, sex, address
from tb_user where id = #{id}
</select>
<!-- 多次查询,最终将结果组合 -->
<select id="selectById2" resultMap="OrderWithUserResult2">
select id, time, money, user_id
from tb_order where id = #{id}
</select>
<association>标签的嵌套查询常用的属性如下:
-
property:对应实体类中的属性名,必填项。
-
select:被引用的查询 SQL 的 id,MyBatis 会额外执行这个查询获取嵌套对象的结果。
-
column:设置嵌套查询(被引用的查询)的传入参数,该参数是主查询中列的结果。对于单个传入参数,可以直接设置;对于多个传入参数,通过
column="{prop1=col1,prop2=col2}"方式设置,在嵌套查询中使用#{prop1}、#{prop2}获取传入参数值,效果等同@param注解。 -
fetchType:数据加载方式,可选值为 lazy 和 eager,分别为延迟加载和立即加载,这个配置会覆盖全局的 lazyLoadingEnabled 配置。
📚 对 selectById2() 方法进行测试:
@Test
public void selectById2() {
Order order = orderMapper.selectById2(1);
System.out.println(order);
}
==> Preparing: select id, time, money, user_id from tb_order where id = ?
==> Parameters: 1(Integer)
<== Columns: id, time, money, user_id
<== Row: 1, 2018-01-12 14:47:08, 40.0, 1
====> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
====> Parameters: 1(Integer)
<==== Columns: id, username, birthday, sex, address
<==== Row: 1, 小米, 1996-01-27, 男, 北京
<==== Total: 1
<== Total: 1
Order(id=1, time=Fri Jan 12 14:47:08 CST 2018, money=40.0, user=User(id=1, username=小米, birthday=Sat Jan 27 00:00:00 CST 1996, sex=男, address=北京))
嵌套查询是使用简单的 SQL 通过多次查询转换为我们需要的结果,这种方式与根据业务逻辑手动执行多次 SQL 的方式类似,最后将结果组合成一个对象。
延迟加载
嵌套查询的延迟加载
对于嵌套查询而言,有时候不必每次都使用嵌套查询里的数据,例如上面的 Order 对象中的 user 属性不必每次都使用。如果查询出来并没有使用,会白白浪费一次查询,此时可以使用延迟加载。前面介绍<association>标签的属性时,介绍了 fetchType,通过该属性可以设置延迟加载,这个配置会覆盖全局的 lazyLoadingEnabled 配置,默认的全局配置是立即加载。
✌ 对嵌套查询的 resultMap 进行修改:
<resultMap id="OrderWithUserResult2" type="com.example.entity.Order">
<id property="id" column="id"/>
<result property="time" column="time"/>
<result property="money" column="money"/>
<!-- 通过引用另一条查询 SQL 设置该 pojo 类属性 -->
<association property="user" column="user_id"
select="selectUserById" fetchType="lazy"/>
</resultMap>
fetchType 可选值为 lazy 和 eager,分别为延迟加载和立即加载。这两个数据加载方式定义如下:
- 立即加载:默认的数据加载方式,执行主查询时,被关联的嵌套查询也会执行。
- 延迟加载:也叫懒加载,只有真正需要使用被关联属性的时候,才会执行被关联属性的数据加载操作。也就是说,配置了延迟加载,被关联的嵌套查询不会立即执行,只有使用到被关联属性的时候,才会执行。
✌ 对 selectById2() 方法重新测试:
@Test
public void selectById2() {
Order order = orderMapper.selectById2(1);
System.out.println("=========执行 order.getUser()============");
order.getUser();
}
==> Preparing: select id, time, money, user_id from tb_order where id = ?
==> Parameters: 1(Integer)
<== Columns: id, time, money, user_id
<== Row: 1, 2018-01-12 14:47:08, 40.0, 1
<== Total: 1
=========执行 order.getUser()============
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
很明显,selectById2() 方法时只运行了主查询的 SQL,只有使用到被关联属性时,被关联的嵌套查询 SQL 才会被执行。
全局配置
与延迟加载有关的全局配置有两个:
- lazyLoadingEnabled:开启全局的延迟加载开关;true 表示开启,false 表示关闭,默认为 false。
- aggressiveLazyLoading:用于控制具有延迟加载特性的对象的属性的加载情况;true 表示具有延迟加载特性的对象的任意调用都会导致这个对象的完整加载,fasle 表示每种属性都是按需加载,在 3.4.1 版本之前默认值为 true,之后为 false。
第二个值可能不好理解,这里举个例子说明。在 MyBatis 的核心配置文件中将 aggressiveLazyLoading 设置为 true:
<settings>
<!-- 其它配置 -->
<!-- 设置为 false 表示按需加载。默认值在 3.4.1 版本之前为 true,之后为 false -->
<setting name="aggressiveLazyLoading" value="true"/>
</settings>
再次对 selectById2() 方法进行测试:
@Test
public void selectById2() {
Order order = orderMapper.selectById2(1);
System.out.println("=========执行 order.getId()============");
order.getId();
}
==> Preparing: select id, time, money, user_id from tb_order where id = ?
==> Parameters: 1(Integer)
<== Columns: id, time, money, user_id
<== Row: 1, 2018-01-12 14:47:08, 40.0, 1
<== Total: 1
=========执行 order.getId()============
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
由上面可以看出,当 aggressiveLazyLoading 设置为 true,只要具有延迟加载特性的对象任意调用,无论该调用是否与被关联属性有关,嵌套查询的 SQL 都会被执行;而当 aggressiveLazyLoading 设置为 false,只有需要用到被关联属性时,也就是执行被关联属性的 get 方法,才会执行被关联的嵌套查询里的 SQL。
⭐️ 一般全局延迟加载配置如下:
<settings>
<!-- 其它配置 -->
<!-- 是否开启延迟加载的全局开关,默认值为 false -->
<setting name="lazyLoadingEnable" value="true"/>
<!-- 设置为 false 表示按需加载。默认值在 3.4.1 版本之前为 true,之后为 false -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
特别提醒:MyBatis 延迟加载是通过动态代理实现的,当调用配置为延迟加载的属性方法时,动态代理的操作会被触发,这些额外的操作就是通过 MyBatis 的 SqlSession 去执行嵌套 SQL 的。 由于在和某些框架集成时,SqlSession 的生命周期交给了框架来管理,因此当对象超出 SqlSession 生命周期调用时,会由于链接关闭等问题而抛出异常。在和 Spring 集成时,要确保只能在 Service 层调用延迟加载的属性。当结果从 Service 层返回至 Controller 层时,如果获取延迟加载的属性值,会因为 SqlSession 已经关闭而抛出异常。
一对多关联查询
对于用户和订单而言,一个用户(user)可以有多个订单(order),也就是从查询用户信息出发关联查询订单信息为一对多查询。
Mybatis 一般使用<resultMap>的子标签<collection>处理一对多关联关系。
前期准备
✍ 修改订单和用户的实体类
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
import java.util.List;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable { // 用户实体类
private Integer id; // 编号
private String username; // 用户名
private Date birthday; // 生日
private String sex; // 性别
private String address; // 地址
private List<Order> orderList; // 关联的订单列表
}
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order implements Serializable { // 订单实体类
private Integer id; // 编号
private Date time; // 下单时间
private Double money; // 订单总价格
}
✍ 创建接口 UserMapper
package com.example.mapper;
public interface UserMapper {
}
✍ 创建接口对应的 XML 映射文件 UserMapper.xml
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
</mapper>
该映射文件位于resources/mapper目录下。
✍ 在 mybatis-config.xml 文件中添加 XML 映射文件位置的配置
<!-- 配置 XML 映射文件位置 -->
<mappers>
<!-- 使用相对于 classpath 路径的资源 -->
<mapper resource="mapper/OrderMapper.xml"/>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
查询方式
和一对一关联方式一样,查询方式可分为嵌套结果和嵌套查询两种。
嵌套结果(一次查询)
💡 在 UserMapper 接口中定义方法:
// 嵌套结果
User selectById(Integer id);
💡 在 UserMapper.xml 映射文件中添加相应的 SQL:
<!-- 方式一:嵌套结果 -->
<resultMap id="UserWithOrderResult" type="com.example.entity.User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!-- 对于集合类属性,可以使用<collection>进行映射 -->
<collection property="orderList" ofType="com.example.entity.Order">
<id property="id" column="oid"/>
<result property="time" column="time"/>
<result property="money" column="money"/>
</collection>
</resultMap>
<!-- 多表联合查询,一次性将所需要的值查询出来 -->
<select id="selectById" resultMap="UserWithOrderResult">
select u.id, u.username, u.birthday, u.sex, u.address,
o.id oid, o.time, o.money
from tb_user u, tb_order o
where u.id = o.user_id and u.id = #{id}
</select>
<collection>和<association>大部分属性相同,但还包含一个特殊属性 ofType,用来表示实体类的集合属性所包含的数据类型。需要注意,一对多的嵌套结果方式的查询一定要设置<id>标签,它配置的是主键,MyBatis 在处理多表联合查询出来的数据,会逐条比较全部数据中<id>标签配置的字段值是否相同,相同的数据进行合并,最后映射到 resultMap 中。
💡 对 selectById() 方法进行测试:
public class UserMapperTest {
private SqlSession sqlSession;
private UserMapper userMapper;
@Before
public void init() throws IOException {
// 读取 MyBatis 核心配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
// 创建 SqlSessionFactory 工厂对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 关闭输入流
resourceAsStream.close();
// 使用 SqlSessionFactory 生产 SqlSession 对象
sqlSession = sqlSessionFactory.openSession();
// 使用 SqlSession 创建 Mapper 接口的代理对象
userMapper = sqlSession.getMapper(UserMapper.class);
}
@After
public void end() {
// 关闭资源
sqlSession.close();
}
@Test
public void selectById() {
User user = userMapper.selectById(1);
System.out.println(user);
}
}
==> Preparing: select u.id, u.username, u.birthday, u.sex, u.address, o.id oid, o.time, o.money from tb_user u, tb_order o where u.id = o.user_id and u.id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address, oid, time, money
<== Row: 1, 小米, 1996-01-27, 男, 北京, 1, 2018-01-12 14:47:08, 40.0
<== Row: 1, 小米, 1996-01-27, 男, 北京, 2, 2018-02-12 17:41:08, 30.0
<== Total: 2
User(id=1, username=小米, birthday=Sat Jan 27 00:00:00 CST 1996, sex=男, address=北京, orderList=[Order(id=1, time=Fri Jan 12 14:47:08 CST 2018, money=40.0), Order(id=2, time=Mon Feb 12 17:41:08 CST 2018, money=30.0)])
嵌套查询(多次查询)
☕️ 在 UserMapper 接口中定义方法:
// 嵌套查询
User selectById2(Integer id);
☕️ 在 UserMapper.xml 映射文件中添加相应的 SQL:
<!-- 方式二:嵌套查询 -->
<resultMap id="UserWithOrderResult2" type="com.example.entity.User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!-- 通过引用另一条查询 SQL 设置该集合类属性 -->
<collection property="orderList" column="id" select="selectOrderById"/>
</resultMap>
<!-- 被引用的查询 SQL -->
<select id="selectOrderById" resultType="com.example.entity.Order">
select id, time, money
from tb_order where user_id = #{id}
</select>
<!-- 多次查询,最终将结果组合 -->
<select id="selectById2" resultMap="UserWithOrderResult2">
select id, username, birthday, sex, address
from tb_user where id = #{id}
</select>
☕️ 对 selectById2() 方法进行测试:
@Test
public void selectById2() {
User user = userMapper.selectById2(1);
System.out.println(user);
}
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
====> Preparing: select id, time, money from tb_order where user_id = ?
====> Parameters: 1(Integer)
<==== Columns: id, time, money
<==== Row: 1, 2018-01-12 14:47:08, 40.0
<==== Row: 2, 2018-02-12 17:41:08, 30.0
<==== Total: 2
<== Total: 1
User(id=1, username=小米, birthday=Sat Jan 27 00:00:00 CST 1996, sex=男, address=北京, orderList=[Order(id=1, time=Fri Jan 12 14:47:08 CST 2018, money=40.0), Order(id=2, time=Mon Feb 12 17:41:08 CST 2018, money=30.0)])
延迟加载的方式和一对一关联查询的一样。
多对多关联查询
对于订单和商品而言,一个订单(order)可以包含多种商品(product),而一种商品(product)又可以属于多个订单(order),订单和商品就属于多对多的关联关系,多对多关系其实就是双向的一对多关系。

前期准备
⭐️ 修改订单实体类和创建商品实体类
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
import java.util.List;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order implements Serializable { // 订单实体类
private Integer id; // 编号
private Date time; // 下单时间
private Double money; // 订单总价格
private List<Product> productList; // 订单的商品列表
}
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.List;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Product implements Serializable { // 商品实体类
private Integer id; // 编号
private String name; // 商品名称
private Double price; // 商品价格
private List<Order> orderList; // 商品所属的订单列表
}
查询方式
查询方式可分为嵌套结果和嵌套查询两种。
嵌套结果(一次查询)
✏️ 在 OrderMapper 接口中定义查询方法:
// 嵌套结果
Order selectById(Integer id);
✏️ 在 OrderMapper.xml 映射文件添加相应的 SQL 语句:
<!-- 方式一:嵌套结果 -->
<resultMap id="OrderWithProductResult" type="com.example.entity.Order">
<id property="id" column="id"/>
<result property="time" column="time"/>
<result property="money" column="money"/>
<!-- 对于 pojo 类属性,使用 <association> 标签进行映射 -->
<collection property="productList" ofType="com.example.entity.Product">
<id property="id" column="pid"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
</collection>
</resultMap>
<!-- 多表联合查询,一次性将所需要的值查询出来 -->
<select id="selectById" resultMap="OrderWithProductResult">
select o.id, o.time, o.money, p.id pid, p.name, p.price
from tb_order o, tb_product p, tb_order_product op
where op.order_id = o.id and op.product_id = p.id and o.id = #{id}
</select>
✏️ 对 selectById() 方法进行测试:
public class OrderMapperTest {
private SqlSession sqlSession;
private OrderMapper orderMapper;
@Before
public void init() throws IOException {
// 读取 MyBatis 核心配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
// 创建 SqlSessionFactory 工厂对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 关闭输入流
resourceAsStream.close();
// 使用 SqlSessionFactory 生产 SqlSession 对象
sqlSession = sqlSessionFactory.openSession();
// 使用 SqlSession 创建 Mapper 接口的代理对象
orderMapper = sqlSession.getMapper(OrderMapper.class);
}
@After
public void end() {
// 关闭资源
sqlSession.close();
}
@Test
public void selectById() {
Order order = orderMapper.selectById(1);
System.out.println(order);
}
}
==> Preparing: select o.id, o.time, o.money, p.id pid, p.name, p.price from tb_order o, tb_product p, tb_order_product op where op.order_id = o.id and op.product_id = p.id and o.id = ?
==> Parameters: 1(Integer)
<== Columns: id, time, money, pid, name, price
<== Row: 1, 2018-01-12 14:47:08, 40.0, 1, 商品1, 10.0
<== Row: 1, 2018-01-12 14:47:08, 40.0, 3, 商品3, 30.0
<== Total: 2
Order(id=1, time=Fri Jan 12 14:47:08 CST 2018, money=40.0, productList=[Product(id=1, name=商品1, price=10.0, orderList=null), Product(id=3, name=商品3, price=30.0, orderList=null)])
嵌套查询(多次查询)
📚 在 OrderMapper 接口中定义查询方法:
// 嵌套查询
Order selectById2(Integer id);
📚 在 OrderMapper.xml 映射文件添加相应的 SQL 语句:
<!-- 方式二:嵌套查询 -->
<resultMap id="OrderWithUserResult2" type="com.example.entity.Order">
<id property="id" column="id"/>
<result property="time" column="time"/>
<result property="money" column="money"/>
<!-- 通过引用另一条查询 SQL 设置该 pojo 类属性 -->
<association property="productList" column="id" select="selectProductById"/>
</resultMap>
<!-- 被引用的查询 SQL -->
<select id="selectProductById" resultType="com.example.entity.Product">
select id, name, price from tb_product
where id in(select product_id from tb_order_product where order_id = #{id})
</select>
<!-- 多次查询,最终将结果组合 -->
<select id="selectById2" resultMap="OrderWithUserResult2">
select id, time, money
from tb_order where id = #{id}
</select>
📚 对 selectById2() 方法进行测试:
@Test
public void selectById2() {
Order order = orderMapper.selectById2(1);
System.out.println(order);
}
==> Preparing: select id, time, money from tb_order where id = ?
==> Parameters: 1(Integer)
<== Columns: id, time, money
<== Row: 1, 2018-01-12 14:47:08, 40.0
====> Preparing: select id, name, price from tb_product where id in(select product_id from tb_order_product where order_id = ?)
====> Parameters: 1(Integer)
<==== Columns: id, name, price
<==== Row: 1, 商品1, 10.0
<==== Row: 3, 商品3, 30.0
<==== Total: 2
<== Total: 1
Order(id=1, time=Fri Jan 12 14:47:08 CST 2018, money=40.0, productList=[Product(id=1, name=商品1, price=10.0, orderList=null), Product(id=3, name=商品3, price=30.0, orderList=null)])
延迟加载的方式和一对一关联的一样。
MyBatis 的缓存
像大多数的持久化框架一样,MyBatis 也提供了缓存策略,通过缓存策略来减少数据库的查询次数,从而提高性能。 Mybatis 中缓存分为一级缓存,二级缓存。
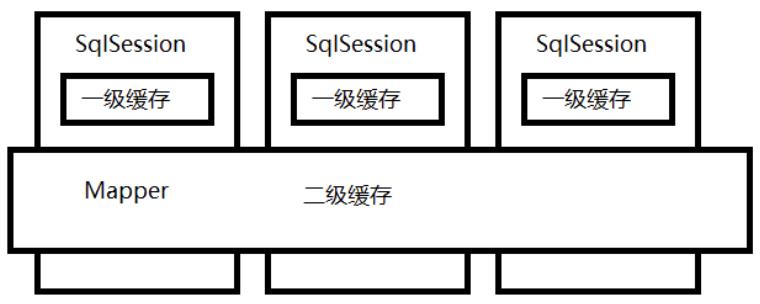
-
一级缓存:SqlSession 级别的缓存,不同的 SqlSession 之间的缓存数据区域是互相不影响的。
-
二级缓存:Mapper 级别的缓存,和 Mapper 的命名空间(namespace)绑定,是跨 SqlSession 的缓存。
下面将 User 表来介绍 MyBatis 的缓存机制:
✌ 修改 User 表的实体类:
package com.example.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable { // 用户实体类
private Integer id; // 编号
private String username; // 用户名
private Date birthday; // 生日
private String sex; // 性别
private String address; // 地址
}
✌ 在 UserMapper 中添加方法:
User selectById(Integer id);
✌ 在 UserMapper.xml 中添加相应的 SQL 语句:
<select id="selectById" resultType="com.example.entity.User">
select id, username, birthday, sex, address
from tb_user where id = #{id}
</select>
一级缓存
MyBatis 的一级缓存存在于 SqlSession 的生命周期中,在同一个 SqlSession 中查询时,MyBatis 会把执行的方法和参数通过算法生成缓存的 key,将查询结果作为 value,存入一个 Map 对象中。如果同一个 SqlSession 中执行的方法和参数完全一致,那么通过算法会生成相同的 key,当 Map 缓存对象中已经存在该 key 时,则会返回缓存中的查询结果。
✍ 在同一个 SqlSession 中执行两次 selectById() 方法
public class UserMapperTest {
private SqlSession sqlSession;
private UserMapper userMapper;
@Before
public void init() throws IOException {
// 读取 MyBatis 核心配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
// 创建 SqlSessionFactory 工厂对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 关闭输入流
resourceAsStream.close();
// 使用 SqlSessionFactory 生产 SqlSession 对象
sqlSession = sqlSessionFactory.openSession();
// 使用 SqlSession 创建 Mapper 接口的代理对象
userMapper = sqlSession.getMapper(UserMapper.class);
}
@After
public void end() {
// 关闭资源
sqlSession.close();
}
@Test
public void selectById() {
User user = userMapper.selectById(1);
User user1 = userMapper.selectById(1);
System.out.println(user == user1);
}
}
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
true
由上可知,执行两次 selectById(),只进行了一次 SQL 查询,返回的是同一个对象,这证明了一级缓存的存在。
✍ 一级缓存的清除
为了避免读脏数据,SqlSession 执行 commit 操作(执行插入、更新、删除)时,会清空 SqlSession 中的缓存。除此之外,调用 SqlSession 的 close() 和 clearCache() 方法也会清空缓存。
@Test
public void selectById() {
User user = userMapper.selectById(1);
// 执行 commit 操作
sqlSession.commit();
User user1 = userMapper.selectById(1);
System.out.println(user == user1);
}
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
false
由上可知,执行 commit 操作会清空一级缓存,所以查询操作时不要执行 commit() 方法。
✍ 不使用一级缓存
如果不想让 selectById() 方法使用一级缓存,可以对该方法对应的 SQL 做如下修改:
<select id="selectById" flushCache="true" resultType="com.example.entity.User">
select id, username, birthday, sex, address
from tb_user where id = #{id}
</select>
设置 flushCache 属性为 true 后,会在查询数据前清空当前 SqlSession 的本地缓存。
二级缓存
一级缓存是 SqlSession 范围的缓存,而二级缓存是 Mapper 映射级别的缓存,多个 SqlSession 去操作同一个 Mapper 映射的 SQL 语句,共享二级缓存 。需要注意,这里所谓的 Mapper 不是 SqlSession 创建的 Mapper 代理对象,而是同一个 namespace 下的所有 Mapper 映射。
💡 开启 MyBatis 二级缓存
二级缓存的全局开关默认是开启的,所以不需要配置。如果想要配置,在 mybatis-config.xml 中添加如下代码:
<settings>
<!-- 其它配置 -->
<!-- 是否开启二级缓存的全局开关,默认为 true,所以可以不用配置 -->
<setting name="cacheEnabled" value="true"/>
</settings>
前面也提到,二级缓存是和 Mapper 的 namespace 绑定的,意味着同一个命名空间下的所有的 SQL 操作拥有共同的缓存,也就是说每一个 namespace 的 Mapper 都有一个二级缓存区域。因此,除了要开启全局的二级缓存配置,还需要在 XML 映射文件或者 Mapper 接口中开启该 Mapper 的二级缓存:
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
<!-- 开启这个 mapper 映射的二级缓存 -->
<cache/>
</mapper>
默认的二级缓存会有如下效果:
- 映射文件中的所有 Select 语句将会被缓存;
- 映射文件中的所有 Insert、Update 和 Delete 语句将会清空缓存;
- 缓存会使用 LRU(最近最少使用的)算法来收回;
- 缓存会存储集合或对象(无论查询方法返回什么类型的值)的 1024 个引用。
💡 使用二级缓存
User selectById(Integer id);
<select id="selectById" resultType="com.example.entity.User">
select id, username, birthday, sex, address
from tb_user where id = #{id}
</select>
@Test
public void selectById() {
// 获取 sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取 UserMapper 接口
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 调用 selectById() 方法,查询 id=1 的用户
User user1 = userMapper.selectById(1);
// 对当前获取的对象重新赋值
user1.setUsername("New Name");
// 再次获取 id 相同的用户
User user2 = userMapper.selectById(1);
// 虽然没有更新数据库,但是这个用户名和 user1 重新赋值的名字相同
System.out.println(user2.getUsername().equals("New Name")); // true
// user1 和 user2 是同一个实例
System.out.println(user1 == user2); // true
// 关闭 sqlSession
sqlSession.close();
System.out.println("开启新的 SqlSession");
// 开启另一个新的 sqlSession
sqlSession = sqlSessionFactory.openSession();
// 获取 UserMapper 接口
userMapper = sqlSession.getMapper(UserMapper.class);
// 调用 selectById() 方法,查询 id=1 的用户
User user3 = userMapper.selectById(1);
// 第二个 sqlSession 获取的用户是 New Name
System.out.println(user3.getUsername().equals("New Name")); // true
// 这里获取的 user3 和前面获取的 user1 是完全不同的实例
System.out.println(user1 == user3); // false
// 再次获取 id 相同的用户
User user4 = userMapper.selectById(1);
// 这里获取的 user4 和前面的 user3 也是完全不同的实例
System.out.println(user3 == user4); // false
}
Cache Hit Ratio [com.example.mapper.UserMapper]: 0.0
==> Preparing: select id, username, birthday, sex, address from tb_user where id = ?
==> Parameters: 1(Integer)
<== Columns: id, username, birthday, sex, address
<== Row: 1, 小米, 1996-01-27, 男, 北京
<== Total: 1
Cache Hit Ratio [com.example.mapper.UserMapper]: 0.0
true
true
开启新的 SqlSession
Cache Hit Ratio [com.example.mapper.UserMapper]: 0.3333333333333333
true
false
Cache Hit Ratio [com.example.mapper.UserMapper]: 0.5
false
日志中存在好几条以 Cache Hit Ratio 开头的语句,后面输出的值为当前执行方法的二级缓存命中率。在测试第一部分中,第一次查询获取 user1 的时候由于没有缓存,所以执行了数据库查询。在第二个查询获取 user2 的时候,user2 和 user1 是完全相同的实例,使用的是一级缓存,所以返回同一个实例。
当调用 close() 方法关闭 SqlSession 时,SqlSession 才会保存查询数据到二级缓存中。在这之后二级缓存才有了缓存数据,所以可以看到第一部分两次查询时,命中率都是 0。
在第二部分测试代码中,获取 user3 时,日志中并没有输出数据库查询,而是输出了命中率,这时的命中率是 0.3333333333333333。这是第 3 次查询,并且得到了缓存的值,因此该方法一共被请求了 3 次,有 1 次命中,所以命中率就是三分之一。后面再获取 user4 的时候,就是 4 次请求,2 次命中,命中率为 0.5。并且因为可读写缓存的缘故,user3 和 user4 都是反序列化得到的结果,所以它们不是相同的实例。在这一部分,这两个实例是读写安全的,其属性不会互相影响。
💡 二级缓存分析
从上面的二级缓存使用中,我们可以总结出以下几点规律:
- 只有关闭 SqlSession 时,SqlSession 才会将查询数据(一级缓存里的数据)保存到二级缓存中;
- 二级缓存的优先级大于一级缓存,首先查询二级缓存,没找到才查询一级缓存;
- 二级缓存使用序列化方式保存对象,所以要缓存的类一定要实现
java.io.Serializable接口; - 从二级缓存中获取的实例对象是反序列化得到的结果,因此每次获取的实例对象都是不同的。
