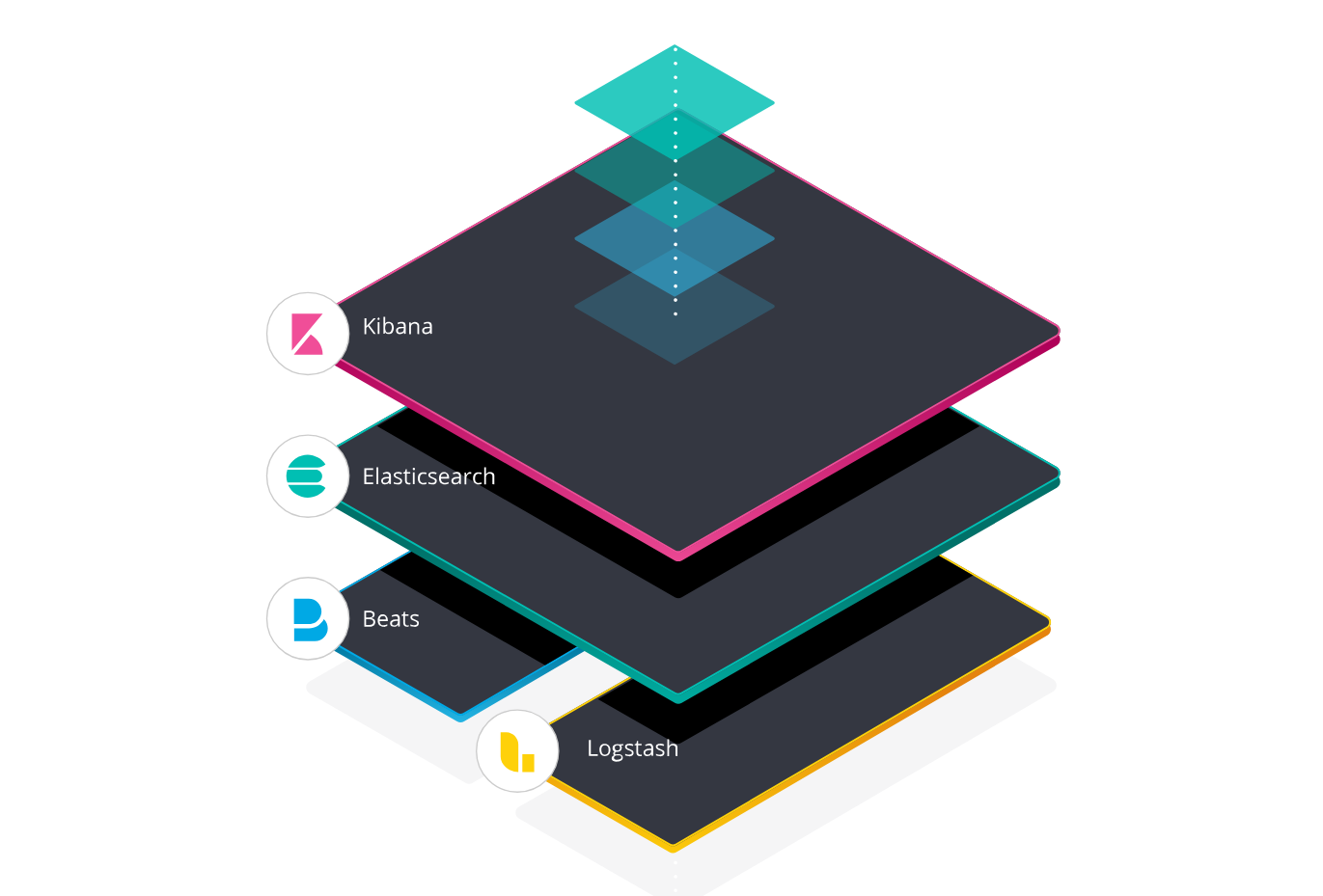
ELK安装
一 ELK
参考链接https://www.elastic.co/guide/en/elasticsearch/reference/6.0/getting-started.html
产生背景
为什么要用ELK
【问题排查困难】查询一个服务的日志,需要登录多台服务器;
【日志串接困难】一个流程有多个节点,要把整个流程的日志串接起来工作量大;
【运维管理困难】不是每个同事都有登录服务器查看日志的权限,但又需要根据日志排查问题,就需要有权限的同事下载日志后给到相应负责的同事。
【系统预警困难】无法实现服务出现异常后,及时通知到相应的负责人。
所以需要搭建一套集中式的日志收集、存储、分析系统,将所有节点的日志统一收集、管理
因此选用了ELK
版本介绍
官方推荐【普通用户】启动服务
elasticsearch-7.5.1-linux-x86_64.tar.gz 需要java环境
kibana-7.5.1-x86_64.rpm java环境
logstash-7.5.1.rpm java环境
filebeat-7.5.1.rpm
安装环境自定义
Java环境
如果你服务器中有java环境可忽略此部署操作
JDK1.8 安装
linux下安装jdk1.8
解压:
tar xf jdk-8u211-linux-x64.tar.gz
ln -s /data/jdk1.8.0_211 /data/jdk1.8
export JAVA_HOME=/data/jdk1.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile.d/jdk1.8.sh
2 Elasticsearch
下载地址:elasticsearch
用于日志数据存储
端口号:
#9200
#9300
解压:
【需要jdk环境】
配置:
####集群名称####
cluster.name: xssh
#跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*" #跨域访问
#节点名称
node.name: node-1
#node.attr.rack: r1
#path.data: /path/to/data
#path.logs: /path/to/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false #内存锁关闭.
network.host: 0.0.0.0 #也可以改成主机的ip
http.port: 9200
discovery.seed_hosts: ["192.168.24.129", "192.168.24.133","192.168.24.130"] #es集群的ip
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
【修改系统配置】
vim /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
vim /etc/sysctl.conf
vm.max_map_count=262144
授权:
chown -R forest /data/es1/*
启动:
一定要非root用户启动
/data/es1/bin/elasticsearch -d &
命令:
一下命令是简单使用
查看集群数量
curl 'localhost:9200/_cat/nodes?v'
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.24.130 21 63 0 0.00 0.01 0.05 dilm * node-2
192.168.24.133 14 58 0 0.03 0.03 0.05 dilm - node-1
查看集群机器状态
curl 'localhost:9200/_cat/health?v'
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1597743190 09:33:10 xssh green 2 2 16 8 0 0 0 0 - 100.0%
查看索引
curl http://localhost:9200/_cat/indices?v
删除索引
删除一个叫wwh_test3的索引
curl -XDELETE http://192.168.24.130:9200/wwh_test3
3 kibana
日志收集后,出图,展示
端口:5601
安装:
yum -y localinstall kibana-7.5.1-x86_64.rpm
配置:
vim /etc/kibana/kibana.yml
server.host: "192.168.24.128" #第7行
elasticsearch.hosts: ["http://192.168.24.133:9200"] #第28行 改成es的主机地址
启动:
systemctl restart kibana.service
开机自启
systemctl enable kibana.service
查看:
jps命令
注意事项⭐
日志收集等配置文件的格式一定要注意!!!!
格式!!!
格式!!!
格式!!!
4 logstash
主要用于提取redis中日志,过滤.输出到ES中.
端口号:9600
安装:
【需要jdk环境】
yum -y localinstall logstash-7.5.1.rpm
配置:
收集日志的配置文件都需要写在在此目录下面
/etc/logstash/conf.d
启动:
systemctl start logstash
启动报错
# journalctl -ex
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit logstash.service has finished shutting down.
8月 14 11:40:47 kibana systemd[1]: Started logstash.
-- Subject: Unit logstash.service has finished start-up
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit logstash.service has finished starting up.
--
-- The start-up result is done.
#######################################################################
##!!!could not find java没有找到java环境,修改如下文件 /usr/share/logstash/bin/logstash.lib.sh
####################################################################
8月 14 11:40:47 kibana logstash[91224]: could not find java; set JAVA_HOME or ensure java is in PATH
8月 14 11:40:47 kibana systemd[1]: logstash.service: main process exited, code=exited, status=1/FAILURE
8月 14 11:40:47 kibana systemd[1]: Unit logstash.service entered failed state.
8月 14 11:40:47 kibana systemd[1]: logstash.service failed.
8月 14 11:40:47 kibana systemd[1]: logstash.service holdoff time over, scheduling restart.
8月 14 11:40:47 kibana systemd[1]: Stopped logstash.
-- Subject: Unit logstash.service has finished shutting down
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit logstash.service has finished shutting down.
8月 14 11:40:47 kibana systemd[1]: start request repeated too quickly for logstash.service
8月 14 11:40:47 kibana systemd[1]: Failed to start logstash.
-- Subject: Unit logstash.service has failed
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
备份修改文件
cp /usr/share/logstash/bin/logstash.lib.sh /usr/share/logstash/bin/logstash.lib.sh.bak
vim /usr/share/logstash/bin/logstash.lib.sh
###大概在18行位置添加如下
18 export JAVA_HOME=/data/jdk1.8/ #自己的java环境的位置
19 export PATH=$PATH:$JAVA_HOME/bin
如果是其它报错,请检查配/etc/logstash/conf.d下的配置文件的规范格式
重启
systemctl restart logstash
开机自启
systemctl enable logstash
测试:
(1).测试使用
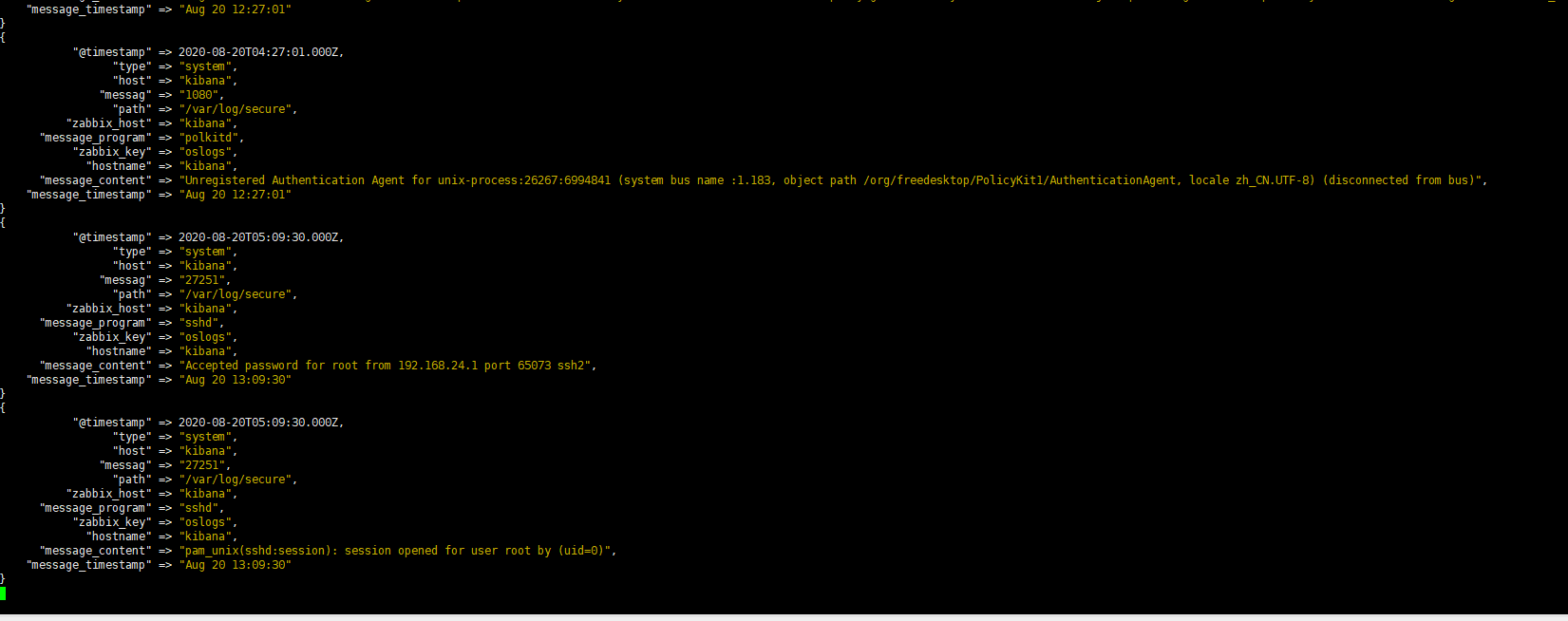
/usr/share/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug }}' #标准输入和输出
[INFO ] 2020-08-17 17:28:23.455 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9601}
Hi,lzl
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"message" => "Hi,lzl", #信息
"@timestamp" => 2020-08-17T09:28:43.035Z, #时间戳
"host" => "kibana", #主机名
"@version" => "1"
}
(2).检查语义
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/文件.conf -t
-f 指定配置文件
-t 检查语义
示例:#检查game_elfk.conf是否有语义错误
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/game_elfk.conf -t
#检查game_elfk.conf是否有语义错误
5 FileBeat
安装在日志对象的主机机器上,用于收集日志
轻量,消耗占用资源少
安装:
yum -y localinstall filebeat-7.5.1-x86_64.rpm
#查看filebeat的文件
rpm -ql filebeat
/etc/filebeat/fields.yml
/etc/filebeat/filebeat.reference.yml
/etc/filebeat/filebeat.yml #filebeat的配置文件
...
...
启动:
开机自启
systemctl enable filebeat
filebeat 收集配置测试是否成功
filebeat -e
6.收集
elk架构比较灵活,收集方式很多种,下面简单写些例子
1.filebeat=>elasticsearch=>kibana
2.filebeat=>redis=>logstash=>elasticsearch=>kibana
3.filebeat=>kafka=>logstash=>elasticsearch=kibana
....
收集方式1:
filebeat直接输出es
filebeat收集多种日志
【filebeat】==>【ES】==>【kibana】
问题:多个路径的日志需要收集到es中
解决:写多个路径,并打上tags
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
############
##############【es的日志】 ################
- type: log
enabled: true
paths:
- /var/log/elasticsearch/elasticsearch.log
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
tags: ["es"]
################【nginx的日志】##############
- type: log
enabled: true
paths:
- /data/nginx/logs/error.log
# json.keys_under_root: true
# json.overwrite_keys: true
tags: ["nginx"]
################【java的日志】##########
- type: log
enabled: true
paths:
- /data/home/user00/log/archived/h5_auth_cat.error.2020-06-17.log
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
tags: ["cat"]
#################【auth的java日志】###############
- type: log
enabled: true
paths:
- /data/home/user00/log/archived/h5_auth.2020-06-17.log
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
tags: ["auth"]
###############################
#kibana的ip地址
setup.kibana:
host: "192.168.24.128:5601"
##############【输出对象】#######
output.elasticsearch:
hosts: ["192.168.24.133:9200","192.168.24.130:9200"]
indices:
- index: "es-%{[agent.version]}-%{+yyyy.MM.dd}" #es日志的索引
when.contains:
tags: "es"
- index: "auth-error-%{[agent.version]}-%{+yyyy.MM.dd}}" #auth日志的索引
when.contains:
tags: "auth"
- index: "cat-error-%{[agent.version]}-%{+yyyy.MM.dd}" #cat日志索引
when.contains:
tags: "cat"
- index: "nginx-error-%{[agent.version]}-%{+yyyy.MM.dd}" #nginx日志索引
when.contains:
tags: "nginx"
setup.template.name: "es" #索引模板名称
setup.template.pattern: "es-*"
setup.template.overwrite: true #模板重写
setup.template.enabled: false #是否开启
#此项设置成【false】!!!!页面不然会一直是默认的filebeat索引开头
setup.ilm.enabled: false
setup.template.settings:
index.number_of_shards: 3 #分片数
####【下面加不加目前不影响】######
#processors:
# - add_host_metadata: ~
# - add_cloud_metadata: ~
# - add_docker_metadata: ~
# - add_kubernetes_metadata: ~
#
【以上是filebeat直接收取目录日志到es中,如果是收集单个日志,根据上面参考修改即可】
启动:
filebeat
systemctl restart filebeat
收集方式21.filebeat>redis>logstash>ES
问题:收集日志量较多,较大,如果logstas宕了,可能导致数据丢失,不完整。
解决:中间加redis做消息队列进行缓冲。
1.【filebeat】==>【redis】==>【logstash】==>【ES】
#redis安装
yum -y install redis
#redis添加密码
vim /etc/redis.conf +481 #481行左右打开 requirepass foobared的注释,foobared为密码,可以改成自己想改的
requirepass foobared
#redis启动
systemctl restart redis
#redis开机自启
systemctl enable redis
#redis密码登陆
127.0.0.1:6379> AUTH foobared OK
单日志收集
收集java日志
【filebeat配置】
vim /etc/filebeat/filebeat.yml
filebeat.inputs: - type: log enabled: true paths: - /data/home/user00/log/forest_error.log multiline.pattern: '^\[' multiline.negate: true multiline.match: after #是否是json格式 setup.template.settings: index.number_of_shards: 5 #分片数 setup.kibana: host: "192.168.24.128:5601" #kibana的链接 setup.template.name: "error" #索引模板 setup.template.pattern: "error-*" setup.template.enabled: false setup.template.overwrite: true setup.ilm.enabled: false output.redis: # 输出对象redis hosts: ["192.168.24.131:6379"] # redis地址 key: "forest" # 在reidis内创建的key名称 db: 0 password: "foobared" timeout: 5

【logstash配置】
vim /etc/logstash/conf.d/logstash_ceshi.conf
input { #输入对象
redis { #redis
data_type => "list" #数据类型 list
key => "forest" #key识别数据
host => "192.168.24.131" #redis所在主机地址
port => "6379" #端口
db => "0" #库
password => "foobared"
}}
output { #输出对象
elasticsearch { #elasticsearch
hosts => ["192.168.24.133:9200"] #输出对象ip地址
index =>"forest_err_%{+YYYY.MM.dd}" #索引展示
}}
检查语义
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash_ceshi.conf -t
启动:
filebeat
systemctl restart filebeat
logstash
systemctl restart logstash
多日志收集
问题: 【一台主机需要收集多个路径的日志输入到同一个库】 收集java日志,和nginx日志 输入到redis库(db4)中并利logstash取出到es中 解决: 1.我们给不同的日志文件打上标签(tags),输入redis后,logstash通过判断标签(tags)来进行匹配收集数据,并输出到es中,展示到kibana中. 2.不同主机的日志输入到同一个redis库中,通过tags做标识,然后logstash通过判断tags,也不会影响数据。 配置如下
filebeat配置
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log #类型
enabled: true #开启filebeat收集
paths: #日志路径
- /var/log/forest_bench.log #日志对象forest_bench.log
tags: ['134_forest_bench'] #记住此tags标签,logstash取日志时,需要通过此tags进行判断。
multiline.pattern: '^\[' #匹配规则
multiline.negate: true
multiline.match: "after"
- type: log
enabled: true
paths:
- /data/nginx/logs/error.log #收集的日志位置
multiline.pattern: '^\[' #匹配规则
multiline.negate: true
multiline.match: after
tags: ['134_nginx'] #记住此标签。
setup.template.settings:
index.number_of_shards: 5 #分片数
setup.kibana: #kibana链接
host: "192.168.24.128:5601" #kibana所在主机ip
output.redis: #输出对象redis
hosts: ["192.168.24.131:6379"] # redis所在主机的ip地址
date_type: "list" #数据类型
key: "forest" #在reidis内创建的key名称
db: 4 #redis的库
password: "foobared"
timeout: 5
【logstash配置】
vim /etc/logstash/conf.d/logstash_ceshi.conf
input {
redis { #redis
data_type => "list"
key => "forest" #通过key识别
host => "192.168.24.131" #redis主机ip
port => "6379" #redis端口
db => "4" #reids库
password => "foobared"
}}
output { #输出
if "134_nginx" in [tags] { #通过匹配tags判断日志源.
elasticsearch { #输出对象
hosts => ["192.168.24.133:9200"] #输出对象主机ip
index => "134_nginx_err_more_%{+YYYY.MM.dd}" #索引展示名称
}}
if "134_forest_bench" in [tags] {
elasticsearch {
hosts => ["192.168.24.133:9200"]
index => "134_forest_err_more_%{+YYYY.MM.dd}"
}}}
#判断filebeat语义是否有问题
filebeat -e
#判断logstash语义是否有问题
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash_ceshi.conf -t
启动:
filebeat
systemctl restart filebeat
logstash
systemctl restart logstash
7.索引
清理索引:
时间长了,各种索引时间越来越多,要及时清理.
脚本: 清理一个月前的日志
vim clean_index.sh
#!/bin/bash DATE=`date +%Y-%m -d -1month` #echo $DATE curl -XDELETE http://localhost:9200/128_game_err_more_$DATE-%"
8.调优
1.清理缓存
curl -XPOST "localhost:9200/_cache/clear"
redis
参考链接:cnblog
优化方向
(1)filebeat可以直接输入到logstash(indexer),但logstash没有存储功能,如果需要重启需要先停所有连入的beat,再停logstash,造成运维麻烦;另外如果logstash发生异常则会丢失数据;引入Redis作为数据缓冲池,当logstash异常停止后可以从Redis的客户端看到数据缓存在Redis中; (2)Redis可以使用list(最长支持4,294,967,295条)或发布订阅存储模式; (3)redis 做elk 缓冲队列的优化: bind 0.0.0.0 #不要监听本地端口 requirepass xxxx #加密码,为了安全运行 ③只做队列,没必要持久存储,把所有持久化功能关掉:快照(RDB文件)和追加式文件(AOF文件),性能更好 save "" 禁用快照 appendonly no 关闭RDB ④ 把内存的淘汰策略关掉,把内存空间最大
kibana
优化方向
优化查询语句 1、少用* 等匹配方式 2、尽量指定字段进行匹配,而不是全文索引 3、页面刷新间隔时间一般是设置15分钟 4、es优化 5、kibana集群减轻master或client压力 6、不同的visualize,dashboard建立的视图都应该用刷新间隔至少30分钟以上Save保存;这样就不会导致每个运维打开页面后,visualize,dashboard都在实时刷新,越是查询范围广的,刷新间隔时间约要设置长,例如查全量的404,500有哪些域这种是全量查询,设置的刷新时间要更长一些
logstash
参考链接:
【原文】: 检查JVM堆: 如果堆大小太低,通常CPU利用率经常会上升,从而导致JVM不断进行垃圾收集。 频繁的垃圾回收或与内存不足异常相关的JVM崩溃,超出最佳范围的值会导致性能下降。 检查此问题的快速方法是将堆大小加倍,并查看性能是否有所提高。不要增加堆大小超过物理内存量。为操作系统和其他进程留出至少1GB的可用空间。 您可以使用jmap随Java一起分发的命令行实用程序或使用VisualVM 对JVM堆进行更准确的测量。有关更多信息,请参见分析堆。 始终确保将最小(Xms)和最大(Xmx)堆分配大小设置为相同的值,以防止在运行时调整堆大小,这是一个非常昂贵的过程。 【结论】:最小值(Xms)和最大值(Xmx)最好改成一样的 调整Logstash工作程序设置: 首先使用该-w标志扩大管道工人的数量。这将增加可用于过滤器和输出的线程数。如果需要,可以安全地将其扩展到多个CPU内核,因为线程可以在I / O上变为空闲状态。 您也可以调整输出批次大小。对于许多输出,例如Elasticsearch输出,此设置将对应于I / O操作的大小。对于Elasticsearch输出,此设置对应于批次大小。
(1).运行内存调优
vim /etc/logstash/jvm.options
1 ## JVM configuration 2 3 # Xms represents the initial size of total heap space 4 # Xmx represents the maximum size of total heap space 5 #堆内存分配的最小值 6 -Xms1g #堆内存分配的最大值 7 -Xmx1g
(2).logstash.yml 优化
vim /etc/logstash/logstash.yml
1)可以优化的参数,可根据自己的硬件进行优化配置 ① pipeline 线程数,官方建议是等于CPU内核数 默认配置 ---> pipeline.workers: 2 可优化为 ---> pipeline.workers: CPU内核数(或几倍cpu内核数) ③ 每次发送的事件数 默认配置 ---> pipeline.batch.size: 125 可优化为 ---> pipeline.batch.size: 1000 ④ 发送延时 默认配置 ---> pipeline.batch.delay: 5 可优化为 ---> pipeline.batch.size: 10
elasticsearch
(b)limits.conf 配置 vim /etc/security/limits.conf elasticsearch soft nofile 65535 elasticsearch hard nofile 65535 elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited (c)为了使以上参数永久生效,还要设置两个地方 vim /etc/pam.d/common-session-noninteractive vim /etc/pam.d/common-session 添加如下属性: session required pam_limits.so 可能需重启后生效 (2)elasticsearch 中的jvm.options配置文件 -Xms2g -Xmx2g 将最小堆大小(Xms)和最大堆大小(Xmx)设置为彼此相等。 Elasticsearch可用的堆越多,可用于缓存的内存就越多。但请注意,太多的堆可能会使您长时间垃圾收集暂停。 设置Xmx为不超过物理RAM的50%,以确保有足够的物理内存留给内核文件系统缓存。 不要设置Xmx为JVM用于压缩对象指针的临界值以上;确切的截止值有所不同,但接近32 GB。不要超过32G,如果空间大,多跑几个实例,不要让一个实例太大内存 (4)集群的优化 ① ES是分布式存储,当设置同样的cluster.name后会自动发现并加入集群; ② 集群会自动选举一个master,当master宕机后重新选举; ③ 为防止"脑裂",集群中个数最好为奇数个 ④ 为有效管理节点,可关闭广播 discovery.zen.ping.multicast.enabled: false,并设置单播节点组discovery.zen.ping.unicast.hosts: ["ip1", "ip2", "ip3"]
性能
性能的检查
(1)检查输入和输出的性能 #Logstash和其连接的服务运行速度一致,它可以和输入、输出的速度一样快。 (2)检查系统参数 ① CPU #注意CPU是否过载。在Linux/Unix系统中可以使用top -H查看进程参数以及总计。 #如果CPU使用过高,直接跳到检查JVM堆的章节并检查Logstash worker设置。 ② Memory #注意Logstash是运行在Java虚拟机中的,所以它只会用到你分配给它的最大内存。 #检查其他应用使用大量内存的情况,这将造成Logstash使用硬盘swap,这种情况会在应用占用内存超出物理内存范围时。 ③ I/O 监控磁盘I/O检查磁盘饱和度 #使用Logstash plugin(例如使用文件输出)磁盘会发生饱和。 #当发生大量错误,Logstash生成大量错误日志时磁盘也会发生饱和。 #在Linux中,可使用iostat,dstat或者其他命令监控磁盘I/O ④ 监控网络I/O #当使用大量网络操作的input、output时,会导致网络饱和。 #在Linux中可使用dstat或iftop监控网络情况。 (3)检查JVM heap # heap设置太小会导致CPU使用率过高,这是因为JVM的垃圾回收机制导致的。 # 一个快速检查该设置的方法是将heap设置为两倍大小然后检测性能改进。不要将heap设置超过物理内存大小,保留至少1G内存给操作系统和其他进程。 # 你可以使用类似jmap命令行或VisualVM更加精确的计算JVM heap
分片
当日志量大时,单个分片存在查询慢(默认是1),所以根据具体情况调整分片数
手动设置分片
参考链接:内容类型检查
#原文 Elasticsearch 6.0中即将进行的更改之一是严格的内容类型检查。 有什么变化? 从Elasticsearch 6.0开始,所有包含主体的REST请求还必须为该主体提供正确的内容类型 #### 当我们手动添加索引分片时,要加-H指定,不然报错 # -H "Content-Type: application/json"
curl -H "Content-Type: application/json" -X PUT 'http://localhost:9200/wwh_test3/' -d '{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
}'
nginx代理kibana并设置白名单
nginx配置
vim /data/nginx/conf.d/kibana.conf
upstream kibana_server {
server 192.168.24.128:5601 weight=1 max_fails=3 fail_timeout=60;
}
server {
listen 80;
server_name www.testes.com; #公司域名
allow 114.86.224.135; # 放行公司IP
deny all;
location / {
proxy_pass http://kibana_server;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
检查语义
nginx -t
启动
systemctl restart nginx
浏览器访问:
www.testes.com
拓展
参考链接:zabbix实时监控elk
前言:
zabbix监控日志实时数据,过滤匹配出error,warn,failure,等字段,进行告警; 核心:需要一个插件 【 logstash-output-zabbix】
查看logstash的插件列表
sh logstash-plugin list
logstash-codec-avro logstash-codec-cef logstash-codec-collectd logstash-codec-dots logstash-codec-edn logstash-codec-edn_lines logstash-codec-es_bulk logstash-codec-fluent logstash-codec-graphite logstash-codec-json logstash-codec-json_lines ...... ...... ......
logstash-plugin命令还有多种用法,我们来简单了解一下: 【2.1】、列出目前已经安装的插件 将列出所有已安装的插件 /usr/share/logstash/bin/logstash-plugin list #将列出已安装的插件及版本信息 /usr/share/logstash/bin/logstash-plugin list --verbose #将列出包含namefragment的所有已安装插件 /usr/share/logstash/bin/logstash-plugin list "http" #将列出特定组的所有已安装插件( input,filter,codec,output) /usr/share/logstash/bin/logstash-plugin list --group input 【2.2】、安装插件 #要安装某个插件,例如安装kafka插件,可执行如下命令: /usr/share/logstash/bin/logstash-plugin install logstash-output-kafka #要使用此命令安装插件,需要你的电脑可以访问互联网。此插件安装方法,会检索托管在公共存储库(RubyGems.org)上的插件,然后下载到本地机器并在Logstash安装之上进行自动安装。 【2.3】、更新插件 #每个插件有自己的发布周期和版本更新,这些更新通常是独立于Logstash的发布周期的。因此,有时候需要单独更新插件,可以使用update子命令获得最新版本的插件。 #将更新所有已安装的插件 /usr/share/logstash/bin/logstash-plugin update #将仅更新指定的插件 /usr/share/logstash/bin/logstash-plugin update logstash-output-kafka 【2.4】、删除插件 #如果需要从Logstash插件中删除插件,可执行如下命令: /usr/share/logstash/bin/logstash-plugin remove logstash-output-kafka #这样就删除了logstash-output-kafka插件。
正题:
logstash-output-zabbix是一个社区维护的插件; #它默认没有在Logstash中安装,但是安装起来也很容易,直接在logstash中运行如下命令即可:
(1).安装插件
/usr/share/logstash/bin/logstash-plugin install logstash-output-zabbix
(2).测试例子
vim /etc/logstash/conf.d/zabbix_elk.conf
input {
file {
path => ["/var/log/secure"]
type => "system"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:message_pid}\])?: %{GREEDYDATA:message_content}" }
}
mutate {
add_field => [ "[zabbix_key]", "oslogs" ]
add_field => [ "[zabbix_host]", "%{host}" ]
}
mutate {
remove_field => "@version"
remove_field => "message"
}
date {
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}
output {
if [message_content] =~ /(ERR|error|ERROR|failure)/ {
zabbix {
zabbix_host => "[zabbix_host]"
zabbix_key => "[zabbix_key]"
zabbix_server_host => "192.168.24.134"
zabbix_server_port => "10051"
zabbix_value => "message_content"
}
}
# stdout { codec => rubydebug }
}
【解释!!!】
#你们接触以上配置文件可能存在不明白的问题,如下进行分段解释。
第一段:
首先是input部分,内容如下:
input {
file {
path => ["/var/log/secure"]
type => "system"
start_position => "beginning"
}
}
input部分是从/var/log/secure文件中读取数据,start_position 表示从secure文件开头读取内容。
接着是filter部分,内容如下:
filter {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:messag
e_pid}\])?: %{GREEDYDATA:message_content}" } #这里通过grok对message字段的数据进行字段划分,这里将message字段划分了5个子字段。其中,message_content字段会在output中用到。
}
mutate {
add_field => [ "[zabbix_key]", "oslogs" ] #新增的字段,字段名是zabbix_key,值为oslogs。
add_field => [ "[zabbix_host]", "%{host}" ] #新增的字段,字段名是zabbix_host,值可以在这里直接定义,也可以引用字段变量来获取。这里的%{host}获取的就是日志数据的主机名,这个主机名与zabbix web中“主机名称”需要保持一致。
}
mutate { #这里是删除不需要的字段
remove_field => "@version"
remove_field => "message"
}
date { #这里是对日志输出中的日期字段进行转换,其中message_timestamp字段是默认输出的时间日期字段,将这个字段的值传给 @timestamp字段。
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}
#filter部分是个重点,在这个部分中,重点关注的是message_timestamp字段、message_content字段。
最后是output部分,内容如下:
output {
if [message_content] =~ /(ERR|error|ERROR|Failed)/ { #定义在message_content字段中,需要过滤的关键字信息,也就是在message_content字段中出现给出的这些关键字,那么就将这些信息发送给zabbix。
zabbix {
zabbix_host => "[zabbix_host]" #这个zabbix_host将获取上面filter部分定义的字段变量%{host}的值
zabbix_key => "[zabbix_key]" #这个zabbix_key将获取上面filter部分中给出的值
zabbix_server_host => "172.16.213.140" #这是指定zabbix server的IP地址
zabbix_server_port => "10051" #这是指定zabbix server的监听端口
zabbix_value => "message_content" #这个很重要,指定要传给zabbix监控项item(oslogs)的值, zabbix_value默认的值是"message"字段,因为上面我们已经删除了"message"字段,因此,这里需要重新指定,根据上面filter部分对"message"字段的内容划分,这里指定为"message_content"字段,其实,"message_content"字段输出的就是服务器上具体的日志内容。
}
}
#stdout { codec => rubydebug } #这里是开启调试模式,当第一次配置的时候,建议开启,这样过滤后的日志信息直接输出的屏幕,方便进行调试,调试成功后;已默认进行注释,如果第一次配置调试,可自行打开。
}
将上面三部分内容合并到一个文件file_to_zabbix.conf中,然后启动logstash服务:
调试模式
(3)zabbix添加主机
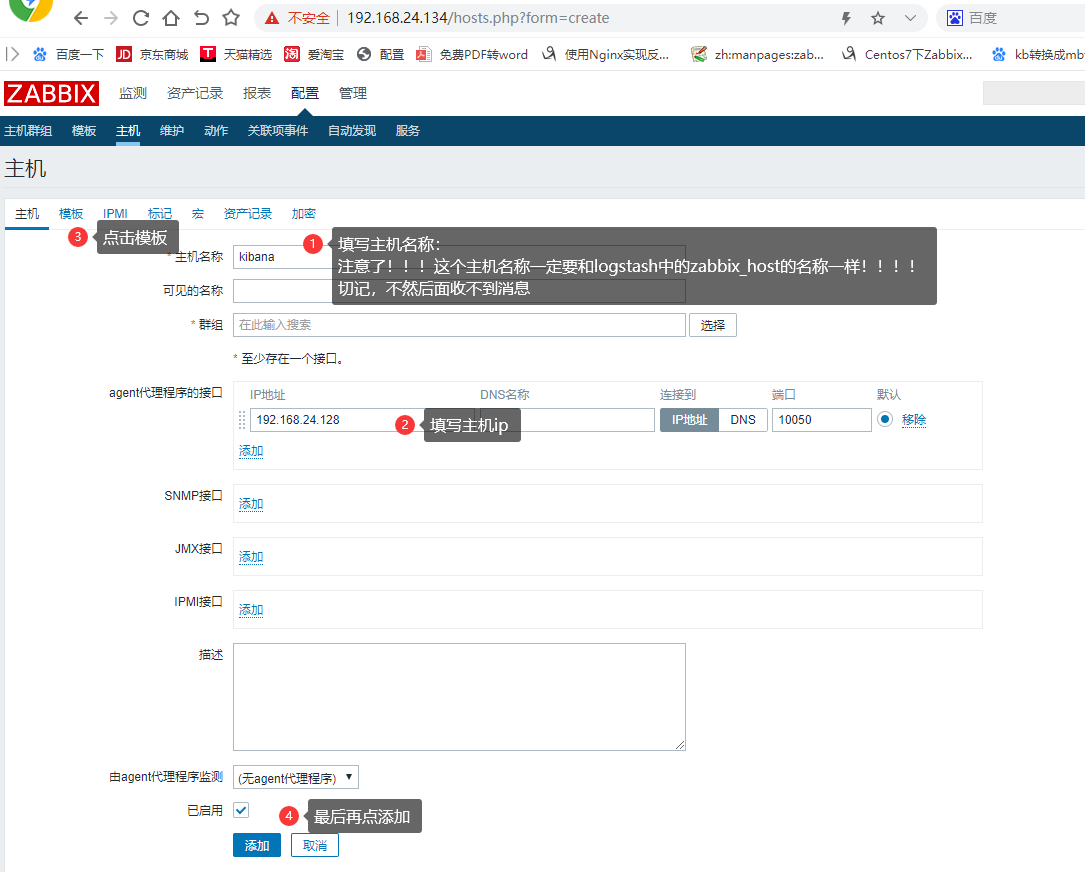
2.添加zabbix收集器。
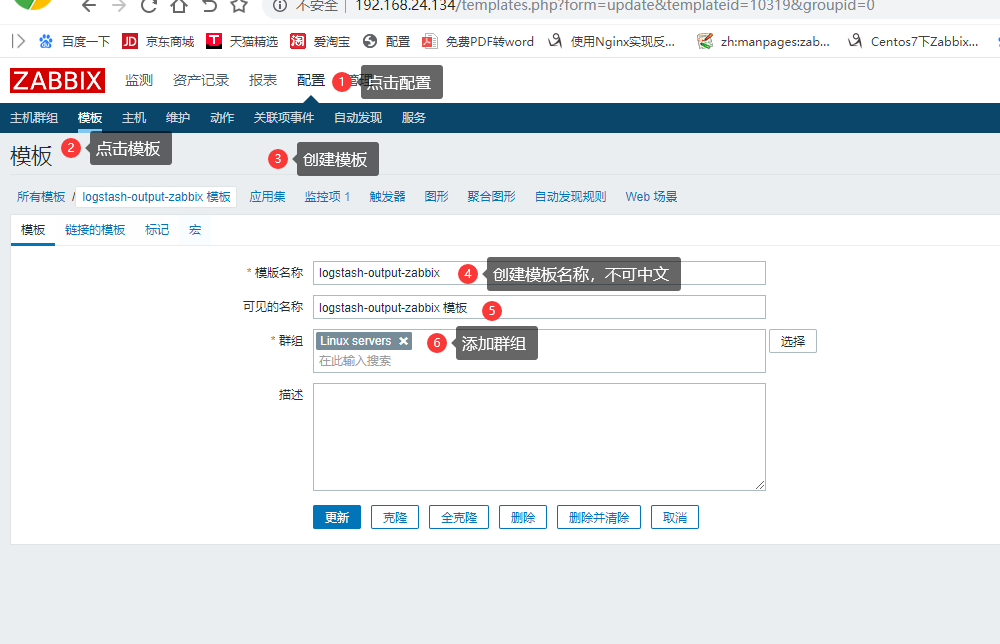
添加自定义模板
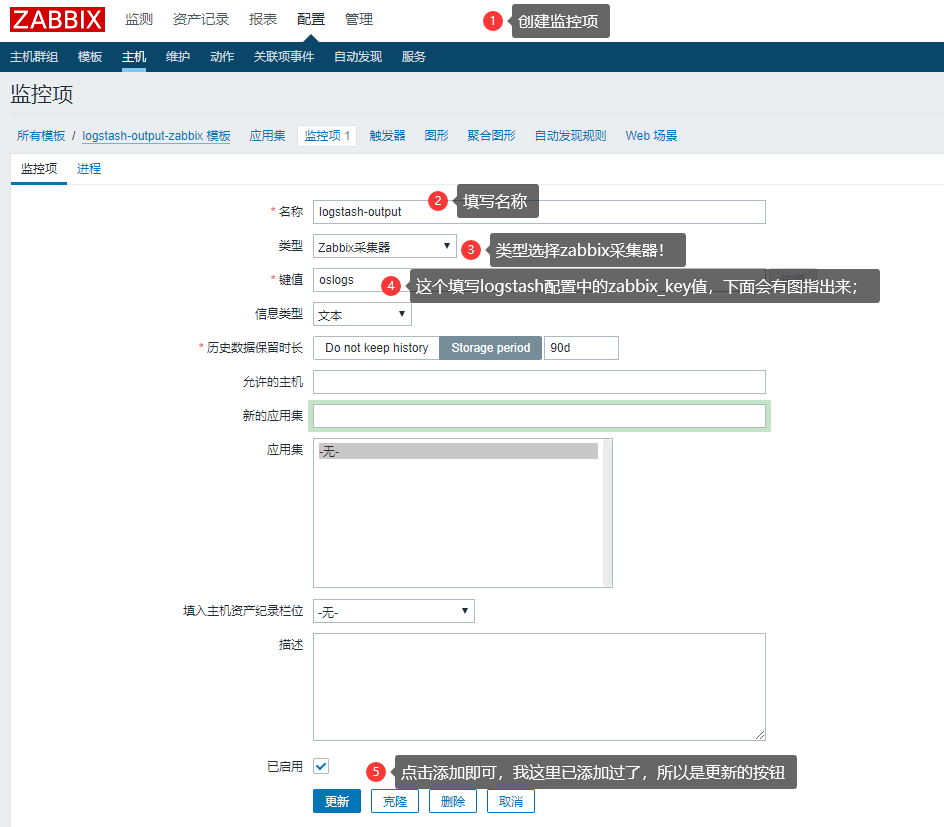
添加监控项,配置采集器
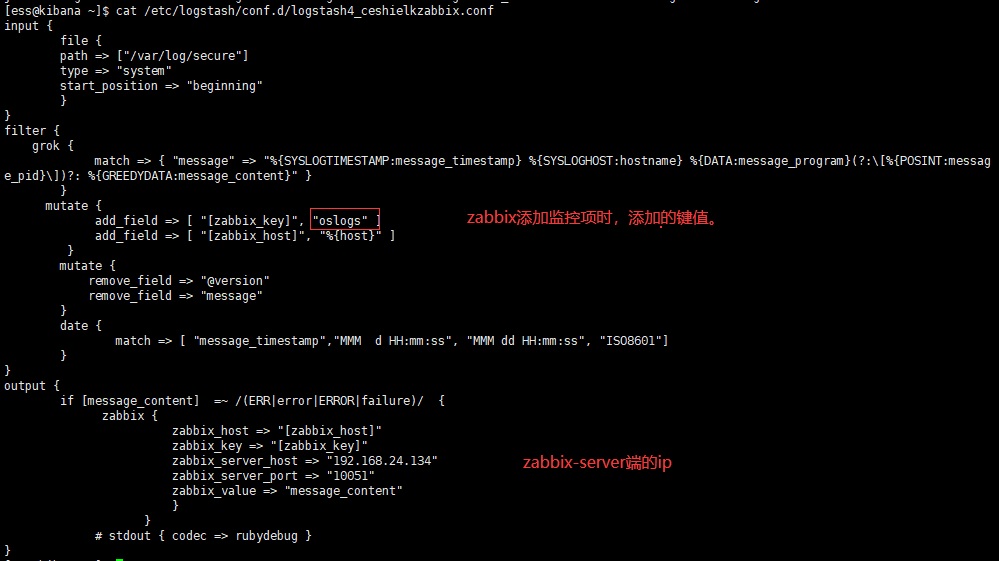
将创建logstash-output-zabbix模板添加到主机中

模拟创建错误信息

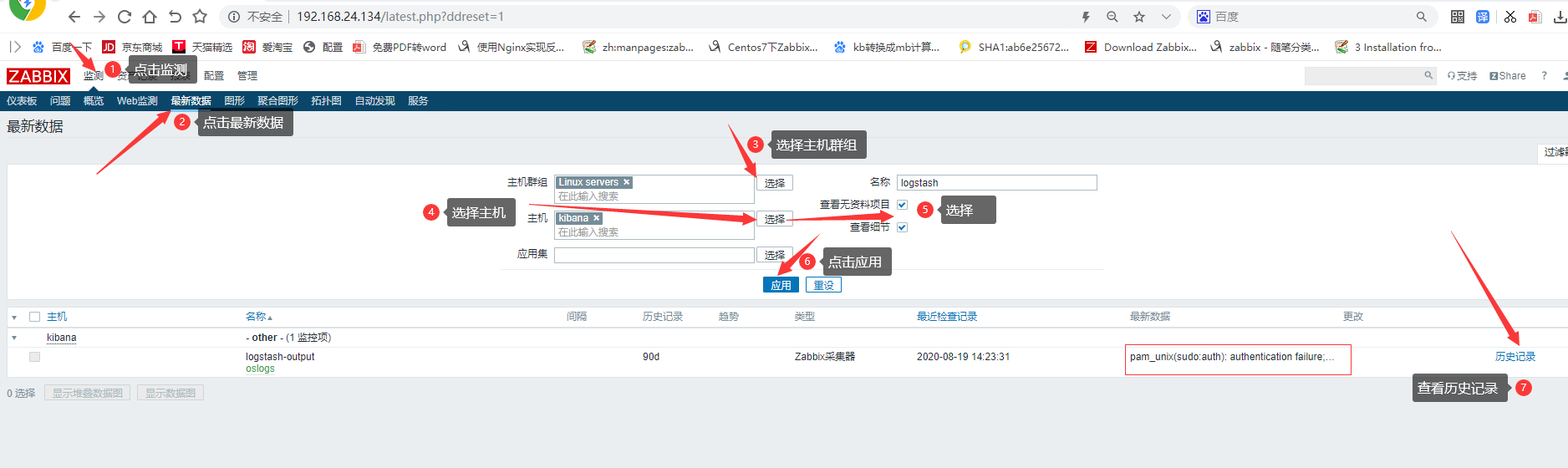

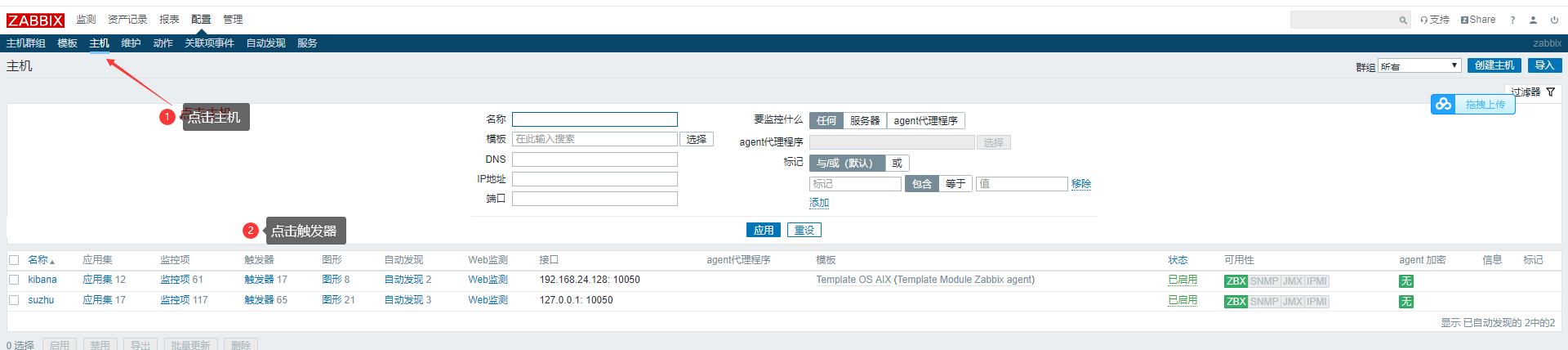
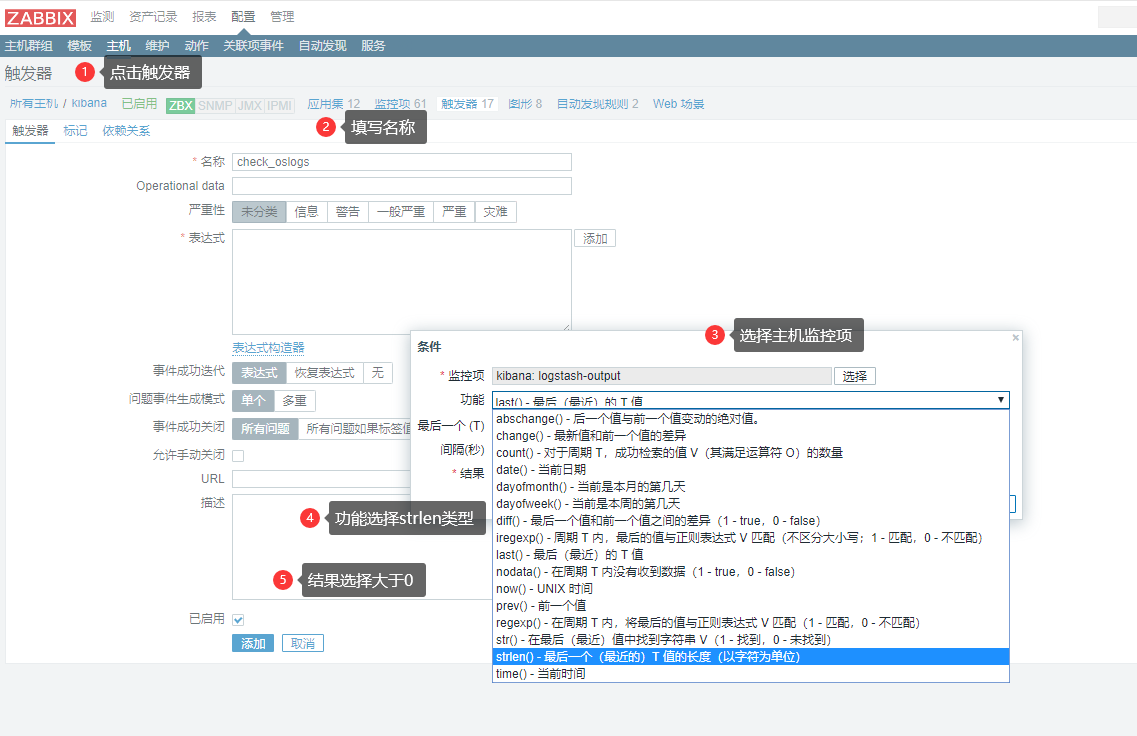
添加触发器
点击主机-添加触发器--》选择————》strlen类型——》点击结果,大于0 点击恢复表达式--》结果小于等于0--》点击添加。
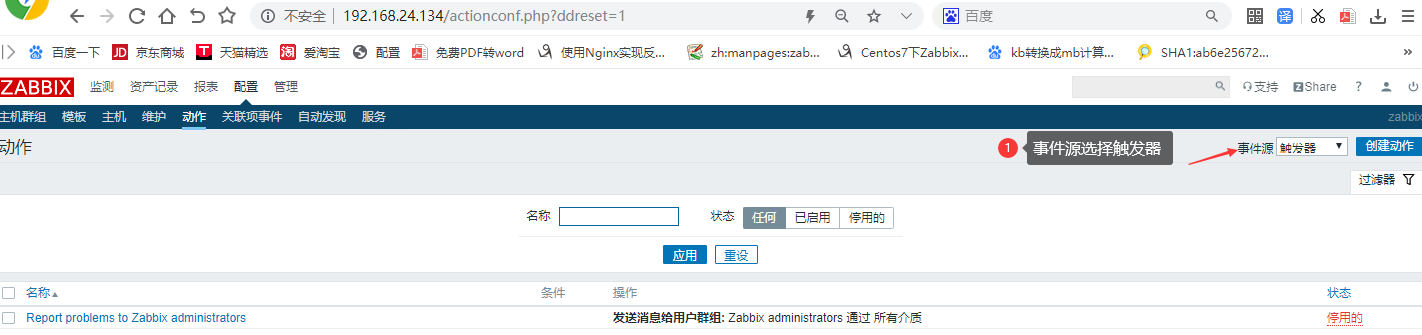
设置动作:触发邮件告警
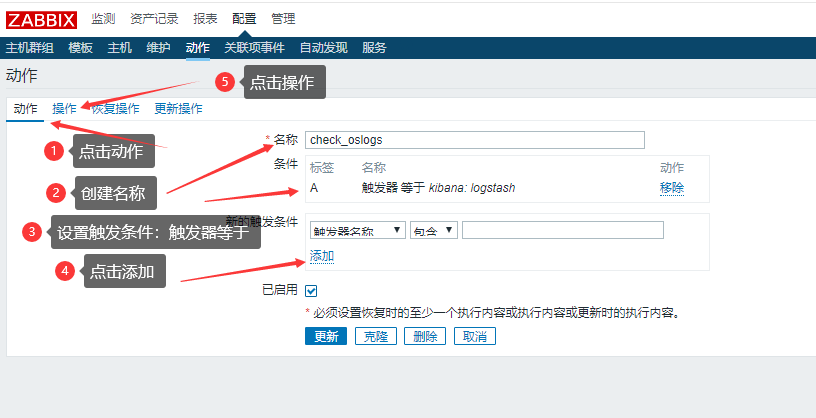
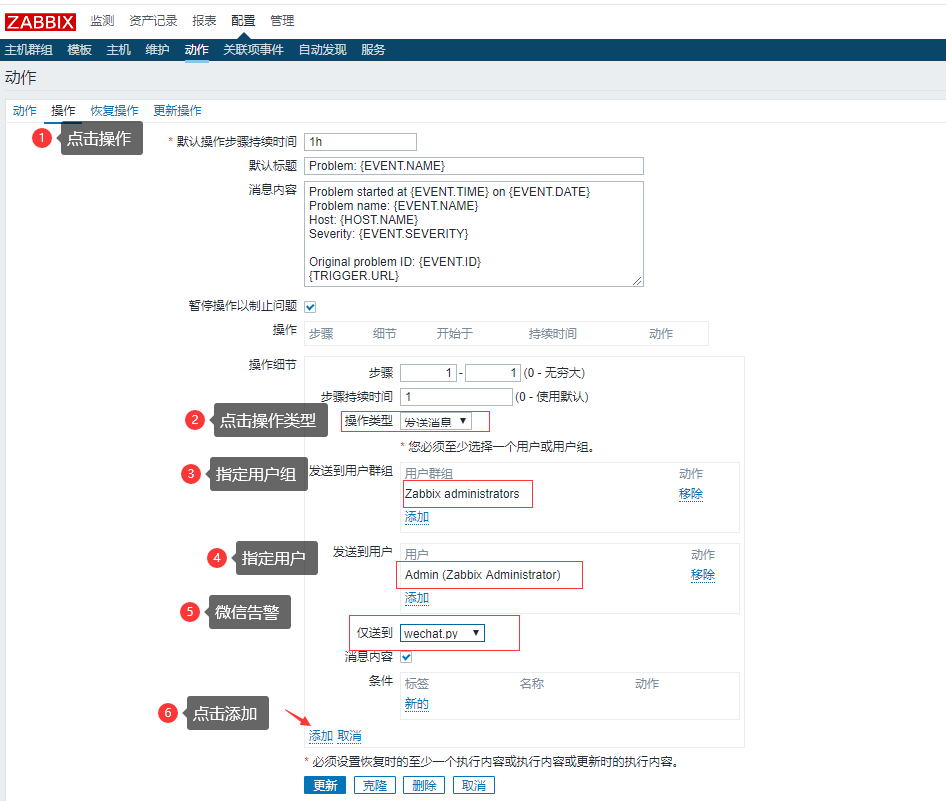
操作
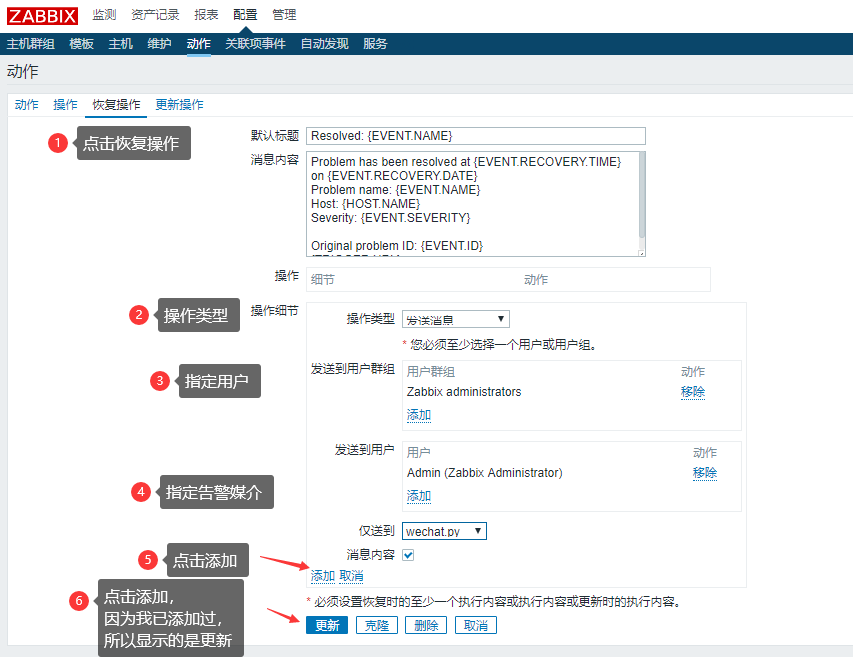
点击恢复操作
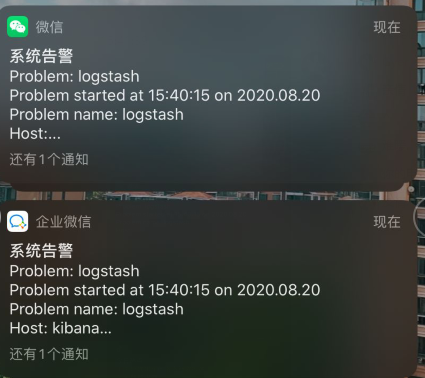
微信查看告警信息。
额外补充
在添加完zabbix监控项后,其实我们还可以用zabbix_sender检测是否成功
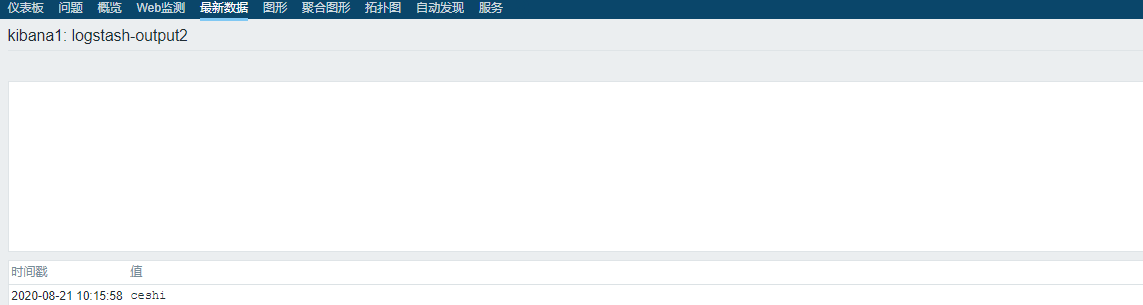
zabbix_sender -z 192.168.24.134 -s kibana1 -k oflogs -o ceshi Response from "192.168.24.134:10051": "processed: 1; failed: 0; total: 1; seconds spent: 0.000027" -z server端机器ip -s agent端机器ip -k 键值 -o ceshi 测试内容


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具