logstash、ELK
引言
三张图引出logstash。
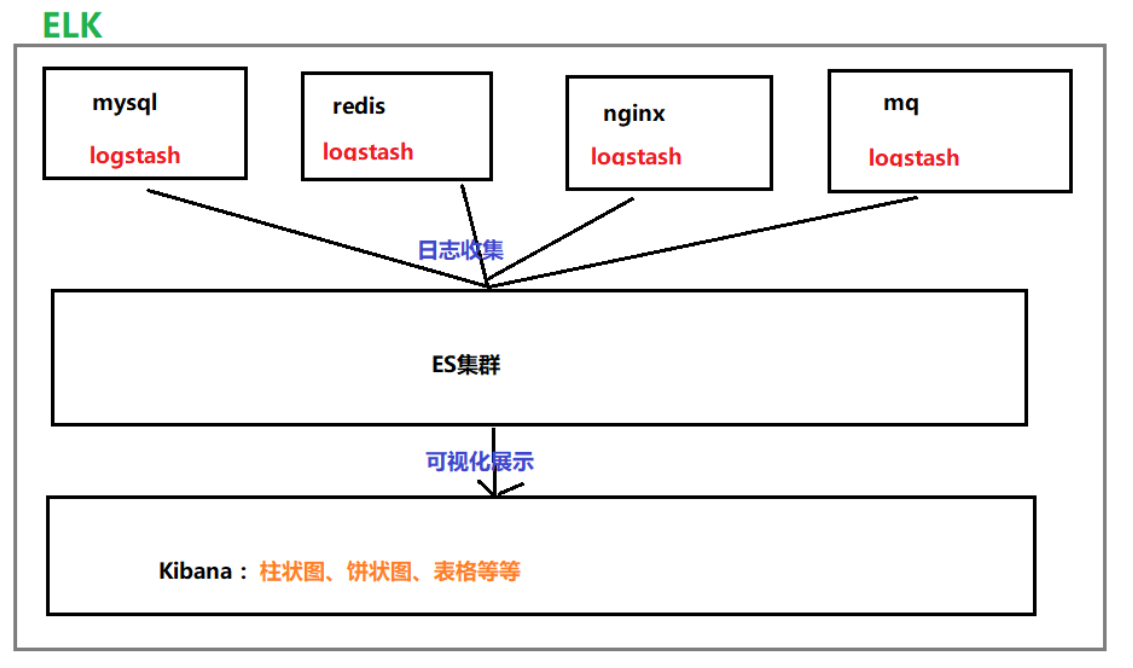
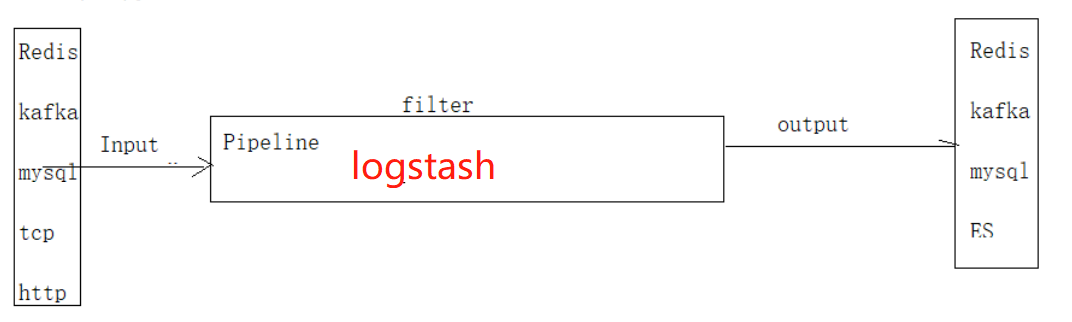
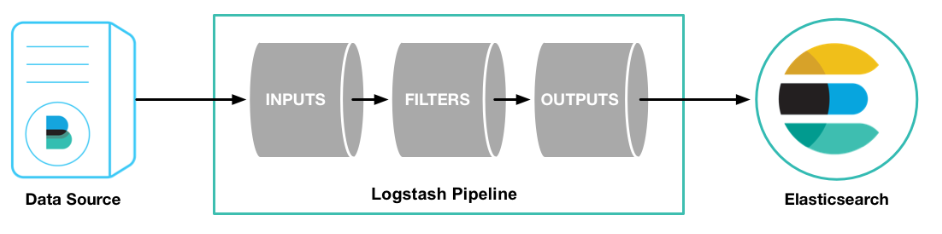
大纲
1、logstash是什么?
2、logstash常用用法举例
3、以一个简单的例子体验一下ELK
一、logstash是什么
Logstash 是一个支持多输入和多输出的非常强大的数据采集引擎。能够动态地采集、转换和传输数据,不受格式或复杂度的影响。
输入
采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择,可以同时从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
输出
选择您的存储库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
筛选
实时解析和转换数据
同时支持数据的过滤功能,具体可参考过滤器库
二、如何使用logstash
使用logstash,主要是对输入源和输出源的设置(输入源和输出源可同时存在多个)。
可设置在配置文件中,也可直接加在命令行后边。格式分别为:
# 一、命令行
bin/logstash -e 'input { 输入设置项 } output { 输出设置项 }'
# 二、配置文件
#建立新的配置文件、在文件中配置input、output
mv logstash.conf xxx.conf
#详细配置如下
bin/logstash -f config/xxx.conf
举几个栗子:
1)标准输入和标准输出
bin/logstash -e 'input { stdin { } } output { stdout {} }'
启动成功之后输入字符串,会看到响应输出

2)文件输入和ElasticSearch输出
配置文件file.conf
input {
file{
path => "/tmp/temp.txt" #收集文件内容
type => "temp"
start_position => "beginning" #记录上次收集的位置
}
}
output {
elasticsearch {
hosts => ["192.168.0.112:9200","192.168.0.112:9201","192.168.0.112:9202"] #写入elasticsearch的地址
index => "temp-%{+YYYY.MM.dd}" #定义索引的名称
}
stdout { }
}
三、ELK
使用一个小例子对ELK进行简单应用。
通过logstash读取user.json文件,将数据导入到elasticsearch中,然后通过kibana读取elasticsearch中数据进行可视化展示。统计各个年代用户分布和男女比例。
1)创建文件并初始化模拟数据
cd /opt/apps/data
touch user.json
======================================
# 添加如下数据
{"name":"AAA","sex":"男","year":"80后"}
{"name":"BBB","sex":"男","year":"90后"}
{"name":"CCC","sex":"女","year":"90后"}
{"name":"DDD","sex":"男","year":"00后"}
{"name":"EEE","sex":"女","year":"00后"}
{"name":"FFF","sex":"女","year":"10后"}
2)配置logstash
cd ./logstash-7.8.0/conf
touch file.conf
========================
# 添加如下配置文件
input {
file {
path => "/opt/apps/data/user.json" #收集文件内容
type => "user"
start_position => "beginning" #记录上次收集的位置
codec => json
}
}
output {
elasticsearch {
hosts => ["192.168.0.112:9200","192.168.0.112:9201","192.168.0.112:9202"] #写入elasticsearch的地址
index => "user-%{+YYYY.MM.dd}" #定义索引的名称
}
stdout { }
}
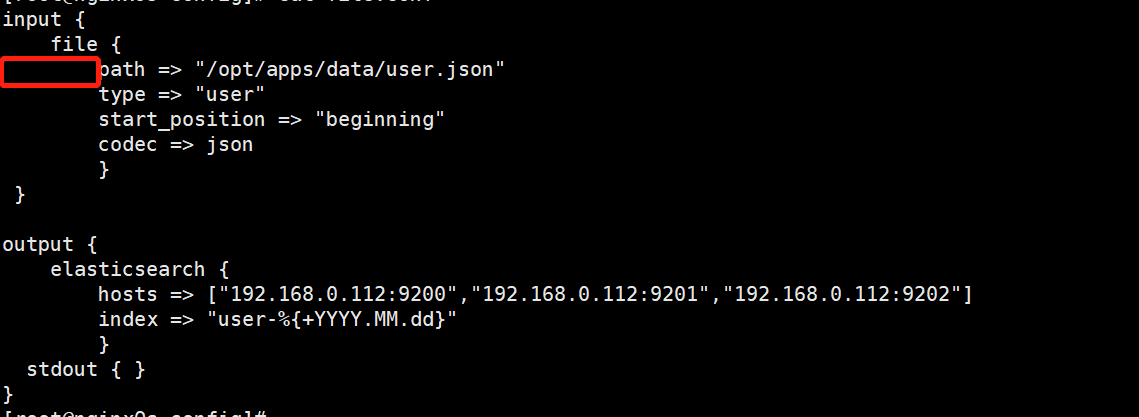
检查配置文件格式是否正确命令
bin/logstash -f config/file.conf -t
如下测试出来的错表示配置文件的红框处必须为Tab。类似的换行后都必须为Tab进行缩进(具体错误具体分析)

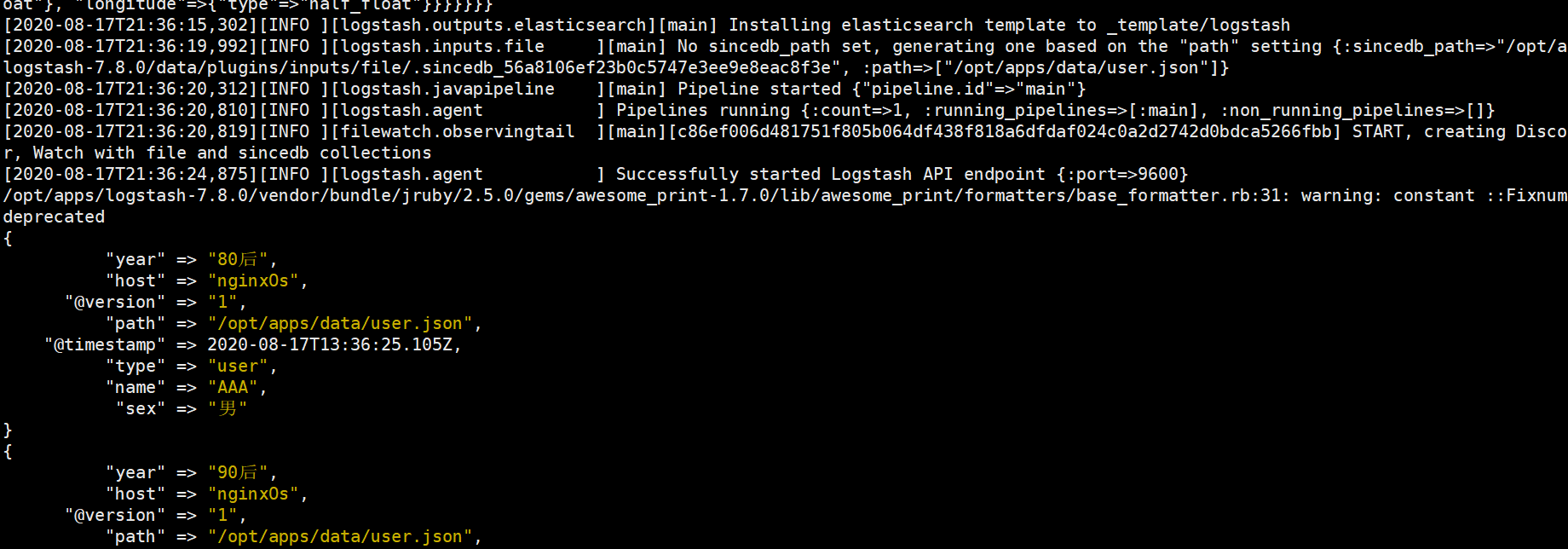
3)启动logstash导入数据
# 前台启动
./bin/logstash -f ./config/file.conf
# 后台启动
nohup ./bin/logstash -f ./config/file.conf &
启动后,可以发现已经开始读取了文件内容。如果我们再实时向user.json中添加数据,发现也会读取到,证明logstash会实时监测文件内容。
添加数据命令:
echo '{"name":"ZZZ","sex":"男","year":"00后"}' >> user.json
注意:如果手动修改文件会存在全部重新读取的问题。
4)kibana可视化
注:本文使用7.8.0版本
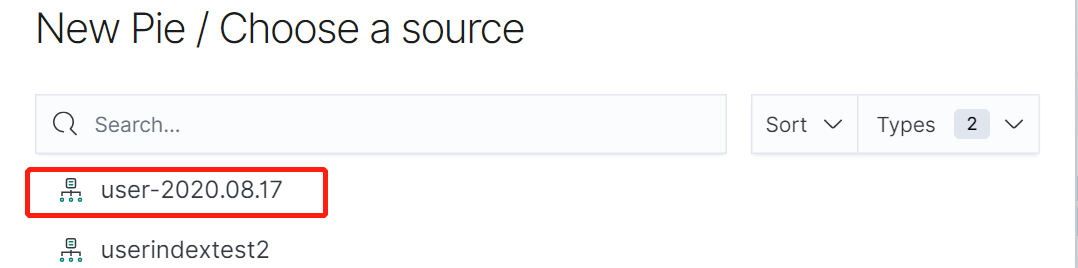
1)首先通过Index patterns创建索引Pattern。
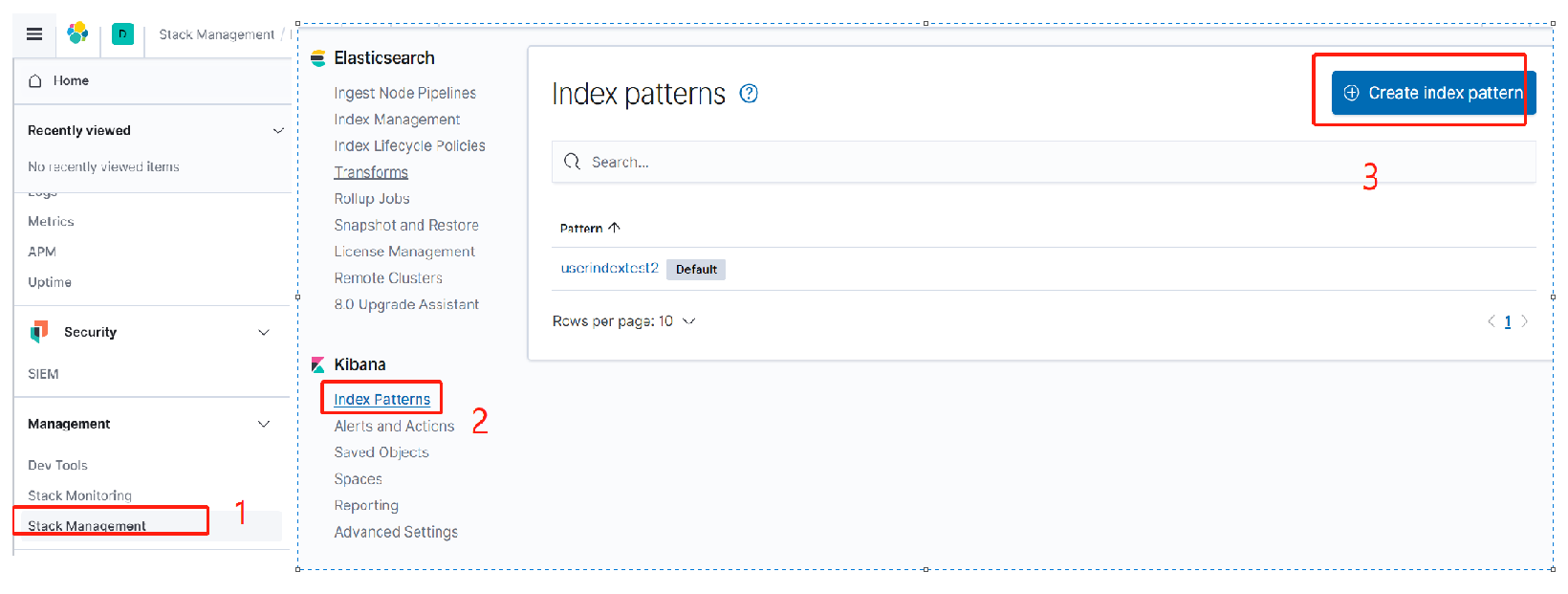
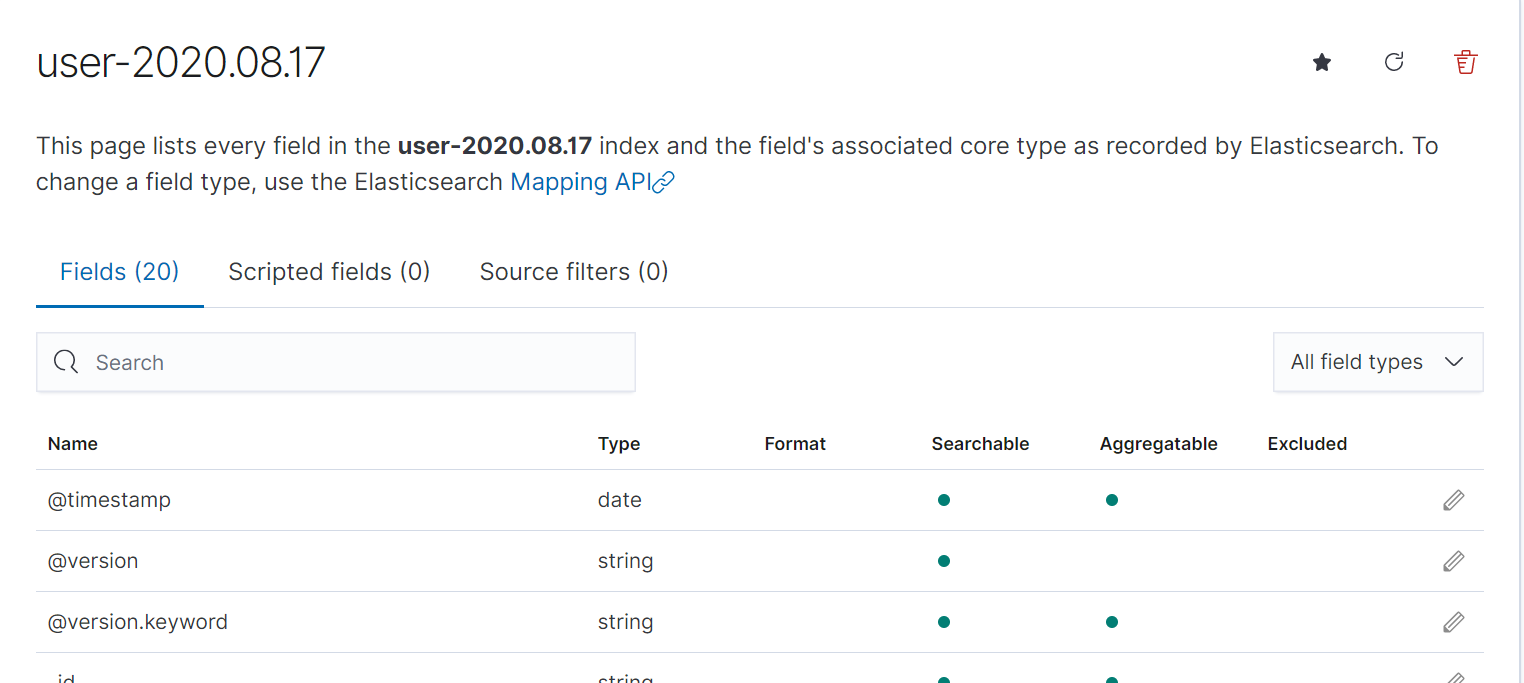
我们选择user-2020.08.17索引。创建后如下图所示:
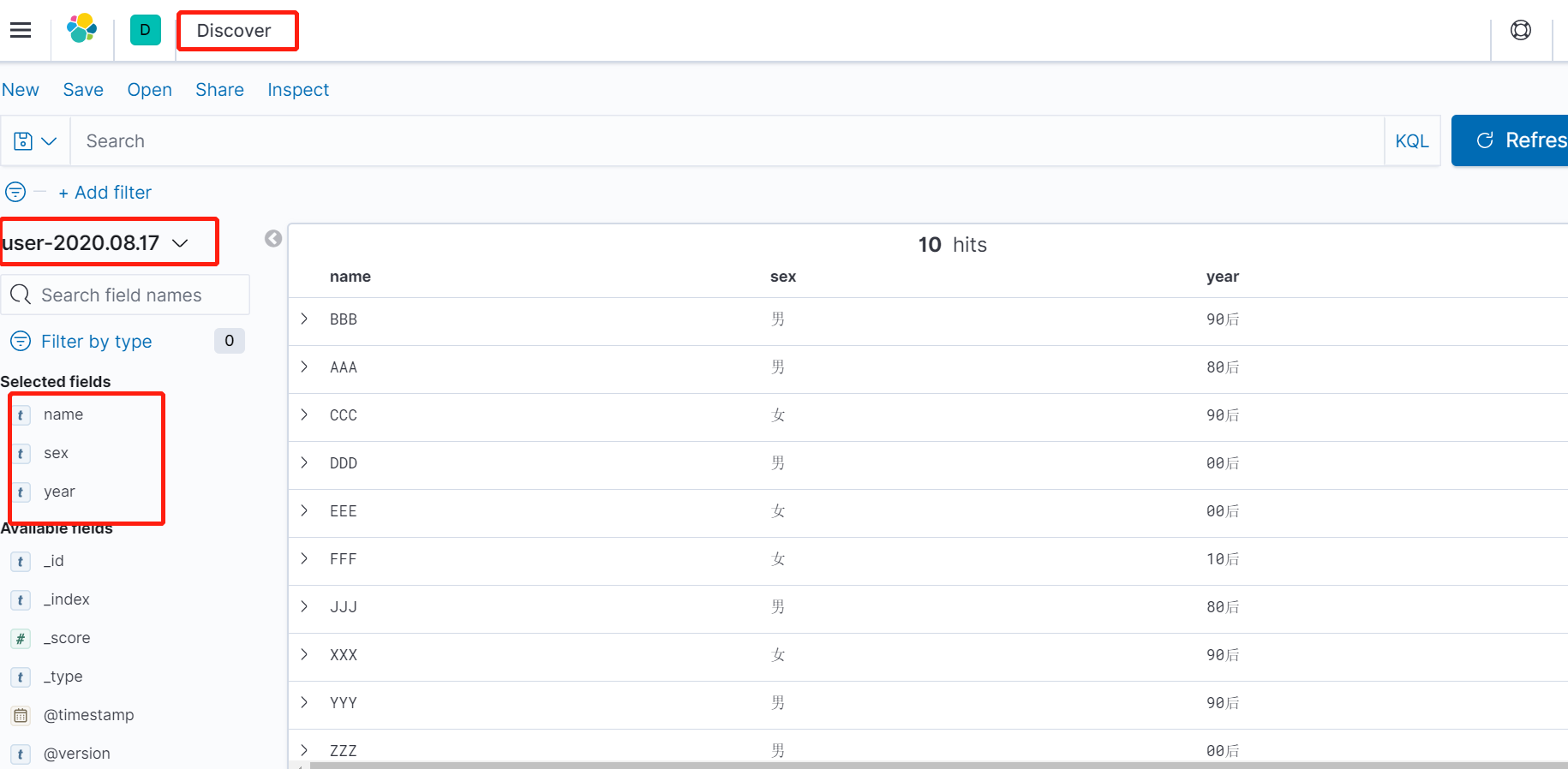
创建成功之后,我们可以通过Discover看板进行数据预览。
2)通过Visualize创建视图
支持多种类的图形:
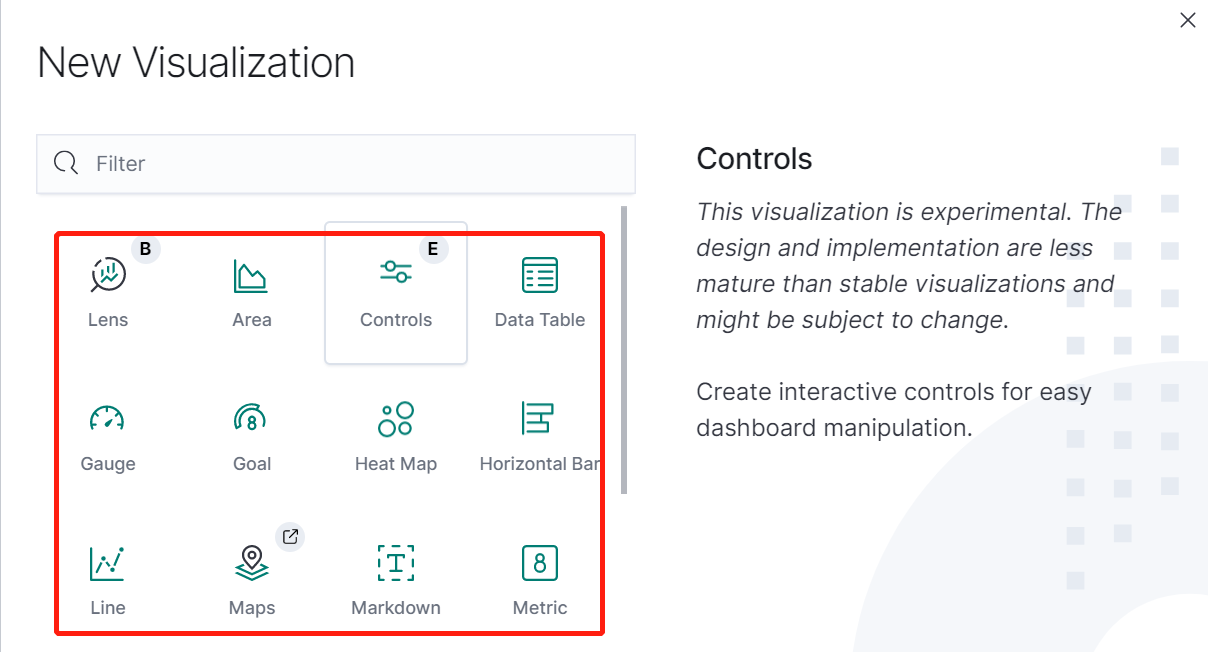
选择刚刚添加的索引:
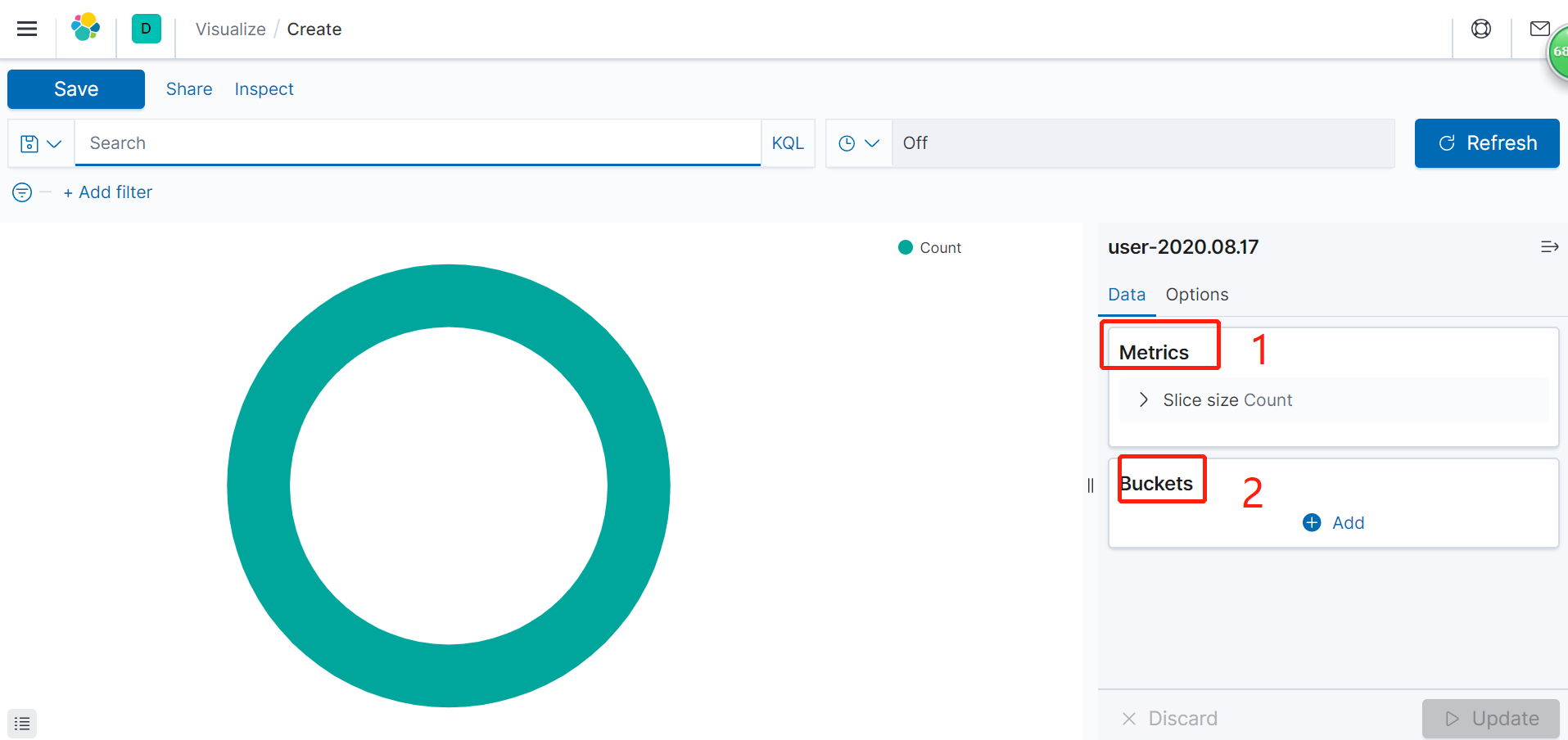
进入视图设置界面。总共分两部分。1是设置统计分类(count、sum、average等),2是选择统计的字段:
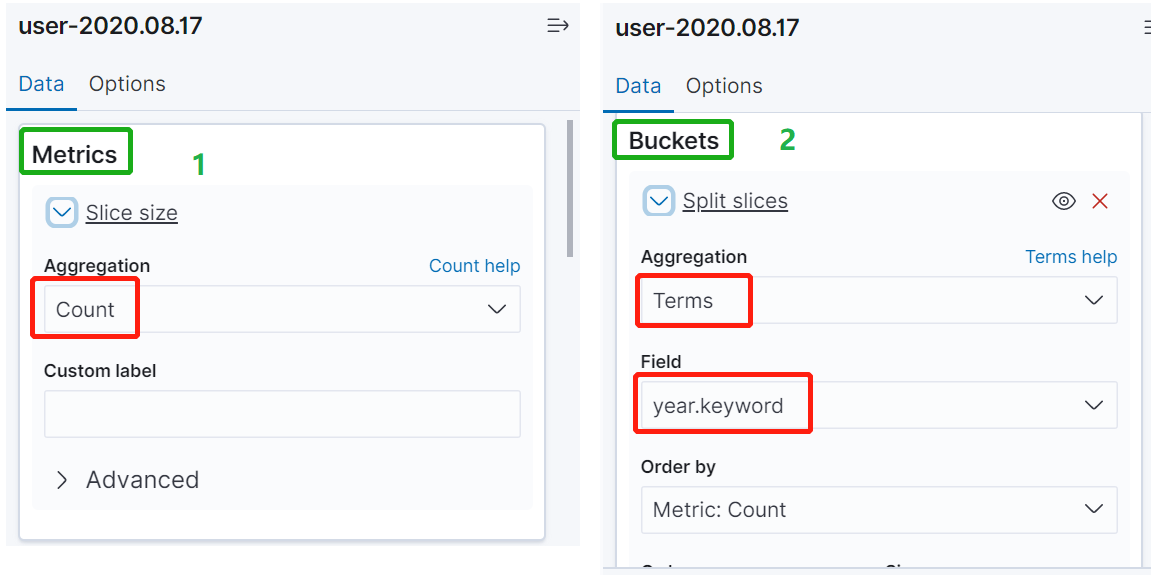
比如我们统计各年代的人数分布,则进行如下设置即可。
最终呈现出的效果就如2所示:
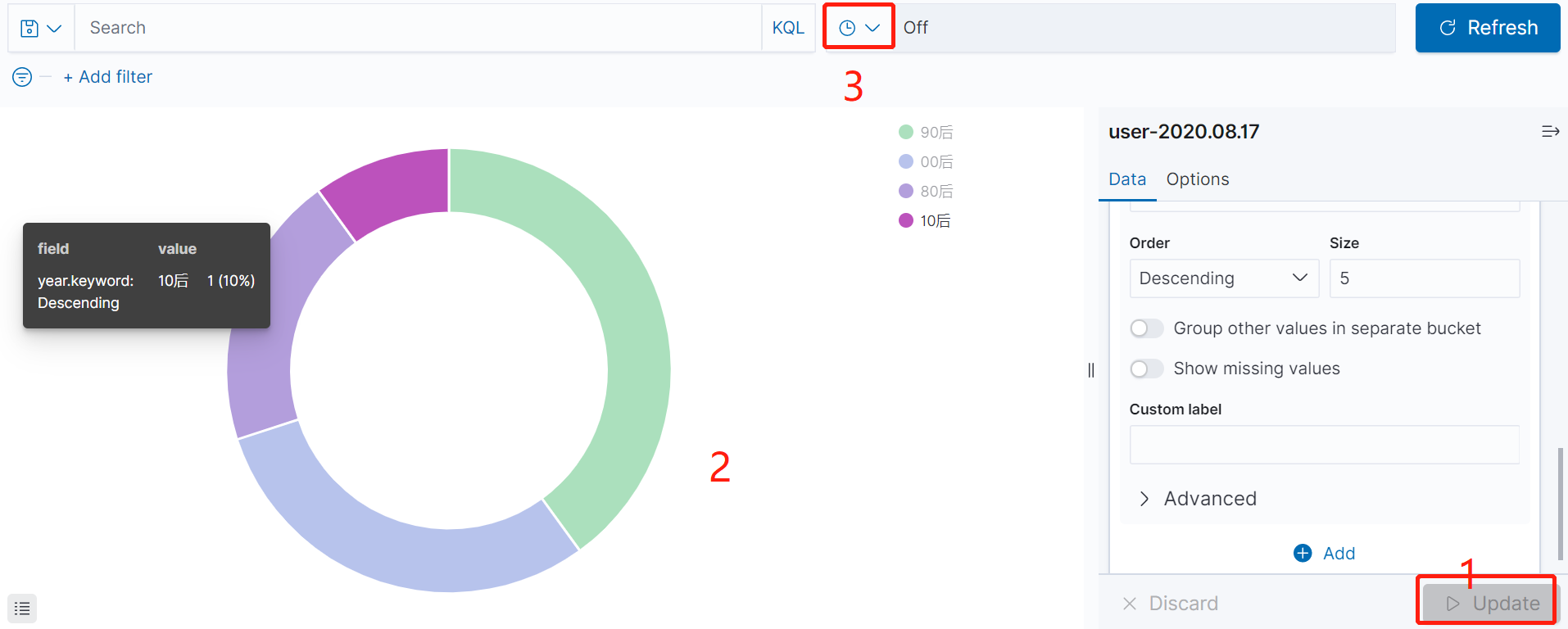
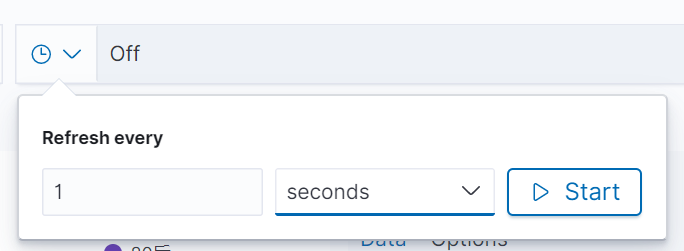
同时我们也可以通过3所示设置刷新频率:
同理,我们也可以生成一个年龄分布统计视图。
最后,点击“Save”保存视图。视图可以理解为一个临时结果,最终是要生成仪表盘。
3)通过Dashboard看板生成仪表盘
选择刚刚生成的Visualize,生成仪表盘。
最终生成仪表盘效果如下:
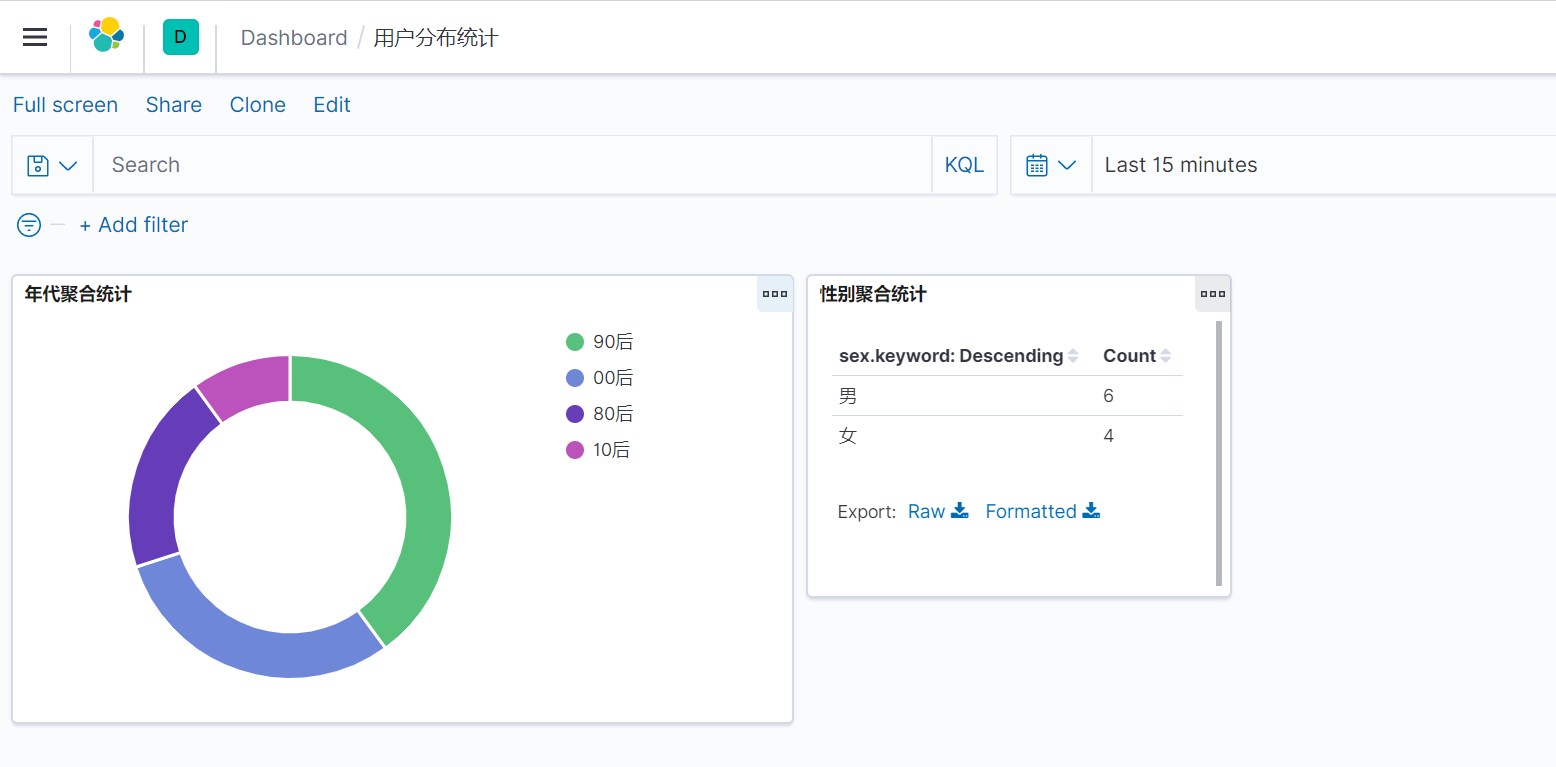
这样,源数据改变后,通过仪表盘即可实时的监测到,而不用每次都去统计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号