生成器表达式、yield传值、for循环本质、常见内置函数
for循环本质
- 把in后面的对象加--iter--方法变成迭代器对象
- 对迭代器使用--next--方法
- 取完报错对报错进行处理.
d = {'name':'jason','pwd':123,'hobby':'read'}
res = d.__iter__() # StopIteration
while True:
try:
print(res.__next__())
except StopIteration as e:
break
for i in d:
print(i)
迭代取值与索引取值对比
迭代取值
优点:
1.不依赖于索引的一种通用取值方式
缺点:
1.取值的顺序永远都是固定的从左往右 无法重复获取
索引取值
缺点:
1.需要提供有序容器类型才可取值(不是一种通用的方式)
优点:
1.可以重复取值
生成器对象
本质:
生成器其实就是一个普通函数
在定义阶段就是一个普通函数
def my_ge():
print('first')
yield 123,222,333
print('second')
# yield 456,444,555
# 调用函数:不执行函数体代码 而是转换为生成器(迭代器)
res = my_ge()
ret = res.__next__() # 每执行一个__next__代码往下运行到yield停止 返回后面的数据
print(ret)
ret = res.__next__() # 再次执行__next__接着上次停止的地方继续往后 遇到yield再停止
print(ret)
ps: 当函数体内含有yield关键字 那么在第一次调用函数的时候
并不会执行函数体代码 而是将函数变成了生成器(迭代器)
每执行一个 _ _ next _ _ 代码往下运行到yield停止 返回后面的数据
再次执行 _ _ next _ _ 接着上次停止的地方继续往后 遇到yield再停止
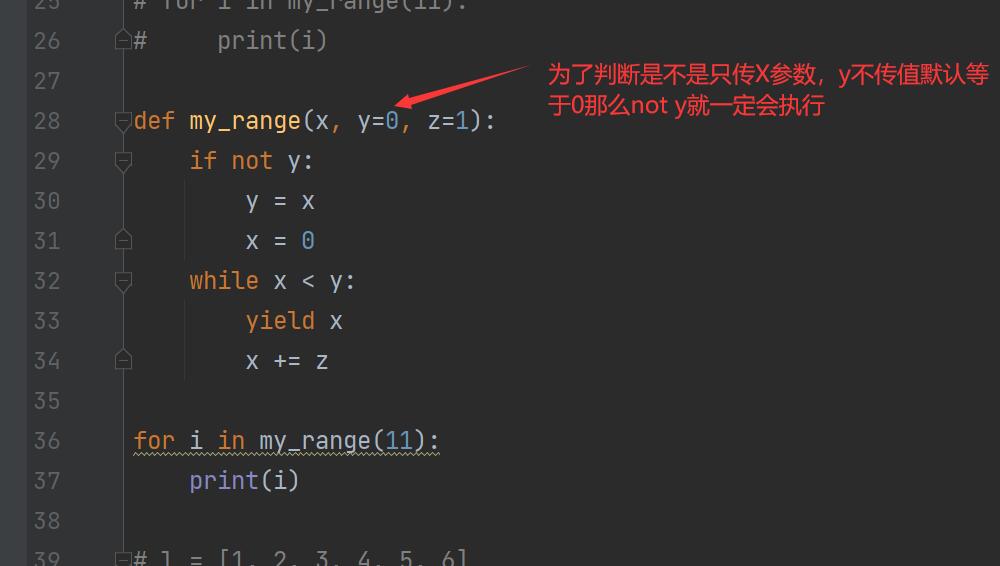
自定义range功能
yield传值(了解)
def eat(name):
print('%s 准备干饭!!!'%name)
while True:
food = yield
print('%s 正在吃 %s' % (name, food))
res = eat('jason') # 并不会执行代码 而是转换成生成器
res.__next__()
res.send('肉包子')
res.send('盖浇饭')
yield与return对比
yield
1.可以返回值(支持多个并且组织成元组)
2.函数体代码遇到yield不会结束而是"停住"
3.yield可以将函数变成生成器 并且还支持外界传值
return
1.可以返回值(支持多个并且组织成元组)
2.函数体代码遇到return直接结束

生成器表达式
-
生成器表达式内部的代码只有在迭代取值的时候才会执行
-
迭代器对象 生成器对象 我们都可以看成是"工厂"
只有当我们所要数据的时候工厂才会加工出"数据"
上述方式就是为了节省空间
面试题
# 求和
def add(n, i):
return n + i
# 调用之前是函数 调用之后是生成器
def test():
for i in range(4):
yield i
g = test() # 初始化生成器对象
for n in [1, 10]:
g = (add(n, i) for i in g)
""" # (1,2,3,4)
第一次for循环
g = (add(n, i) for i in g)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g))
"""
res = list(g)
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23]
#D. res=[21,22,23,24]
常见内置函数
# 1.abs() 绝对值
print(abs(123))
print(abs(-123))
# 2.all() any()
l = [11,22,33,0]
print(all(l)) # 所有的元素都为True结果才是True
print(any(l)) # 所有的元素只要有一个为True结果就为True
# 3.bin() oct() hex() 进制数
print(bin(123))
print(oct(123))
print(hex(123))
# 4.bytes() str()
res = '金牌班 最牛逼'
res1 = bytes(res,'utf8')
print(res1)
res2 = str(res1,'utf8')
print(res2)
res1 = res.encode('utf8')
print(res1)
res2 = res1.decode('utf8')
print(res2)
# 5.callable() 是否可调用(能不能加括号运行)
s1 = 'jason'
def index():
pass
print(callable(s1),callable(index)) # False True
# 6.chr() ord()
print(chr(65)) # 根据ASCII码转数字找字符
print(ord('A')) # 65
# 7.complex() 复数
print(complex(123)) # (123+0j)
8.dir() 查看当前对象可以调用的名字
def index():
pass
print(dir(index))
print(index.__name__)
# 9.divmod()
print(divmod(101,10))
"""总数据100 每页10条 10页"""
"""总数据99 每页10条 10页"""
"""总数据101 每页10条 11页"""
num,more = divmod(233,10)
if more:
num += 1
print('总共需要%s页'%num)
# 10.eval()只能识别简单的语法 exec()可以识别复杂语法 都是将字符串中的数据内容加载并执行
res = """
你好啊
for i in range(10):
print(i)
"""
res = """
print('hello world')
"""
eval(res)
exec(res)
# 11.isinstance() 判断是否属于某个数据类型
print(isinstance(123,float)) # False
print(isinstance(123,int)) # True
# 12.pow()
print(pow(4,3))
# 13.round()
print(round(4.8))
print(round(4.6))
print(round(8.5))
# 14.sum()
l = [11,22,333,44,55,66]
print(sum(l))

面向过程编程(理论)
面向过程编程就是根据需求一步一步计划做的流水线形式的编程,优点是可控,按照设计的流程一点点运行,缺点是一旦要修改,牵一发而动全身。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号