树
Introduction to Tree – Data Structure and Algorithm Tutorials
What is a Tree data structure?
A tree data structure is a hierarchical structure that is used to represent and organize data in a way that is easy to navigate and search. It is a collection of nodes that are connected by edges and has a hierarchical relationship between the nodes. The topmost node of the tree is called the root, and the nodes below it are called the child nodes. Each node can have multiple child nodes, and these child nodes can also have their own child nodes, forming a recursive structure.
This data structure is a specialized method to organize and store data in the computer to be used more effectively. It consists of a central node, structural nodes, and sub-nodes, which are connected via edges. We can also say that tree data structure has roots, branches, and leaves connected with one another.
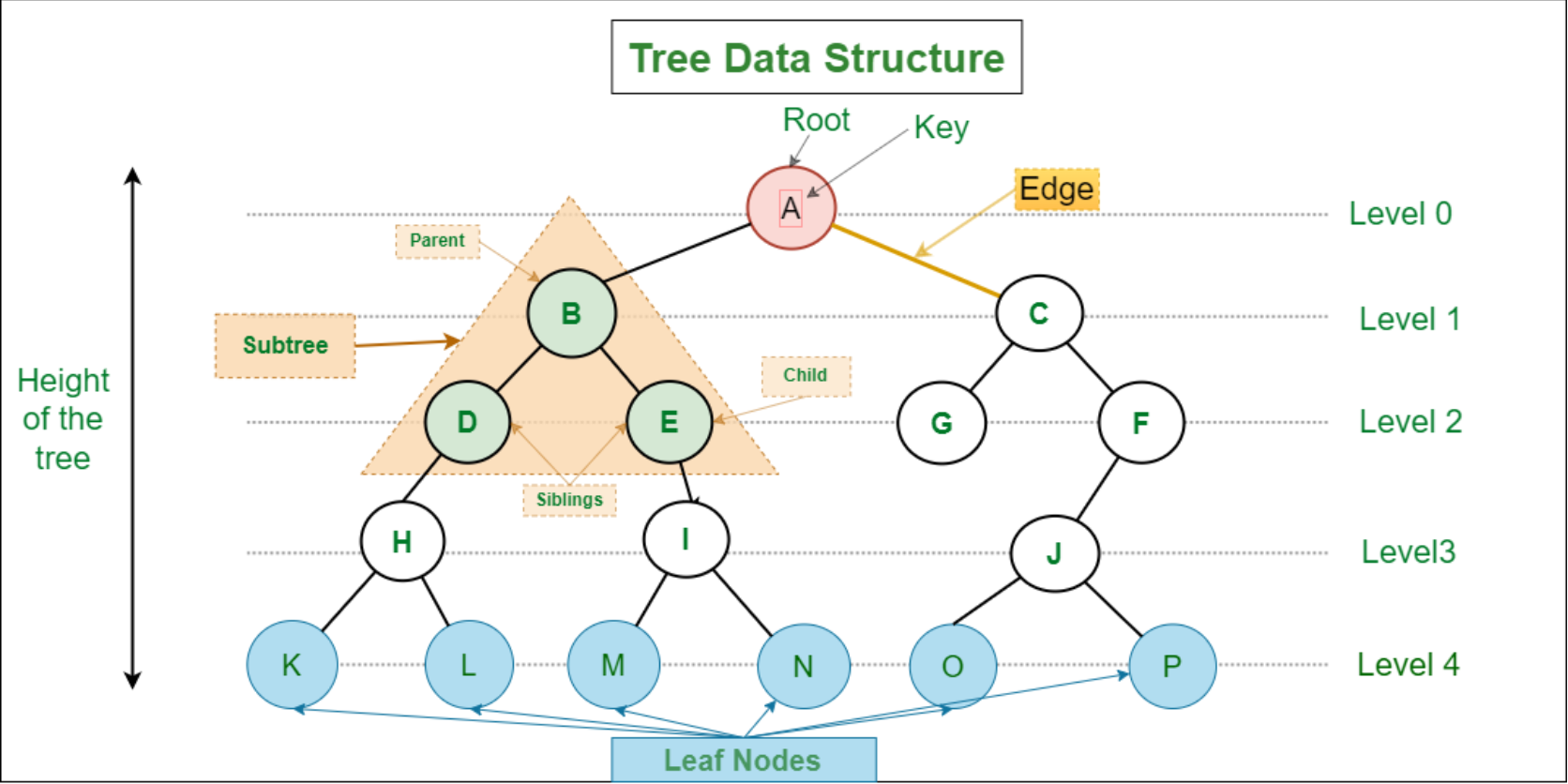
Introduction to Tree – Data Structure and Algorithm Tutorials
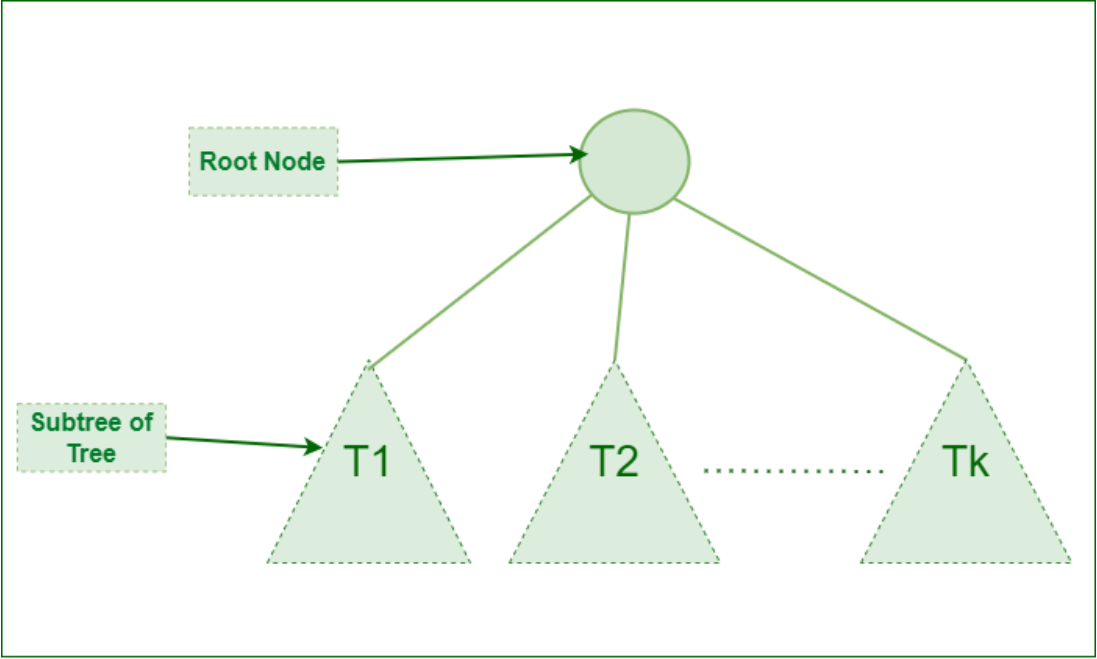
Recursive Definition:
A tree consists of a root, and zero or more subtrees T1, T2, … , Tk such that there is an edge from the root of the tree to the root of each subtree.
Why Tree is considered a non-linear data structure?
The data in a tree are not stored in a sequential manner i.e, they are not stored linearly. Instead, they are arranged on multiple levels or we can say it is a hierarchical structure. For this reason, the tree is considered to be a non-linear data structure.
Basic Terminologies In Tree Data Structure:
- Parent Node: The node which is a predecessor of a node is called the parent node of that node. {B} is the parent node of {D, E}.
- Child Node: The node which is the immediate successor of a node is called the child node of that node. Examples: {D, E} are the child nodes of {B}.
- Root Node: The topmost node of a tree or the node which does not have any parent node is called the root node. {A} is the root node of the tree. A non-empty tree must contain exactly one root node and exactly one path from the root to all other nodes of the tree.
- Leaf Node or External Node: The nodes which do not have any child nodes are called leaf nodes. {K, L, M, N, O, P} are the leaf nodes of the tree.
- Ancestor of a Node: Any predecessor nodes on the path of the root to that node are called Ancestors of that node. {A,B} are the ancestor nodes of the node {E}
- Descendant: Any successor node on the path from the leaf node to that node. {E,I} are the descendants of the node {B}.
- Sibling: Children of the same parent node are called siblings. {D,E} are called siblings.
- Level of a node: The count of edges on the path from the root node to that node. The root node has level 0.
- Internal node: A node with at least one child is called Internal Node.
- Neighbour of a Node: Parent or child nodes of that node are called neighbors of that node.
- Subtree: Any node of the tree along with its descendant.
Properties of a Tree:
- Number of edges: An edge can be defined as the connection between two nodes. If a tree has N nodes then it will have (N-1) edges. There is only one path from each node to any other node of the tree.
- Depth of a node: The depth of a node is defined as the length of the path from the root to that node. Each edge adds 1 unit of length to the path. So, it can also be defined as the number of edges in the path from the root of the tree to the node.
- Height of a node: The height of a node can be defined as the length of the longest path from the node to a leaf node of the tree.
- Height of the Tree: The height of a tree is the length of the longest path from the root of the tree to a leaf node of the tree.
- Degree of a Node: The total count of subtrees attached to that node is called the degree of the node. The degree of a leaf node must be 0. The degree of a tree is the maximum degree of a node among all the nodes in the tree.
Some more properties are:
- Traversing in a tree is done by depth first search and breadth first search algorithm.
- It has no loop and no circuit
- It has no self-loop
- Its hierarchical model.
Syntax:
struct Node
{
int data;
struct Node *left_child;
struct Node *right_child;
};
Basic Operation Of Tree:
Create – create a tree in data structure.
Insert − Inserts data in a tree.
Search − Searches specific data in a tree to check it is present or not.
Preorder Traversal – perform Traveling a tree in a pre-order manner in data structure .
In order Traversal – perform Traveling a tree in an in-order manner.
Post order Traversal –perform Traveling a tree in a post-order manner.
Example of Tree data structure
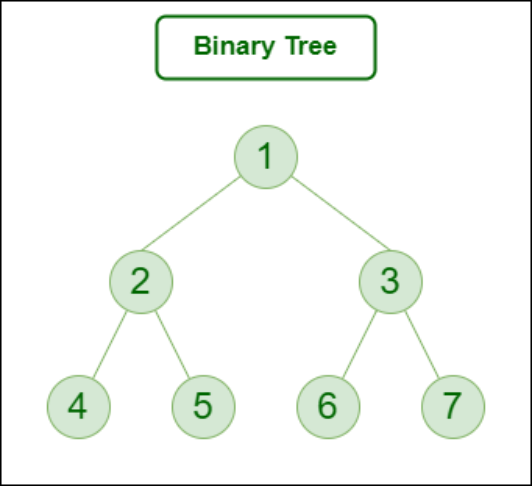
Here,
Node 1 is the root node
1 is the parent of 2 and 3
2 and 3 are the siblings
4, 5, 6 and 7 are the leaf nodes
1 and 2 are the ancestors of 5
// java code for above approachimport java.io.*;import java.util.*;class GFG { // Function to print the parent of each node public static void printParents(int node, Vector<Vector<Integer> > adj, int parent) { // current node is Root, thus, has no parent if (parent == 0) System.out.println(node + "->Root"); else System.out.println(node + "->" + parent); // Using DFS for (int i = 0; i < adj.get(node).size(); i++) if (adj.get(node).get(i) != parent) printParents(adj.get(node).get(i), adj, node); } // Function to print the children of each node public static void printChildren(int Root, Vector<Vector<Integer> > adj) { // Queue for the BFS Queue<Integer> q = new LinkedList<>(); // pushing the root q.add(Root); // visit array to keep track of nodes that have been // visited int vis[] = new int[adj.size()]; Arrays.fill(vis, 0); // BFS while (q.size() != 0) { int node = q.peek(); q.remove(); vis[node] = 1; System.out.print(node + "-> "); for (int i = 0; i < adj.get(node).size(); i++) { if (vis[adj.get(node).get(i)] == 0) { System.out.print(adj.get(node).get(i) + " "); q.add(adj.get(node).get(i)); } } System.out.println(); } } // Function to print the leaf nodes public static void printLeafNodes(int Root, Vector<Vector<Integer> > adj) { // Leaf nodes have only one edge and are not the // root for (int i = 1; i < adj.size(); i++) if (adj.get(i).size() == 1 && i != Root) System.out.print(i + " "); System.out.println(); } // Function to print the degrees of each node public static void printDegrees(int Root, Vector<Vector<Integer> > adj) { for (int i = 1; i < adj.size(); i++) { System.out.print(i + ": "); // Root has no parent, thus, its degree is // equal to the edges it is connected to if (i == Root) System.out.println(adj.get(i).size()); else System.out.println(adj.get(i).size() - 1); } } // Driver code public static void main(String[] args) { // Number of nodes int N = 7, Root = 1; // Adjacency list to store the tree Vector<Vector<Integer> > adj = new Vector<Vector<Integer> >(); for (int i = 0; i < N + 1; i++) { adj.add(new Vector<Integer>()); } // Creating the tree adj.get(1).add(2); adj.get(2).add(1); adj.get(1).add(3); adj.get(3).add(1); adj.get(1).add(4); adj.get(4).add(1); adj.get(2).add(5); adj.get(5).add(2); adj.get(2).add(6); adj.get(6).add(2); adj.get(4).add(7); adj.get(7).add(4); // Printing the parents of each node System.out.println("The parents of each node are:"); printParents(Root, adj, 0); // Printing the children of each node System.out.println( "The children of each node are:"); printChildren(Root, adj); // Printing the leaf nodes in the tree System.out.println( "The leaf nodes of the tree are:"); printLeafNodes(Root, adj); // Printing the degrees of each node System.out.println("The degrees of each node are:"); printDegrees(Root, adj); }}// This code is contributed by rj13to. |
The parents of each node are: 1->Root 2->1 5->2 6->2 3->1 4->1 7->4 The children of each node are: 1-> 2 3 4 2-> 5 6 3-> 4-> 7 5-> 6-> 7-> The leaf nodes of the tree are: 3 5 6 7 The degrees of each node are: 1: 3 2: 2 3: 0 4: 1 5: 0 6: 0 7: 0
Types of Tree data structures
The different types of tree data structures are as follows:
1. General tree
A general tree data structure has no restriction on the number of nodes. It means that a parent node can have any number of child nodes.
2. Binary tree
A node of a binary tree can have a maximum of two child nodes. In the given tree diagram, node B, D, and F are left children, while E, C, and G are the right children.
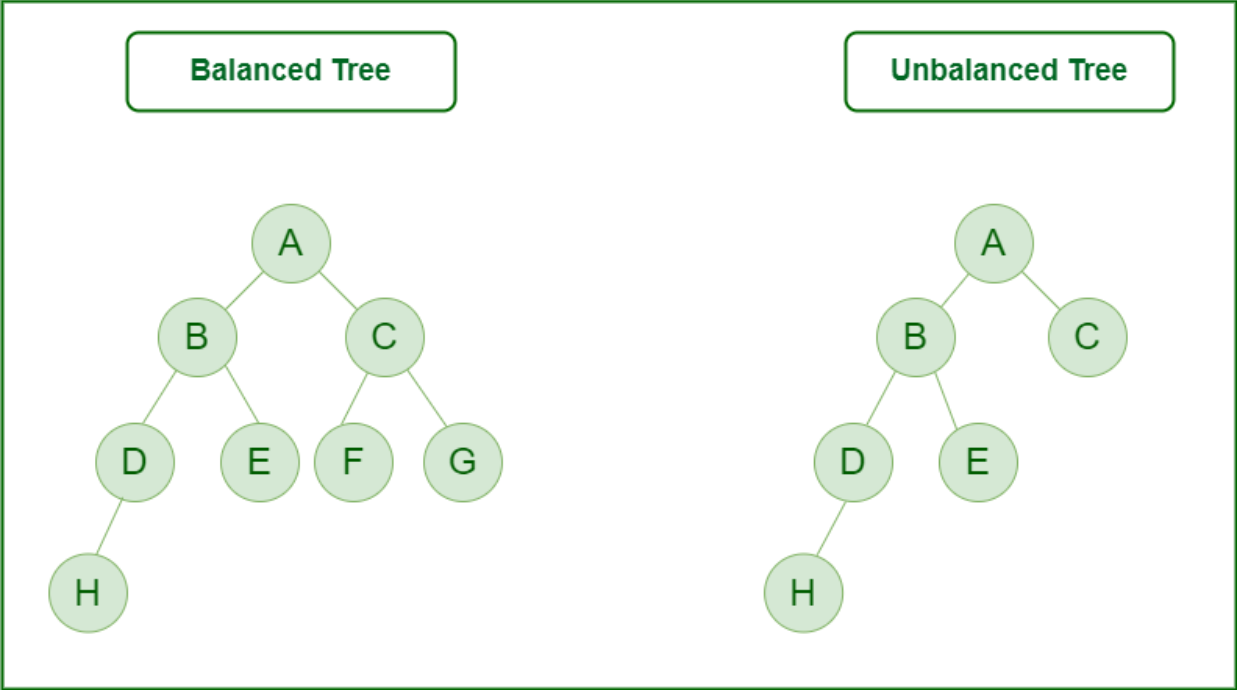
3. Balanced tree
If the height of the left sub-tree and the right sub-tree is equal or differs at most by 1, the tree is known as a balanced tree.
4. Binary search tree
As the name implies, binary search trees are used for various searching and sorting algorithms. The examples include AVL tree and red-black tree. It is a non-linear data structure. It shows that the value of the left node is less than its parent, while the value of the right node is greater than its parent.
Applications of Tree data structure:
The applications of tree data structures are as follows:
1. Spanning trees: It is the shortest path tree used in the routers to direct the packets to the destination.
2. Binary Search Tree: It is a type of tree data structure that helps in maintaining a sorted stream of data.
- Full Binary tree
- Complete Binary tree
- Skewed Binary tree
- Strictly Binary tree
- Extended Binary tree
3. Storing hierarchical data: Tree data structures are used to store the hierarchical data, which means data is arranged in the form of order.
4. Syntax tree: The syntax tree represents the structure of the program’s source code, which is used in compilers.
5. Trie: It is a fast and efficient way for dynamic spell checking. It is also used for locating specific keys from within a set.
6. Heap: It is also a tree data structure that can be represented in a form of an array. It is used to implement priority queues.
7. Artificial intelligence: Decision trees and other tree-based models are commonly used in machine learning and artificial intelligence to make predictions and classify data.
8. Database: Some databases use trees to organize data for efficient searching and sorting.
9. Network: Routing algorithms for networks, such as Internet Protocol (IP) routing, use trees to find the best path for data to travel from one network to another.
Advantages of Tree data structure
- Efficient insertion, deletion, and search operations.
- Trees are flexibility in terms of the types of data that can be stored.
- It is used to represent hierarchical relationships.
- It has the ability to represent a recursive structure.
- Used in various algorithms and data structures such as Huffman coding and decision trees.
- Trees use less space than other data structures, like lists, and linked lists.
- Trees are dynamic in nature.
- Tree data structures can automatically self-organize as new data is added or removed, which can improve performance and reduce complexity.
Disadvantages of Tree data structure
- Trees require additional memory for pointers.
- Trees are not the best choice for data that does not have hierarchical relationships.
- Trees with many levels can become expensive to search and traverse.
- Limited scalability compared to other data structures such as hash tables.
- Trees are typically used for storing and manipulating hierarchical data, and may not be the best choice for other types of data.
- Not suitable for large datasets.
- Trees can become unbalanced, leading to poor performance and decreased efficiency.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号