django3/路由层小知识
- Django请求声明周期流程图
- 路由匹配
- 反向解析
- 无名有名反向解析
- 路由分发
- 名称空间
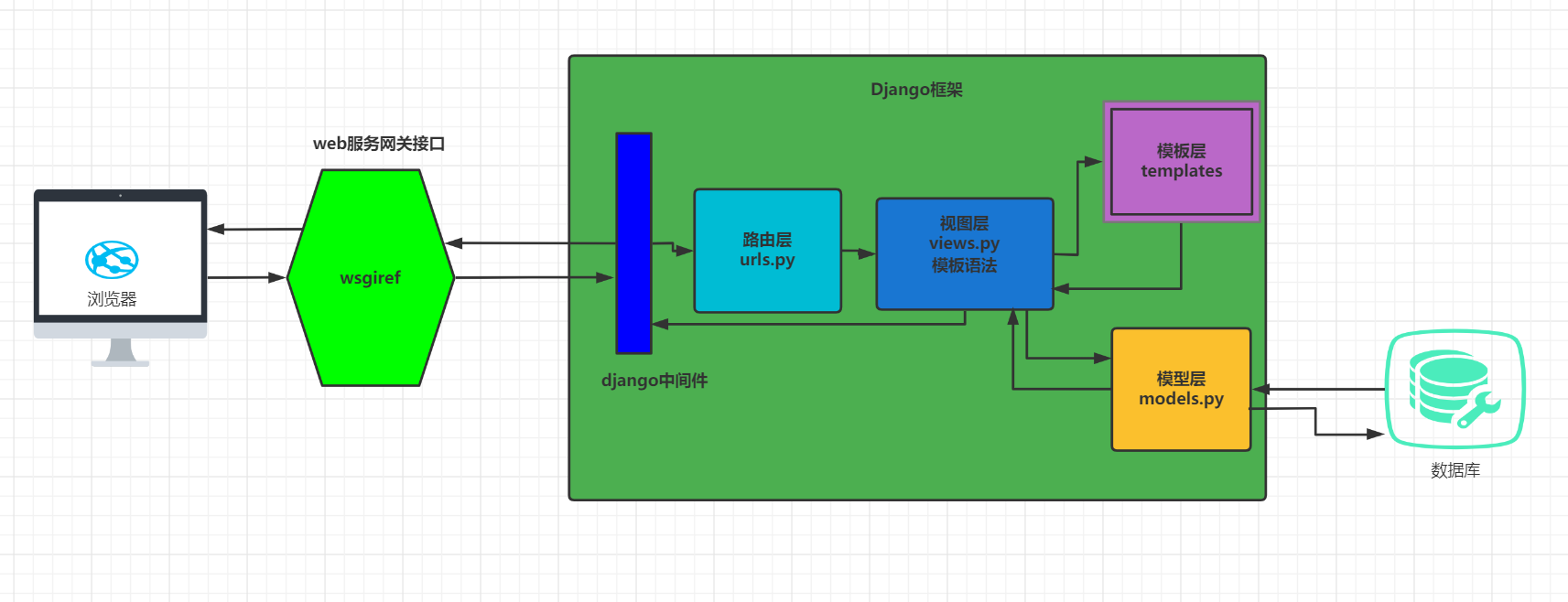
django请求生命周期流程图
浏览器默认基于HTTP协议访问web服务网关接口(Web Server Gateway Interface)
django中默认是用的是wsgiref功能模块,并发能力非常差,不足百人
django上线前都会切换成uwsgi功能模块,该服务并发能力高。wsgiref和uwsgi都属于wsgi协议。
访问通过路由层,找到视图层,视图层需要模板就会去找模板;
如果跟数据库有交涉,就会通过模型层连接数据库获取数据;
在视图层进行渲染,然后视图层直接返回给中间件,返回给服务网关接口,返回给浏览器
学习思路
路由层
视图层
模板层
模型层
django插件
django中间件
路由层
1.路由匹配
path
re_path
django版本区别
在django1.11中 只支持正则匹配 并且方法是 url()
django2,3,4中 path() re_path() 等价于 url()
urls.py文件
urlpatterns = [
path('admin/', admin.site.urls),
]
path
path('网址后缀',视图函数/函数名/类名)
一旦网址后缀匹配上了就会自动执行后面的函数,并且结束整个路由的匹配
1.路由结尾的斜杠
http://127.0.0.1:8000/login/
默认情况下不屑斜杠,django会做二次处理
第一次匹配不上,会让浏览器加斜杠再次请求
django配置文件中可以指定是否自动添加斜杠
settings.py
APPEND_SLASH = False #控制结尾是否自动添加斜杠 false是不自动的意思。
2.path转换器
当网址后缀不固定的时候可以使用转换器来匹配
#转换器
'int': IntConverter(),
-------------------------------
'path': PathConverter(),
-------------------------------
'slug': SlugConverter(),
--------------------------------
'str': StringConverter(),
--------------------------------
'uuid': UUIDConverter(),
--------------------------------
#2.示例:
- path('login/<int:year>', views.login),
- path('login/<str:name>', views.login),
- path('login/<path:p>',views.article),
#3.转化器不能在re_path中使用
也可以自定义转换器
#路由 urls.py文件转换器书写格式
path('func/<int:year>/<str:info>/', views.func)
转换器匹配到的内容先转化为int整型和str字符型,然后会当作视图函数的关键字参数传入 。
转换器有几个叫什么名字,那么视图层(views.py)中的形参必须对应,不然会报错
#视图层 views.py
def func(request,year,info) #year和info写死`
=======================================================================================
re_path 【用的比较多】
1.re_path(正则表达式,函数名)
2.正则匹配之无名分组
3.正则匹配之有名分组
1.re_path(正则表达式,函数名)
usrls.py
一旦网址后缀的正则能够匹配到内容就会自动执行后面的函数并且结束整个路由的匹配
re_path('^test/$', views.test)
eg: 127.0.0.1/test/
2.正则匹配之无名分组
正则表达式匹配到的内容会当作视图函数的位置参数 传递给视图函数
re_path('^test/(\d+)/', views.test)
3.正则匹配之有名分组
正则表达式匹配到的内容会当作视图函数的关键字参数传递给视图函数
re_path('^test/(?P<year>\d+)(?P<others>.*?)/',views.test)
反向解析
页面上提前写死了很多路由,一旦路由发送变化会导致所有页面相关链接失效
为了防止出现该问题,我们需要使用反向解析.
反向解析:返回一个结果,该结果可以访问到对应的路由
1.urls.py路由对应关系起别名
path('register/', views.reg, name='reg_view')
2.使用反向解析语法
html页面
{% url 'reg_view' %}
3.后端views.py
from django.shortcuts import reverse
reverse('reg_view')
ps:反向解析的操作三个方法都一样path() re_path() url()
无名有名反向解析
路由层urls.py
path('reg/<str:info>/', views.reg, name='reg_view')
当路由中有不确定的匹配因素 反向解析的时候需要人为给出一个具体的值
服务端views.py
reverse('reg_view', args=('jason',))
前端htmL
{% url 'reg_view' 'jason' %}
ps:反向解析的操作三个方法都一样path() re_path() url()
路由分发
django中的应用都可以有自己独立的
urls.py templates文件夹 static文件夹
能够让基于django开发的多个应用完全独立 便于小组开发
总路由urls.py
path('app01/', include('app01.urls')),
path('app02/', include('app02.urls')),
子路由app
path('after/', views.after) # app01
path('after/', views.after) # app02
"""
当项目特别大 应用特别多的时候 可以使用路由分发 非常方便!!!
"""
名称空间
用第二种解决方式
可以保证django项目下没有重复的别名即可
有路由分发场景下多个应用在涉及到反向解析别名冲突的时候无法正常解析
解决方式1
名称空间
namespace
path('app01/', include(('app01.urls', 'app01'), namespace='app01'))
path('app01/', include(('app01.urls', 'app02'), namespace='app02'))
------------------------------------------------------------------------------------
解决方式2
别名不冲突即可
在app的urls中要写上
app: path('after/', views.after, name='app01_after_view')
总结心得
今日所学是路由层的知识点,先介绍了请求声明周期流程,看上图;
路由匹配
所谓路由匹配,就是浏览器访问的哪一串进行的页面匹配。
比如 访问 127.0.0.1/login.html/ 地址
整个路由匹配规则访问上述地址,了解了加不加斜杠的问题,不加斜杠的访问,浏览器会做二次访问,第一次不加斜杠,第二次加斜杠访问,访问不到返回404.
然后path,path转换器。
re_path用的最多。正则匹配。
它又分类无名分组,和有名分组,
无名五分组的特点,将获取到的数据当成位置参数传给视图函数。
有名分组的特点就是,有别名,然后将正则别名作为关键字参数传给视图函数。
反向解析
因为路由层随便修改接口,导致页面无法访问,如果想正常访问,减少影响。我认为也跟静态资源一样,理解为动态解析,不过这种所谓的动态解析被称为反向解析
解决的方式就是以下
路由层加了别名 name = '别名' ,后端视图层利用了reverse关键字 reverse('别名'),前端html加了{ % url '别名' %}
无名有名反向解析
就是访问时,有多个不确定的匹配因素,反向解析的时候需要给认为一个具体的值,不给就报错
解决的方式就是 参考反向解析,在反向解析的基础上,在后面多添加一个自定义的字符。前端,路由层,视图层
路由分发
总路由下面管理着子路由,这里的子路由是多个应用。
然后子路由下又可以理解为单独的个体,然后里面含有的路由是应用的各个功能。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2020-09-01 zabbix4.4
2020-09-01 ELK安装