1、 数据采集(要求至少爬取三千条记录,时间跨度超过一星期):(10分)
要求Python 编写程序爬取京东手机的评论数据,放入到csv中。
1 import csv 2 import urllib.request 3 import json 4 import time 5 import xlwt 6 7 # ======》爬取评论信息《=======# 8 9 end_page = int(input('请输入爬取的结束页码:')) 10 for i in range(0, end_page + 1): 11 print('第%s页开始爬取------' % (i + 1)) 12 url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100004770259&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1 ' 13 url = url.format(i) 14 headers = { 15 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 16 'Referer': 'https://item.jd.com/100026796992.html' 17 } 18 19 request = urllib.request.Request(url=url, headers=headers) 20 content = urllib.request.urlopen(request).read().decode('gbk') 21 content = content.strip('fetchJSON_comment98vv385();') 22 obj = json.loads(content) 23 comments = obj['comments'] 24 fp = open('华为.json', 'a', encoding='utf8') 25 for comment in comments: 26 id=comment['id'] 27 guid=comment['guid'] 28 # 评论内容 29 content = comment['content'] 30 # 评论时间 31 creationTime = comment['creationTime'] 32 isTop=comment['isTop'] 33 referenceTime=comment['referenceTime'] 34 firstCategory=comment['firstCategory'] 35 secondCategory=comment['secondCategory'] 36 thirdCategory=comment['thirdCategory'] 37 replyCount=comment['replyCount'] 38 score=comment['score'] 39 # 评论人 40 nickname = comment['nickname'] 41 userClient= comment['userClient'] 42 productColor= comment['productColor'] 43 productSize= comment['productSize'] 44 # 会员等级 45 userLevelName = comment['plusAvailable'] 46 if userLevelName == "201": 47 userLevelName = "PLUS会员" 48 elif userLevelName == "203": 49 userLevelName = "金牌会员" 50 elif userLevelName == "103": 51 userLevelName = "普通用户" 52 elif userLevelName == "0": 53 userLevelName = "无价值用户" 54 else: 55 userLevelName = "银牌会员" 56 # userLevelName= comment['user-level'] 57 plusAvailable= comment['plusAvailable'] 58 productSales= comment['productSales'] 59 userClientShow ="京东客户端" 60 # userClientShow= comment['userClientShow'] 61 # isMobile= comment['isMobile'] 62 # 移动端PC端 63 isMobile = comment['userClient'] 64 if isMobile == "4": 65 isMobile = "移动端" 66 else: 67 isMobile = "PC端" 68 days= comment['days'] 69 afterDays= comment['afterDays'] 70 # 写入文件 71 with open('comments_jd2.csv', 'a', encoding='utf8') as csv_file: 72 rows = (id,guid,content,creationTime,isTop,referenceTime,firstCategory,secondCategory,thirdCategory,replyCount,score,nickname,userClient,productColor,productSize, userLevelName,plusAvailable,productSales, userClientShow,isMobile,days,afterDays) 73 writer = csv.writer(csv_file) 74 writer.writerow(rows) 75 print('第%s页完成----------' % (i + 1)) 76 time.sleep(4) 77 fp.close()
采集过程:
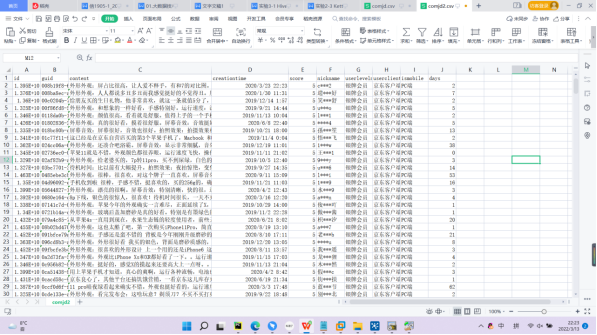
采集结果:
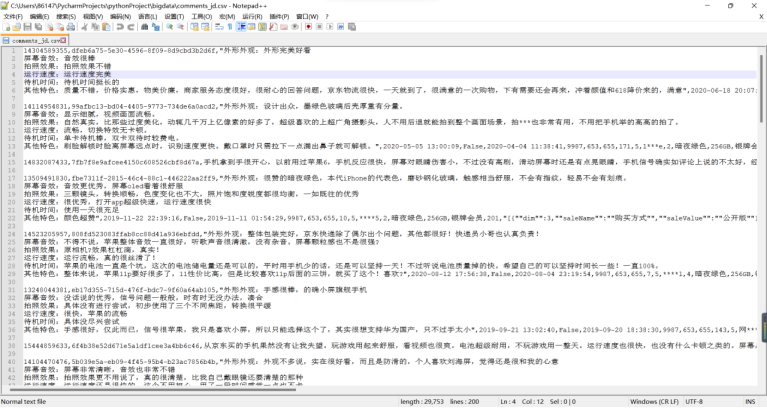
2、数据预处理:要求使用MapReduce或者kettle实现源数据的预处理,对大量的Json文件,进行清洗,以得到结构化的文本文件。
实验步骤:
|
1.新建转换 在左边步骤中选择“输入”:拖动CSV文件输入到右侧空白 搜索“字符串替换”,拖动到右侧 步骤搜索框搜索“排序记录”,“去除重复记录”同样按顺序拖动到右侧 在左侧步骤中选择“输出”:拖动文本文件输出到右侧 按上述顺序连接步骤(shift+左键连接即可) 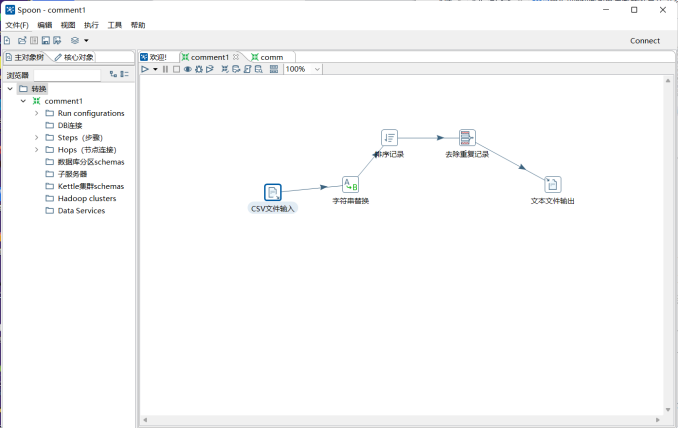
|
2:设置“CSV文件输入”
|
|
3.设置“字符串替换”
|
|
4.设置“排序记录” 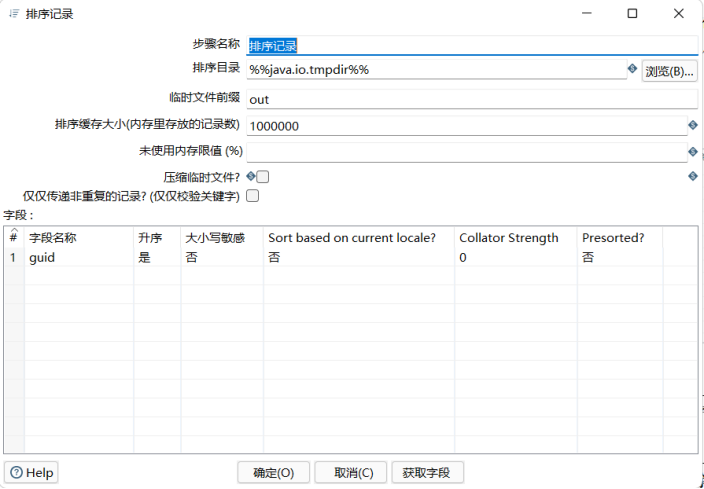
|
|
5.设置“去除重复记录” 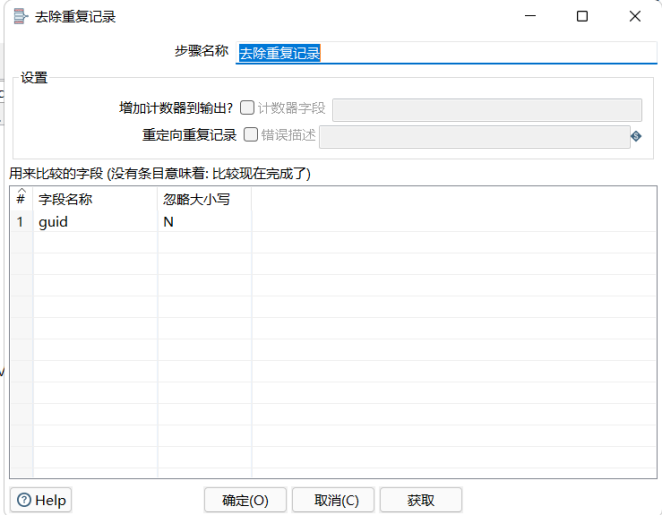
|
|
6.设置“文本文件输出” 
|
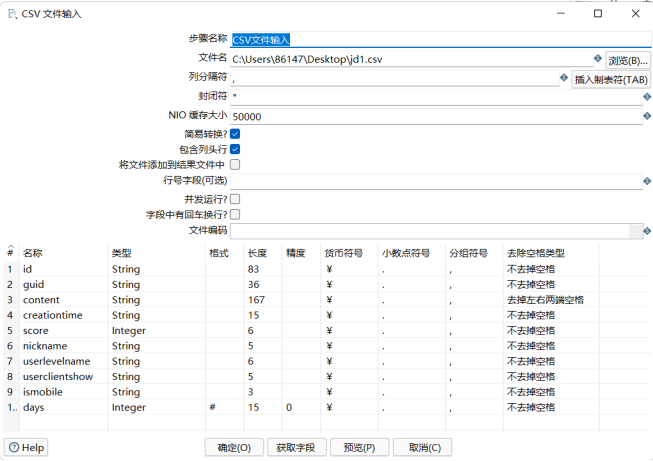
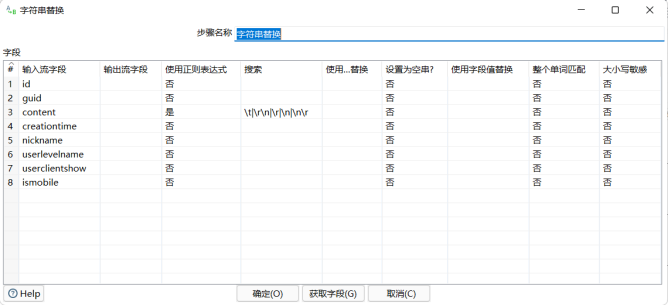
实验结果:

按照清洗后的数据格式要求提取相应的数据字段文件: