
cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning
讲课嘉宾是Song Han,个人主页 Stanford:https://stanford.edu/~songhan/;MIT:https://mtlsites.mit.edu/songhan/。
1. 深度学习面临的问题:
1)模型越来越大,很难在移动端部署,也很难网络更新。
2)训练时间越来越长,限制了研究人员的产量。
3)耗能太多,硬件成本昂贵。
解决的方法:联合设计算法和硬件。
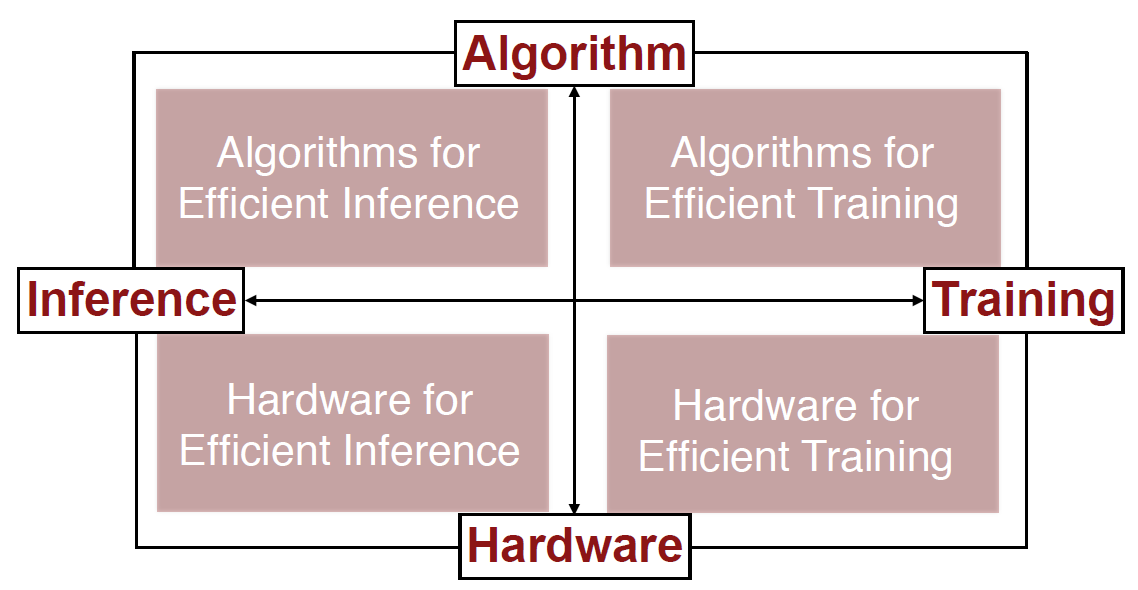
计算硬件可以分为通用和专用两大类。通用硬件又可以分为CPU和GPU。专用硬件可以分为(FPGA和ASIC,ASIC更高效,谷歌的TPU就是ASIC)。
2. Algorithms for Efficient Inference
1)Pruning,修剪掉不那么重要的神经元和连接。第一步,用原始的网络训练;第二步,修剪掉一部分网络;第三步,继续训练剩下的网络。不断重复第二步和第三步。在不损失精度的情况下,网络可以缩小到原来的十分之一(继续缩小精度会变差)。
2)Weight Sharing,权重并不需要那么精确,可以把一些近似的权重看成一样的(比如2.09、2.12、1.92、1.87可以全部看成2)。也是在原始训练基础上,用某种方式简化权重,然后不断训练调整简化权重的方式。在不损失精度的情况下,网络可以缩小到原来的八分之一。
前两种方法可以结合使用,网络可以缩小到原来的百分之几。有个名字Deep Compression。
3)Quantization,数据类型。TPU的设计主要就是优化这一部分。
4)Low Rank Approximation,把大网络拆成一系列小网络。
5)Binary(二元)/Ternary(三元) Net,很疯狂地把权重离散化成(-1,0,1)三种。
6)Winograd Transformation,一种更高效的求卷积的做法。
3. Hardware for Efficient Inference
这个方向各种硬件的共同目的是减少内存的读取(minimize memory access)。硬件需要能用压缩过的神经网络做预测。
EIE(Efficient Inference Engine)(Han et al. ISCA 2016):稀疏权重(扔掉为0的权重)、稀疏激活值(扔掉为0的激活值)、Weight Sharing(4-bit)。
4. Algorithms for Efficient Training
1)Parallelization。CPU按照摩尔定律发展,这些年单线程的性能已经提高的非常缓慢,而核的数量在不断提高。

2)Mixed Precision with FP16 and FP32,正常是用32位计算,但计算权重更新的时候用16位。
3)Model Distillation,用训练的很好的大网络的“软结果”(soft targets)作为标签提供给压缩过的小网络训练。这是Hinton的一篇论文提出的,里面解释了为什么软结果比ground truth更好。
4)DSD(Dense-Sparse-Dense Training),先对原始的稠密的网络做Pruning,训练稀疏的网络后,再Re-Dense出稠密的网络。Han说这是先学习树的枝干,再学习叶子。相比原来的稠密网络,Re-Dense出的精度更高。
5. Hardware for Efficient Training
Computation和Memory bandwidth是影响整体性能的两个因素。
Han对比Nvidia Pascal和Volta,猛吹了一波Volta。。。Volta有120个Tensor Core,非常擅长矩阵运算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号