大数据学习路线
迷惘了很长一段时间,刚好也年底了,就稍微总结一下我的2019年吧。上半年学习了一些关于人工智能的东西,下半年主要梳理了一些公司的业务层面的东西。今年觉得比较失败的一点是,遇到不同的人,都很羡慕别人的优势和长处,并且没有规划性的尝试模仿别人,当然最终的结果就是----东施效颦。当然最高兴的就是在我年底这段时间,我能发现了我的这个毛病,至于怎么解决,应该是值得思考一生的吧。蔡康永说,他自己最常被粉丝要求写下的三个字不是“蔡康永”,而是——做自己。我们每个人都渴望做自己内心深处那个自己觉得最满意的自己,我也是,可是我真的还没有找到怎样才是让我满意的自己,怎样做才能让自己满意。但是暂时的我知道,目前我需要的是更好一点的工作环境,更高一点的薪资,那么,我应该做的就是更加钻研自己的专业,提升自己的能力吧。如何钻研?那我接下来应该会根据下图这个大数据学习路线一步一步的走,并且会输出一些自己的东西出来。希望可以有志同道合的朋友一起讨论交流学习。
大数据处理流程:
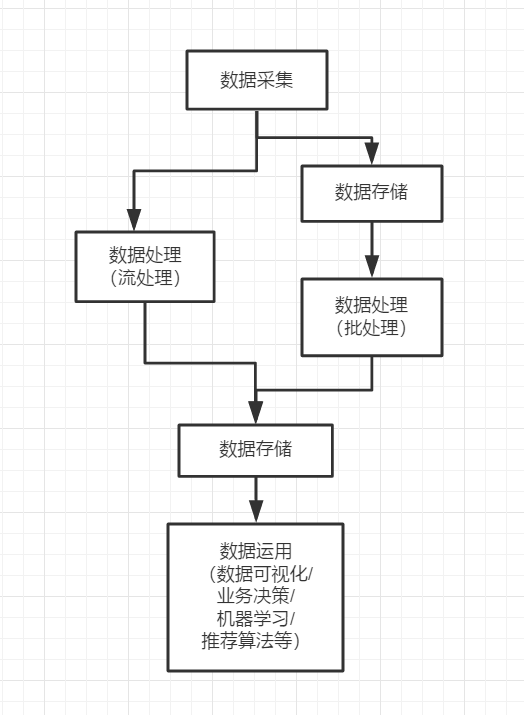
1.数据采集
巧妇难为无米之炊,大数据处理的第一步就是数据的收集,现在的很多项目都采用微服务架构进行分布式部署,所以数据的采集需要在多台机器上进行,并且采集过程不能影响线上业务的正常开展。在此背景下,衍生出了很多日志收集工具,比如 Flume,Logstash,Kibana等,他们都能通过简单的配置完成复杂的数据收集。
2.数据存储
数据收集之后,紧接着需要处理的就是----数据存储。MySQL,Oracle等传统的关系型数据库因为能够快速存储结构化数据,并且支持随机访问而被大家广泛的使用。而大数据的数据结构通常是半结构化(如日志数据),甚至是非结构化的(如视频,音频数据),
为了解决海量半结构化数据和非结构化数据的存储,衍生出了 Hadoop HDFS 、KFS(Kosmos distributed file system) 、 GFS(google File System) 等分布式文件系统,它们都能够支持结构化、半结构和非结构化数据的存储,并可以通过增加机器进行横向扩展。分布式文件系统完美地解决了海量数据存储的问题,但是一个优秀的数据存储系统需要同时考虑数据存储和访问两方面的问题,比如你希望能够对数据进行随机访问,这是传统的关系型数据库所擅长的,但却不是分布式文件系统所擅长的,那么有没有一种存储方案能够同时兼具分布式文件系统和关系型数据库的优点,基于这种需求,就产生了 HBase、MongoDB。
3.数据处理
数据处理通常分为两种方式:批处理和流处理。
批处理:对一段时间内海量的离线数据进行统一的处理,对应的处理框架有 Hadoop MapReduce、Spark 、Flink 等;
流处理:对运动中的数据进行处理,即在接收数据的同时就对其进行处理,对应的处理框架有 Storm、Spark Streaming、Flink、Blink 等。
批处理和流处理各有其适用的场景,实时性要求不高或者硬件资源有限,可以采用批处理;时间敏感和实时性要求高就可以采用流处理。随着服务器硬件的价格越来越低和大家对实时性的要求越来越高,流处理越来越普遍,如股票价格预测和电商运营数据分析等。
上面的框架都是需要通过编程来进行数据分析,大数据是一个非常完善的生态圈,为了能够让熟悉 SQL 的人员也能够进行数据的分析,查询分析框架应运而生,常用的有 Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix 等。这些框架都能够使用标准的 SQL 或者 类 SQL 语法灵活地进行数据的查询分析。这些 SQL 经过解析优化后转换为对应的作业程序来运行,如 Hive 本质上就是将 SQL 转换为 MapReduce 作业,Spark SQL 将 SQL 转换为一系列的 RDDs 和转换关系(transformations),Phoenix 将 SQL 查询转换为一个或多个 HBase Scan。
4.数据应用
数据分析完成后,接下来就是数据应用的范畴,这取决于你实际的业务需求。现在应用比较多的就是数据的可视化分析和算法应用(将数据用于优化你的推荐算法或者训练机器学习模型),这种运用现在很普遍,比如短视频个性化推荐、电商商品推荐、头条新闻推荐等。数据可视化这部分有一些无需编程的工具:Excel,tableau,QuickBI等等。算法应用这一部分,Spark提供了一个可扩展的机器学习库Spark-MLlib。MLlib中已经包含了一些通用的学习算法和工具,如:分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。这一部分,之后可以单独展开。
5.其他
上面是一个标准的大数据处理流程。但是实际的大数据处理流程比上面复杂很多,针对大数据处理中的各种复杂问题分别衍生了各类框架:
* 单机的处理能力都是存在瓶颈的,所以大数据框架都是采用集群模式进行部署,为了更方便的进行集群的部署、监控和管理,衍生了 Ambari、Cloudera Manager 等集群管理工具;
* 想要保证集群高可用,需要用到 ZooKeeper ,ZooKeeper 是最常用的分布式协调服务,它能够解决大多数集群问题,包括领导者选举、失败恢复、元数据存储及其一致性保证。同时针对集群资源管理的需求,又衍生了 Hadoop YARN ;
* 复杂大数据处理的另外一个显著的问题是,如何调度多个复杂的并且彼此之间存在依赖关系的作业?Azkaban 和 Oozie 等工作流调度框架应运而生;
* 大数据流处理中使用的比较多的另外一个框架是 Kafka,它可以用于消峰,避免在秒杀等场景下并发数据对流处理程序造成冲击;
* 另一个常用的框架是 Sqoop ,主要是解决了数据迁移的问题,它能够通过简单的命令将关系型数据库中的数据导入到 HDFS 、Hive 或 HBase 中,或者从 HDFS 、Hive 导出到关系型数据库上。
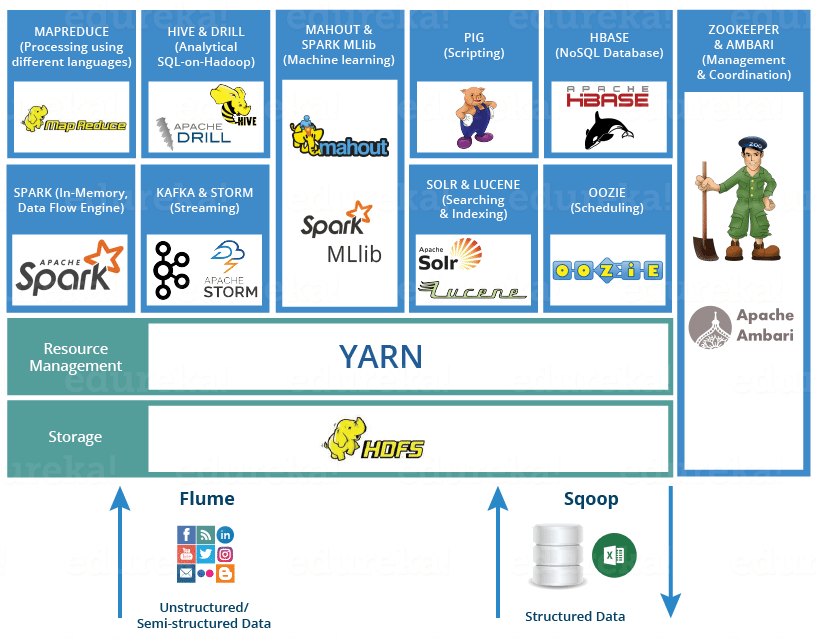
下图是一个比较常用的大数据技术架构图: