Pandas库的基本使用
1. 认识Pandas
- Pandas库是Python的免费、开源的第三方库;
- Pandas是Python数据分析必不可少的工具之一;
- Pandas为Python提供了高性能、易于使用的数据结构:Series对象和DataFrame对象;
- Pandas库是基于NumPy库和Matplotlib库开发而来;
- Pandas实现了数据分析的五个重要环节:加载数据、整理数据、操作数据、构建数据模型、分析数据。
Pandas的主要特点:
- 它提供了一个简单、高效、带有默认标签(也可以自定义标签)的DataFrame对象;
- 能够快速的从不同格式的文件中加载数据(如Excel、CSV、SQL文件),然后将其转换为可处理的对象;
- 能够按数据的行、列标签进行分组,并对分组后的对象执行聚合和转换操作;
- 能够很方便地实现数据归一化操作和缺失值处理;
- 能够很方便地对DataFrame的数据列进行增加、修改或删除的操作;
- 能够处理不同格式的数据集,比如矩阵数据、异构数据表、时间序列等;
- 提供了多种处理数据集的方式,比如构建子集、切片、过滤、分组以及重新排序等。
Pandas的主要优势:
- Pandas的DataFrame和Series构建了适用于数据分析的存储结构;
- Pandas简洁的API能够让你专注于代码的核心层面;
- Pandas实现了与其它库的集成,比如SciPy、scikit-learn和Matplotlib;
- Pandas提供了完善资料支持,以及良好的社区环境。
2.对象的创建
2.1 一维对象的创建:Series
2.1.1字典创建法
等同于NumPy中的np.array(),Pandas中,可以通过pd.Series(),将Python字典转化为Series对象。
dict_v = {'a': 1, 'b': 2, 'c': 3}
sr = pd.Series(dict_v)
print(sr)
'''
a 1
b 2
c 3
dtype: int64
'''
2.1.2 数组创建法(推荐)
最直接的创建方法即直接给pd.Series()参数,需要传入两个参数:
- values:列表、数组(NumPy)、张量(torch)均可
- index:键(索引)(可以省略,省略后默认索引是从0开始的顺序数字),行标签
语法:pd.Series( v, index=k)
import pandas as pd
import numpy as np
v = np.array([1, 2, 3, 4, 5])
k = ['a', 'b', 'c', 'd', 'e']
sr = pd.Series(v, index=k)
print(sr)
'''
a 1
b 2
c 3
d 4
e 5
dtype: int64
'''
# index可以省略
sr1 = pd.Series(v)
print(sr1)
'''
0 1
1 2
2 3
3 4
4 5
dtype: int64
'''
2.2 一维对象的属性
一维对象有两个属性:values和index
注意:无论values传入的是什么值,列表、数组还是张量,最终输出的values属性都是数组形式。
所以Pandas对象默认的存储方式是NumPy数组。
这说明Pandas是建立在NumPy基础上的库,没有NumPy数组库就没有Pandas数据处理库。
当想要从Pandas退化为NumPy时,查看其values属性即可得到数据的数组形式。
v = np.array([1, 2, 3, 4, 5])
k = ['a', 'b', 'c', 'd', 'e']
sr = pd.Series(v, k)
print(sr.values) # [1 2 3 4 5]
print(sr.index) # Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
2.3 二维对象的创建:DataFrame
2.3.1 字典创建法
用字典创建法创建二维对象时,必须基于多个Series对象,每一个Series对象都是一列数据,相当于一列一列数据作拼接。
- 创建Series对象时,字典的键是index,其延展方向是数值方向,因为它算一列数据
- 创建DataFrame对象时,字典的键是columns,其延展方向是水平方向,因为它算一列一列的数据进行拼接
# 创建一个小白鼠实验结果表
# 创建第一个Series对象
v = ['雌', '雄', '雌', '雄']
k = ['1号', '2号', '3号', '4号']
s = pd.Series(v, index=k)
print(s)
'''
1号 男
2号 女
3号 男
4号 女
dtype: object
'''
# 创建第二个Series对象
v = ['异常', '良好', '优秀', '异常']
k = ['1号', '2号', '3号', '4号']
s2 = pd.Series(v, index=k)
print(s2)
'''
1号 异常
2号 良好
3号 优秀
4号 异常
dtype: object
'''
# 创建DataFrame对象
df = pd.DataFrame({'性别': s, '实验结果': s2})
print(df)
'''
性别 实验结果
1号 雌 异常
2号 雄 良好
3号 雌 优秀
4号 雄 异常
'''
由上述实例可清楚的看到,DataFrame对象就是把一列列的Series对象拼接起来。
可能有人想问了,如果两个Series对象的index也就是行标签不一致怎么办?
答:会取所有Series对象的并集,并且没有的值会用NaN(缺失值)来代替。
# 第一个Series对象的4号改为6号,运行结果如下:
df = pd.DataFrame({'性别': s, '实验结果': s2})
print(df)
'''
性别 实验结果
1号 雌 异常
2号 雄 良好
3号 雌 优秀
4号 NaN 异常
6号 雄 NaN
'''
而在我们平常的大数据处理时,每一个列(Series对象)都是一个特征,每一行都是一个个体。
2.3.2 数组创建法
最直接的创建方法即直接给DataFrame函数参数,需要传入三个参数:
- values:数组(可以用值矩阵)
- index:行标签(可不写,省略后默认从0开始的顺序数字)
- columns:列标签(可不写,省略后默认从0开始的顺序数字)
v = np.array([[16, '男'], [18, '女'], [22, '女'], [17, '男']])
k = ['同学1', '同学2', '同学3', '同学4']
c = ['年龄', '性别']
df = pd.DataFrame(v, index=k, columns=c)
print(df)
'''
年龄 性别
同学1 16 男
同学2 18 女
同学3 22 女
同学4 17 男
'''
有的人可能发现了,在该例子中,values我们传入了一个值矩阵,但是用了两种不同的数据类型,这是不是违反了数组的特性?
答:并没有,因为在这里,数组默默把数字转为了字符串形式,其实values就是一个字符串型数组。
2.4 二维对象的属性
二维对象有三个属性:values、index、columns
v = np.array([[16, '男'], [18, '女'], [22, '女'], [17, '男']])
k = ['同学1', '同学2', '同学3', '同学4']
c = ['年龄', '性别']
df = pd.DataFrame(v, index=k, columns=c)
print(df.values)
'''
[['16' '男']
['18' '女']
['22' '女']
['17' '男']]
'''
print(df.index) # Index(['同学1', '同学2', '同学3', '同学4'], dtype='object')
print(df.columns) # Index(['年龄', '性别'], dtype='object')
注意这里输出的df.values,很明显的看出数字已经被转化成了字符串,那如果我们想获得第一列的数字呢?
答:需要先提取这一列后,再用.astype(int)转为整型数组
a1 = df.values[:,0]
print(a1) # ['16' '18' '22' '17']
a2 = a1.astype(int)
print(a2) # [16 18 22 17]
补充:Pandas是用来处理数据的,为了兼容大数据的特性,它不像NumPy数组一样只能存储一种类型的数据,它是由一列列对象构成的新的对象,每一列的存储方式都是独立的,因此可以存储多种类型数据。
3. 对象的索引
Pandas的索引分为两种:显式索引和隐式索引。
显式索引是使用Pandas对象提供的索引,如上述例子中的:年龄、性别等。
隐式索引是使用数组本身自带的0开始的索引。
为了防止显式索引是整数导致显式索引和隐式索引混合出乱子,Pandas提供了两种索引器:loc(显式)、iloc(隐式),告诉程序我使用的是哪种索引。
在这里,建议大家以后就用索引器,即便不会混淆也用,因为二维对象的索引是必须加索引器的。
3.1 一维对象的索引
创建一个一维对象:
v = [12, 16, 18, 22]
k = ['同学1', '同学2', '同学3', '同学4']
sr = pd.Series(v, index=k)
print(sr)
'''
同学1 12
同学2 16
同学3 18
同学4 22
dtype: int64
'''
3.1.1 访问元素
用显式索引的方式访问元素:
这里的sr.loc['同学1']完全可以写成sr['同学1'],因为不是整数不会出现显式隐式混淆的情况。
# 访问元素
print(sr.loc['同学2']) # 16
# 花式索引
print(sr.loc[['同学2', '同学4']])
'''
同学2 16
同学4 22
dtype: int64
'''
用隐式索引的方式访问元素:
同样地,这里的sr.iloc[1]可以写成sr[1]。
# 访问元素
print(sr.iloc[1]) # 16
# 花式索引
print(sr.iloc[[1, 3]])
'''
同学2 16
同学4 22
dtype: int64
'''
3.1.2 访问切片
注意,在NumPy中,假设有这样一个切片:arr[0 : 3],意思是切片0-3不包括3的数组,这种左闭右开的用法与Pandas的隐式索引是一样的,而当你使用Pandas的显式索引时,使用的是左闭右闭,显然更好用、更直观。
用显式索引的方式切片:
# 切片
print(sr.loc['同学1':'同学3']) # 等同于sr['同学1':'同学3']
'''
同学1 12
同学2 16
同学3 18
dtype: int64
'''
用隐式索引的方式切片:
# 切片
print(sr.iloc[0:3]) # 等同于sr[0:3]
'''
同学1 12
同学2 16
同学3 18
dtype: int64
'''
3.1.3 副本和视图
当Pandas不用索引器时,其用法与NumPy的索引切片用法一模一样,包括视图和副本的用法也是一样的。
切片生成的是视图,修改切片内容会影响到原数据内容。
s = sr.loc['同学1':'同学3']
s.loc['同学2'] = 100
print(sr)
'''
同学1 12
同学2 100
同学3 18
同学4 22
dtype: int64
'''
对象赋值也只是绑定,修改其内容也会影响原数据内容。
cr = sr
cr.loc['同学4'] = 200
print(sr)
'''
同学1 12
同学2 16
同学3 18
同学4 200
dtype: int64
'''
若想获得一个新的副本,使其修改后不会影响原数据,使用.copy()方法
cr = sr.copy()
cr.loc['同学4'] = 200
print(sr)
'''
同学1 12
同学2 16
同学3 18
同学4 22
dtype: int64
'''
3.2 二维对象的索引
在二维对象中,必须使用索引器,即便不会混淆。
创建一个二维对象:
i = ['1号', '2号', '3号', '4号']
v1 = ['雄', '雌', '雌', '雄']
v2 = ['异常', '正常', '正常', '异常']
sr1 = pd.Series(v1, index=i)
sr2 = pd.Series(v2, index=i)
df = pd.DataFrame({ '性别': sr1, '状态': sr2})
print(df)
'''
性别 状态
1号 雄 异常
2号 雌 正常
3号 雌 正常
4号 雄 异常
'''
3.2.1 访问元素
由于二维对象是数据矩阵,所以在访问时,需要输入列信息和行信息进行定位。
也正是因为如此,在NumPy数组中,花式索引输出的是一个向量(一维数组),而在Pandas中,为了使其行列标签的信息不丢失,只能以二维对象的形式输出。
用显式索引的方式访问元素:
# 访问元素
print(df.loc['2号', '状态']) # 正常 (不使用索引器直接报错)
# 花式索引
print(df.loc[['2号', '4号'], ['性别', '状态']])
'''
性别 状态
2号 雌 正常
4号 雄 异常
'''
用隐式索引的方式访问元素:
# 访问元素
print(df.iloc[1, 1]) # 正常
# 花式索引
print(df.iloc[[1, 3], [0, 1]])
'''
性别 状态
2号 雌 正常
4号 雄 异常
'''
3.2.2 访问切片
用显式索引的方式访问切片:
# 切片
print(df.loc['1号':'3号', '状态'])
'''
1号 异常
2号 正常
3号 正常
Name: 状态, dtype: object
'''
# 提取二维对象的行
print(df.loc['2号',:]) # ,:可以省略,即:df.loc['2号']
'''
性别 雌
状态 正常
Name: 2号, dtype: object
'''
# 提取二维对象的列
print(df.loc[:,'状态']) # 也可以这样写:df['状态']
'''
1号 异常
2号 正常
3号 正常
4号 异常
Name: 状态, dtype: object
'''
用隐式索引的方式切片:
# 切片
print(df.iloc[0:3, 1])
'''
1号 异常
2号 正常
3号 正常
Name: 状态, dtype: object
'''
# 提取二维对象的行
print(df.iloc[1,:]) # ,:可以省略,即:df.iloc[1]
'''
性别 雌
状态 正常
Name: 2号, dtype: object
'''
# 提取二维对象的列
print(df.iloc[:,1])
'''
1号 异常
2号 正常
3号 正常
4号 异常
Name: 状态, dtype: object
'''
注意两点:
- 在显式索引和隐式索引中,提取二维对象的行时,可以省略前面的
,:,和NumPy用法一样。 - 在显式索引中,提取二维对象的列时,可以直接写成
df['列名'],隐式索引不行,且不可以加索引器,这是因为在Pandas二维对象中,列标签本事就是键,本事就可以精确定位信息。(该方法常用,建议一直用)
4. 对象的变形
4.1 转置
一般我们在进行数据分析时,默认大数据格式是列是特征,行是个体。
但有时提供的大数据很畸形,行是特征,列是个体,我们必须要对其进行转置。
# 创建畸形df
v = [[12,16,22,18], ['女', '男', '男', '女']]
i = ['年龄', '性别']
c = ['同学A', '同学B', '同学C', '同学D']
df = pd.DataFrame(v, index=i, columns=c)
print(df)
'''
同学A 同学B 同学C 同学D
年龄 12 16 22 18
性别 女 男 男 女
'''
# 转置
df_t = df.T
print(df_t)
'''
年龄 性别
同学A 12 女
同学B 16 男
同学C 22 男
同学D 18 女
'''
4.2 翻转
对象的翻转分为左右翻转和上下翻转,且必须使用隐式索引。
'''
年龄 性别
同学A 12 女
同学B 16 男
同学C 22 男
同学D 18 女
'''
# 左右翻转
df_lr = df_t.iloc[:, ::-1]
print(df_lr)
'''
性别 年龄
同学A 女 12
同学B 男 16
同学C 男 22
同学D 女 18
'''
# 上下翻转
df_ud = df_lr.iloc[::-1]
print(df_ud)
'''
性别 年龄
同学D 女 18
同学C 男 22
同学B 男 16
同学A 女 12
'''
4.3 重塑
因为对象不同于数组,它是有行列标签的,所以就不能使用.reshape()。
但是前文提到,对象无非就是下层对象的拼接,多个Series对象拼接成一个DataFrame对象。
所以对象的重塑就是将Series对象并入DataFrame对象,或者从DataFrame对象中切除Series对象。
'''
年龄 性别
同学A 12 女
同学B 16 男
同学C 22 男
同学D 18 女
'''
i = ['同学A', '同学B', '同学C', '同学D']
v = ['001','002','003','004']
sr1 = pd.Series(v, index=i)
print(sr1)
'''
同学A 001
同学B 002
同学C 003
同学D 004
dtype: object
'''
# 把Series对象并入DataFrame
df_t['学号'] = sr1
print(df_t)
'''
年龄 性别 学号
同学A 12 女 001
同学B 16 男 002
同学C 22 男 003
同学D 18 女 004
'''
# 把Series对象切出DataFrame
sr2 = df_t['年龄']
print(sr2)
'''
同学A 12
同学B 16
同学C 22
同学D 18
Name: 年龄, dtype: object
'''
4.4 拼接
Pandas中有一个函数:pd.concat(),与np.concatenate()语法相似。
# 创建两个Serires对象
v1 = [12,14,16,18]
v2 = [3,5,7]
k1 = ['1号', '2号', '3号', '4号']
k2 = ['4号', '5号', '6号']
sr1 = pd.Series(v1, index=k1)
sr2 = pd.Series(v2, index=k2)
print(sr1)
'''
1号 12
2号 14
3号 16
4号 18
dtype: int64
'''
print(sr2)
'''
4号 3
5号 5
6号 7
dtype: int64
'''
# 拼接
sr3 = pd.concat([sr1, sr2])
print(sr3)
'''
1号 12
2号 14
3号 16
4号 18
4号 3
5号 5
6号 7
dtype: int64
'''
注意,这里有两个4号重复出现,说明Pandas对象的属性放弃了集合与字典索引的“不可重复”特性。
- 一维对象与二维对象的合并:
可以理解为:给二维对象加上一列或者一行,因此不需使用pd.concat()函数,只需要借助【3.2二维对象的索引】和【4.3重塑】即可。
- 对于两个二维对象之间的合并,和一维对象一样,但是要多加一个参数
axis,当axis=0表示在列的方向上合并(添加列特征),当axis=1表示在行的方向上合并(添加行个体)。
5. 对象的运算
5.1 对象与系数之间的运算
一维对象与系数的运算:
sr = pd.Series([1,2,3], index=['1号','2号','3号'])
print(sr)
'''
1号 1
2号 2
3号 3
dtype: int64
'''
# 加法/减法
print(sr + 1)
'''
1号 2
2号 3
3号 4
dtype: int64
'''
# 乘法/除法
print(sr * 10)
'''
1号 10
2号 20
3号 30
dtype: int64
'''
# 平方
print(sr ** 2)
'''
1号 1
2号 4
3号 9
dtype: int64
'''
二位对象与系数的运算:
v = [[53,'女'], [64,'男'], [72,'男']]
df = pd.DataFrame(v, index=['1号', '2号', '3号'],columns=['年龄','性别'])
print(df)
'''
年龄 性别
1号 53 女
2号 64 男
3号 72 男
'''
# 对年龄进行+-*/
df['年龄'] = df['年龄']*10
print(df)
'''
年龄 性别
1号 530 女
2号 640 男
3号 720 男
'''
5.2 对象与对象之间的运算
对象做运算,两个对象之间的维度可以不同(会用缺失值补充未知信息),但必须保证其都是数字型对象。
一维对象之间的运算:
# 创建sr1
v1 = [10, 20, 30, 40]
k1 = ['1号', '2号', '3号', '4号']
sr1 = pd.Series(v1, index=k1)
print(sr1)
'''
1号 10
2号 20
3号 30
4号 40
dtype: int64
'''
# 创建sr2
v2 = [5, 6, 7]
k2 = ['1号', '2号', '3号']
sr2 = pd.Series(v2, index=k2)
print(sr2)
'''
1号 5
2号 6
3号 7
dtype: int64
'''
# + - * / **
print(sr1 + sr2)
'''
1号 15.0
2号 26.0
3号 37.0
4号 NaN
dtype: float64
'''
二维对象之间的运算:
# 创建df1和df2
v1 = [[10, '女'], [20, '男'], [30, '男'], [40, '女']]
v2 = [1, 2, 3, 5]
i1 = ['1号', '2号', '3号', '4号']
c1 = ['年龄', '性别']
i2 = ['1号', '2号', '3号', '6号']
c2 = ['学号']
df1 = pd.DataFrame(v1, index=i1, columns=c1)
df2 = pd.DataFrame(v2, index=i2, columns=c2)
print(df1)
print(df2)
'''
年龄 性别
1号 10 女
2号 20 男
3号 30 男
4号 40 女
学号
1号 1
2号 2
3号 3
6号 5
'''
# + - * / **
print(df1['年龄'] * df2['学号'])
'''
1号 10.0
2号 40.0
3号 90.0
4号 NaN
6号 NaN
dtype: float64
'''
补充:
- NumPy中的
np.abs()、np.cos()、np.exp()、np.log()等数学函数可以直接对Pandas对象使用。 - Pandas中仍然存在布尔型对象,用法与NumPy中的布尔型数组一模一样。
6. 对象的缺失值
6.1 发现缺失值
发现数据列表里的缺失值可以使用.isnull()方法,它会输出一个布尔类型,True表示是缺失值。
一维对象:
v = [12, None, 23, 25]
k = ['1号', '2号', '3号', '4号']
sr = pd.Series(v, index=k)
print(sr)
'''
1号 12.0
2号 NaN
3号 23.0
4号 25.0
dtype: float64
'''
print(sr.isnull())
'''
1号 False
2号 True
3号 False
4号 False
dtype: bool
'''
二维对象:
v = [[None, '女'],[53, None],[24, '男']]
i = ['1号', '2号', '3号']
c = ['年龄', '性别']
df = pd.DataFrame(v, index=i, columns=c)
print(df)
'''
年龄 性别
1号 NaN 女
2号 53.0 None
3号 24.0 男
'''
print(df.isnull())
'''
年龄 性别
1号 True False
2号 False True
3号 False False
'''
若想用False表示缺失值,True表示非缺失值,只需要在前面加非号即可:~df.isnull()。
6.2 剔除缺失值
剔除缺失值使用的方法是:.dropna()。
一维对象很好剔除,二维对象比较复杂,因为你需要考虑是剔除行还是剔除列。
我们一般建议剔除行,因为行代表个体,对于深度学习来说,我们往往有很多个体(甚至几十万),剔除几个无所谓,但是列就是很重要的标签,不要轻易剔除。
一维对象:
v = [53, None, 72, 82]
k = ['1号', '2号', '3号', '4号']
sr = pd.Series(v, index=k)
print(sr)
'''
1号 53.0
2号 NaN
3号 72.0
4号 82.0
dtype: float64
'''
# 剔除缺失值
print(sr.dropna())
'''
1号 53.0
3号 72.0
4号 82.0
dtype: float64
'''
二维对象:
v = [[None, None], [64, None], [72, 3], [82, 4]]
i = ['1号', '2号', '3号', '4号']
c = ['年龄', '学号']
df = pd.DataFrame(v, index=i, columns=c)
print(df)
'''
年龄 学号
1号 NaN NaN
2号 64.0 NaN
3号 72.0 3.0
4号 82.0 4.0
'''
# 按行剔除缺失值
print(df.dropna())
'''
年龄 学号
3号 72.0 3.0
4号 82.0 4.0
'''
若想剔除列:df.dropna(axis='columns'),但是不建议,因为列很重要。
有些同学可能有疑问,现在是只要改行有缺失值就会被剔除,是不是过于严格,那怎样才能让该行全为缺失值时剔除呢?
使用:df.dropna(how='all')。how默认值是any,表示有缺失值就剔除
print(df.dropna(how='all'))
'''
年龄 学号
2号 64.0 NaN
3号 72.0 3.0
4号 82.0 4.0
'''
6.3 填充缺失值
可用方法:.fillna(想要填充的值,比如0)。
一维对象和二维对象是一样的
7. 导入Excel文件
7.1 创建Excel文件
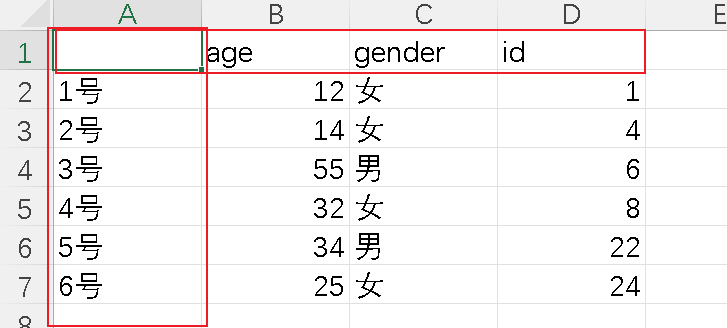
我们导入的Excel文件中必须有第一列和第一行,也就是个体名和特征名。
但有时只有数据没有这两个东西怎么办呢,我们可以打开Excel文件手动插入个体名和特证名,保证Pandas对象的正确读取。
7.2 放入项目文件夹
直接放入当前项目的文件夹,并将后缀改为.csv,这样不用输入绝对路径,直接输入文件名即可导入成功。
7.3 导入Excel信息
导入文件:pd.read_csv('Data.csv', index_col=0)。
# 导入Pandas对象
df = pd.read_csv('Data.csv', index_col=0)
print(df)
'''
age gender id
1号 12 女 1
2号 14 女 4
3号 55 男 6
4号 32 女 8
5号 34 男 22
6号 25 女 24
'''
# 提取数组
print(df.values)
'''
[[12 '女' 1]
[14 '女' 4]
[55 '男' 6]
[32 '女' 8]
[34 '男' 22]
[25 '女' 24]]
'''
注意有时导入后运行报错看看是不是编码问题,要设置成UTF-8。
8. 数据分析
8.1 导入数据
# 导入Pandas对象
df = pd.read_csv('行星数据.csv', index_col=0)
print(df)
'''
发现时间 发现数量 观测方法 行星质量 距地距离 轨道周期
0 1989 1 径向速度 11.680 40.57 83.8880
1 1992 3 脉冲星计时 NaN NaN 25.2620
2 1992 3 脉冲星计时 NaN NaN 66.5419
3 1994 3 脉冲星计时 NaN NaN 98.2114
4 1995 1 径向速度 0.472 15.36 4.2308
... ... ... ... ... ... ...
1030 2014 1 凌日 NaN NaN 2.4650
1031 2014 1 凌日 NaN NaN 68.9584
1032 2014 1 凌日 NaN 1056.00 1.7209
1033 2014 1 凌日 NaN NaN 66.2620
1034 2014 1 凌日 NaN 470.00 0.9255
[1035 rows x 6 columns]
'''
8.2 聚合函数
由上文输出的行星数据可看出,数据量很大,有很多个体,我们可以使用DataFrame的.head()方法,使其仅输出前五行。
# 仅输出前五行
print(df.head())
'''
发现时间 发现数量 观测方法 行星质量 距地距离 轨道周期
0 1989 1 径向速度 11.680 40.57 83.8880
1 1992 3 脉冲星计时 NaN NaN 25.2620
2 1992 3 脉冲星计时 NaN NaN 66.5419
3 1994 3 脉冲星计时 NaN NaN 98.2114
4 1995 1 径向速度 0.472 15.36 4.2308
'''
NumPy中所有的聚合函数对Pandas均适用,且Pandas将这些函数全变为了自己对象的方法,不导入NumPy也能使用。
# 最大值函数 np.max()
print(df.max())
'''
发现时间 2014
发现数量 7
观测方法 轨道亮度调制
行星质量 25.0
距地距离 8500.0
轨道周期 730000.0
dtype: object
'''
# 最小值函数 np.min()
print(df.min())
'''
发现时间 1989
发现数量 1
观测方法 凌日
行星质量 0.0036
距地距离 1.35
轨道周期 0.0907
dtype: object
'''
还有均值函数:df.mean()、标准差函数:df.std()、求和函数:df.sum()。
这些方法都忽略了缺失值,属于聚合函数的安全版本。
8.3 描述方法
在数据分析中,用以上方法挨个查看未免太过麻烦,可以使用.describe()方法直接查看所有聚合函数的信息。
print(df.describe())
'''
发现时间 发现数量 行星质量 距地距离 轨道周期
count 1035.000000 1035.000000 513.000000 808.000000 992.000000
mean 2009.070531 1.785507 2.638161 264.069282 2002.917596
std 3.972567 1.240976 3.818617 733.116493 26014.728304
min 1989.000000 1.000000 0.003600 1.350000 0.090700
25% 2007.000000 1.000000 0.229000 32.560000 5.442575
50% 2010.000000 1.000000 1.260000 55.250000 39.979500
75% 2012.000000 2.000000 3.040000 178.500000 526.005000
max 2014.000000 7.000000 25.000000 8500.000000 730000.000000
'''
- 第1行count是计数项,统计每个特征的有效数量(即排除缺失值),方便用户发现缺失值较多时,考虑什么办法进行填充或舍弃。
- 第2~3行的mean和std统计每列特征的均值和标准差。
- 第4~8行的min、25%、50%、75%、max的意思是五个分位点,即把数组从小到大排序后,0%、25%、50%、75%、100%五个位置上的数值的取值。显然,50%分位点即中位数。
8.4 数据透视
数据透视是数据分析核心中的核心。
导入泰坦尼克数据集:
# 导入Pandas对象
df = pd.read_csv('泰坦尼克.csv', index_col=0)
print(df)
'''
性别 年龄 船舱等级 费用 是否生还
0 男 22.0 三等 7.2500 0
1 女 38.0 一等 71.2833 1
2 女 26.0 三等 7.9250 1
3 女 35.0 一等 53.1000 1
4 男 35.0 三等 8.0500 0
.. .. ... ... ... ...
886 男 27.0 二等 13.0000 0
887 女 19.0 一等 30.0000 1
888 女 NaN 三等 23.4500 0
889 男 26.0 一等 30.0000 1
890 男 32.0 三等 7.7500 0
[891 rows x 5 columns]
'''
在该数据集中,其实前四列(性别、年龄、船舱等级、费用)都输入神经网络中的输入,而真正的输出只有最后一列(是否生还)。
现在我们有一种需求,想看一下每一种条件(一个特征或多个特征)下的生还率是怎样的。
即以“是否生还”特征为考察的核心,研究其它特征与之的关系。
8.4.1 两个特征以内的数据透视
使用方法:df.pivot_table(输出特征, index=输入特征)
一个特征:
print(df.pivot_table('是否生还', index='性别'))
'''
是否生还
性别
女 0.742038
男 0.188908
'''
通过上述代码我们可以得到数据信息:泰坦尼克事件中,女性生还率为0.74,男性生还率为0.18。
那我们现在想统计下不同船舱等级中的男女生还率呢?
两个特征:
print(df.pivot_table('是否生还', index='性别', columns='船舱等级'))
'''
船舱等级 一等 三等 二等
性别
女 0.968085 0.500000 0.921053
男 0.368852 0.135447 0.157407
'''
数据清晰表明,注意这里也可以写成:index='船舱等级', columns='性别',输出结果没有任何影响,只是展示发生变化。
随着数据特征的增多,数据的分析会越来越细致。
注意:这里的.pivot_table()的输出都是平均值mean,因为在该函数中有一个很重要的参数aggfunc,其默认值是mean,除此之外,所有的聚合函数max、min、sum、count均可以使用。
8.4.2 多个特征的数据透视
当有时我们需要考察更多个特征与输出特征的关系时,我们可以先使用方法:pd.cut(特征, 手动分段)、pd.qcut(特征, 自动分段)处理后再用df.pivot_table()进行数据透视。
这里我们把年龄和费用都加上,但是这两个特征数值很分散,什么数都有,为了更好的呈现,我们需要先对其进行处理。
加年龄:
age = pd.cut(df['年龄'], [0, 25, 50, 100])
print(df.pivot_table('是否生还', index=['性别', age], columns='船舱等级'))
'''
船舱等级 一等 三等 二等
性别 年龄
女 (0, 25] 0.928571 0.507692 0.965517
(25, 50] 0.977273 0.361111 0.904762
(50, 100] 1.000000 1.000000 0.666667
男 (0, 25] 0.500000 0.155039 0.277778
(25, 50] 0.459016 0.156522 0.078431
(50, 100] 0.192308 0.000000 0.083333
'''
可以看到,把年龄分为了025岁、2550岁、50~100岁三段(手动分段,可以完全自己定义分段标准,也可以写成:[0, 18, 120])。
加费用:
age = pd.cut(df['年龄'], [0, 25, 50, 100])
price = pd.qcut(df['费用'], 3)
print(df.pivot_table('是否生还', index=['船舱等级', price], columns=['性别', age]))
'''
性别 女 ... 男
年龄 (0, 25] (25, 50] ... (25, 50] (50, 100]
船舱等级 费用 ...
一等 (-0.001, 8.662] NaN NaN ... 0.000000 NaN
(8.662, 26.0] NaN 1.000000 ... 0.000000 0.000000
(26.0, 512.329] 0.928571 0.976190 ... 0.500000 0.200000
三等 (-0.001, 8.662] 0.652174 0.375000 ... 0.142857 0.000000
(8.662, 26.0] 0.531250 0.428571 ... 0.120000 NaN
(26.0, 512.329] 0.100000 0.142857 ... 0.500000 NaN
二等 (8.662, 26.0] 0.941176 0.888889 ... 0.095238 0.090909
(26.0, 512.329] 1.000000 1.000000 ... 0.000000 0.000000
[8 rows x 6 columns]
'''
pd.qcut()可以进行自动分段,但是没有固定的分段标准,因此不建议使用,数据分析总归是根据需求进行分析,还是要自己定义分段标准。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号