为什么要引入”随机变量“的概念,如何定义随机变量《考研概率论学习之我见》
l
先仔细定义一下随机变量的概念,然后再引入概率函数比较好。
1.随机变量的准确定义
2.为什么要引入随机变量?
3.随机变量的本质是什么?
4.随机变量的对应关系f唯一吗?
5.随机变量明明是”函数“为什么叫”变量“?
6.我们之前学的考研古典概率样本空间跟随机变量的联系?
1.随机变量的准确定义
随机变量就是从结果空间到实数集的映射,它就是将我们做实验得到的统计结果变成一个数集的过程。
既然它是映射,那么就要符合一些有关映射的规则,比如只能多对一,不能一对多,也就是既是我们的实验是两个结果(比如同时抛两个筛子),那么必须最后结果可以被看作是一个数字。随机变量不是古典概率,不要求等概率。
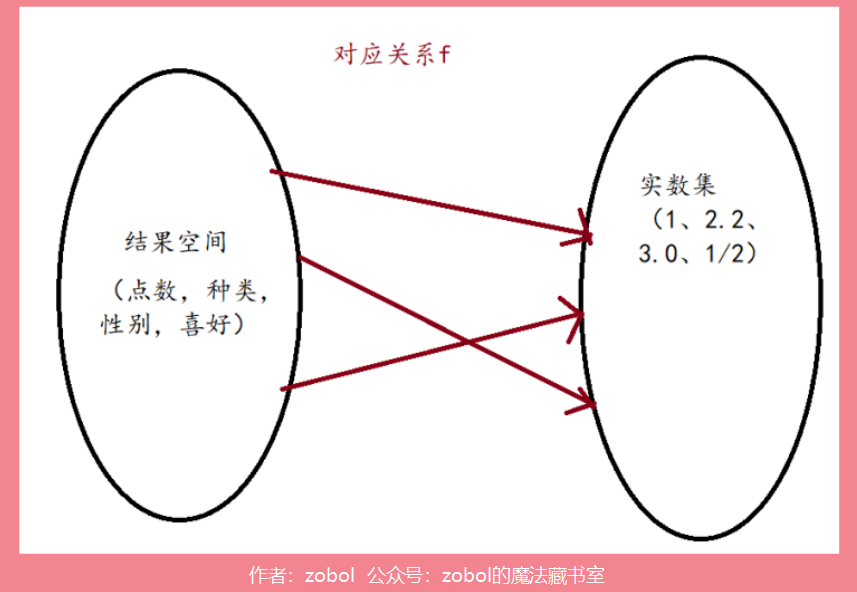
并不是所有事情的结果都可以找到对应关系f的(比如量子实验的结果,或者一些极复杂的系统结果),那么久不能构成随机变量,也就不能应用接下来我们讨论的数学工具了。
2.为什么要引入随机变量?
因为只有将其变成实数集,我们接下来才能引入函数这个数学工具到考研概率论中,函数是定义在数集上的映射,否则我们只能使用古典概率这种在考研范围内比较简陋的数学工具了。
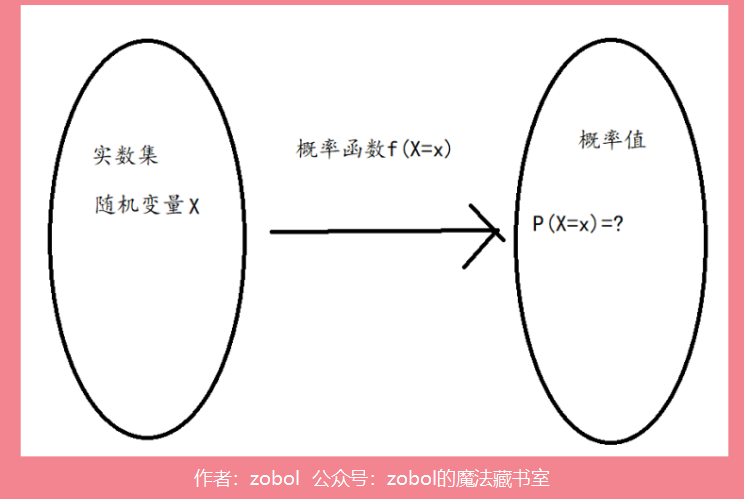
有了概率函数,我们才能利用其研究很多我们比较复杂的概率问题,比如投1000次硬币,正面向上501次的概率是多少?如果有了一个函数公式,我们直接带入x=501,结果就很快计算出来了。
3.随机变量的本质是什么?
是一个对应关系f可以得到的映射,你可以简单记为f-可测。所以本质就是一个可测映射。
4.随机变量的对应关系f唯一吗?
不唯一,比如投三次硬币,如果你单纯计算次数那么就只有{0,1,2,3},4个数字。如果你加入了次序,那么就有2^3=6个数字。视你研究的问题不同,随机变量的定义也不同
5.随机变量明明是”函数“为什么叫”变量“?
因为从统计学的角度来看,每次实验得到一个结果,再映射成一个数字被记录下来。每次得到的结果都不同,所以称为变量。
6.我们之前学的考研古典概率样本空间跟随机变量的联系?
古典概率中的样本空间中的事件(无论是样本点还是基本事件),都可以被映射为数字,然后构成一个函数。
但是因为古典概率中的样本点事件概率相等,就考研学的简单情况来讲,后面很难找到有意义的概率函数,所以没有太多联系的地方,做题也能感觉到两者出题基本没有联系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号