一、maven项目运行spark时遇到hadoop相关问题

解决方法:
在http://hadoop.apache.org/releases.html下载对应版本hadoop并解压
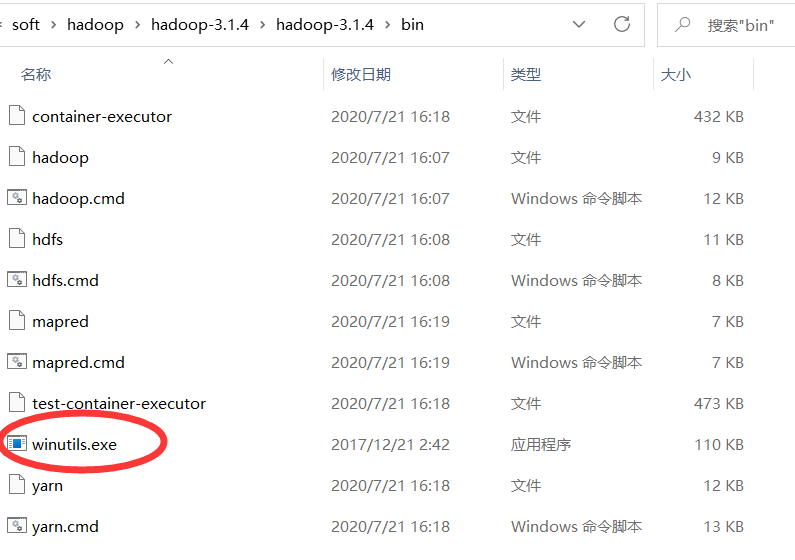
下载对应版本的hadoop-common,我下载的是hadoop-common-3.0.0-bin-master.zip,将其中的winutils.exe复制在hadoop的bin目录下
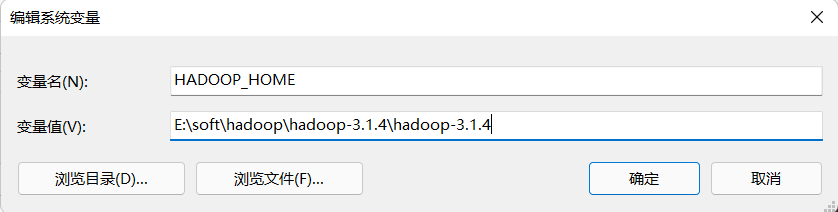
添加系统环境变量
将系统变量添加到Path变量中(%HADOOP_HOME%和%HADOOP_HOME%\bin):
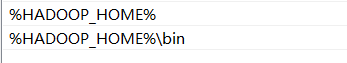
在命令行输入hadoop -version检查是否成功

二、运行spark出现大量日志信息
解决方式:
若不想要打印日志信息,可以将如下代码粘贴到resources下的log4j.properties中
log4j.rootCategory=ERROR,console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}:%m%n # Set the default spark-shell log level to ERROR.When running the spark-shell, the # log level for this class is used to overwrite the root logger's loglevel,so that # the user can have different defaults for the shell and regular Spark apps.log4j.logger.org.apache.spark.repl.Main=ERROR # Settings to quiet third party logs that are too verboselog4j.logger.org.spark_project.jetty=ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking upnonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR