编译器数据模型
编程语言上的32位与64位差异主要体现在基本类型的位长上。C/C++等语言仅仅定义了这些基本数据类型之间的关系,并没有严格定义它们的字长。不同操作系统平台上,根据编译器不同的实现,它们的字长如下表所示:
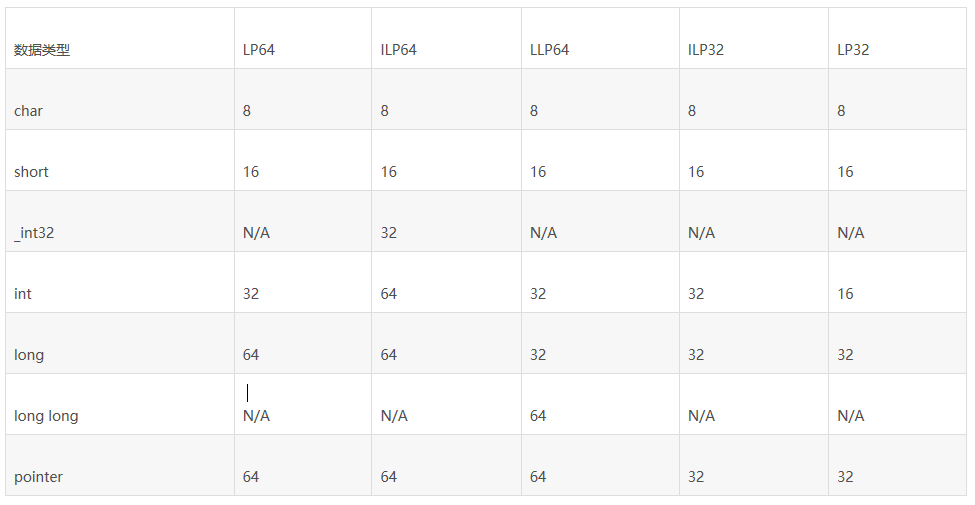
其中,LP64,ILP64,LLP64是64位平台上的字长模型,ILP32和LP32是32位平台上的字长模型。LP64指long和pointer是64位,ILP64指int、long和pointer是64位,LLP64指long long和pointer是64位,ILP32指int、long和pointer是32位,LP32指long和pointer是32位的。32位windows采用的是ILP32数据模型,64位windows采用的是LLP64数据模型,故在windows x64下sizeof(long)
= 4 (MSVC,x64),而其它x64平台使用gcc、clang得到的结果则是8。
Windows上的32位程序设计和64位程序设计最大的不同(亦ILP32和LLP64的不同),就在于指针的长度由32位变成了64位。Win32 API在很多情况下,都需要将整数转换成指针或者相反。在 32 位的硬件上不会有问题,其中指针的大小和整数的大小是相同的,但在 64 位的硬件上却完全不一样。为此微软搞了个所谓的“多态类型”:对于特定的精度,可以使用固定精度的数据类型。不管处理器的词大小如何,它们的大小都是一致的。此外,当需要数据类型的精度随着处理器词大小变化时,可以使用指针精度数据类型,比如ULONG_PTR。
参考:
https://blog.csdn.net/rrrfff/article/details/7340074

 浙公网安备 33010602011771号
浙公网安备 33010602011771号