


一、spark-submit
1、类似于:hadoop jar; [主要负责jar包的提交];
2、语法:spark-submit [options] <app jar | python file> [app arguments]
通过- -help 查看参数:

参数options:
-
-master: 指定运行模式,spark://host:port, mesos://host:port, yarn, or local[n].
-
-deploy-mode: 指定将driver端运行在client 还是在cluster,默认情况下是client模式
-
-class: 指定运行程序main方法类名,一般是应用程序的包名+类名
-
-name: 运用程序名称
-
-jars: 需要在driver端和executor端运行的jar,如mysql驱动包
-
-packages: maven管理的项目坐标GAV,多个以逗号分隔
-
-conf: 以key=value的格式强制指定Spark配置属性,所传入的参数必须是以spark开头
-
-driver-memory:指定driver端运行内存,默认1G
-
-executor-memory:指定executor端的内存,默认1G
3、Spark自带examples样例提交任务:
(1)本地模式运提交:
1-路径:/kkb/install/spark2.2.0/examples/jars spark-examples_2.11-2.2.0.jar

2-提交jar包: spark-submit --master local --class org.apache.spark.examples.SparkPi spark-examples_2.11-2.2.0.jar 10
** --master : 运行在哪里
** local : 本地运行,local可以添加参数:local[1] 代表每台服务器需要1个核数,local[*]所有的核数,如果给的参数是*,虽然是本地模式,但是模拟的是集群模式。
** --calss:运行的是哪个类
** jar:x需要的jar包
** 参数 10:做10次运算
spark-submit --master local[*] --class org.apache.spark.examples.SparkPi spark-examples_2.11-2.2.0.jar 10
(2)集群模式提交:[真正的集群提交模式]
spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi spark-examples_2.11-2.2.0.jar 10
二、spark-shell
1、交互式的命令行。[spark-shell底层也是使用spark-submint 提交的]
2、启动命令:spark-shell --master spark://node01:7077
说明:
-
1-启动 spark-shell等于是启动了一个应用,所以运行启动速度慢;
-
2-交互式命令行的监控页面是4040端口。
-
3-sc是sparkContext的对象实例,Context是上下文。负责初始化很多的东西。例如driver端的数据和实例
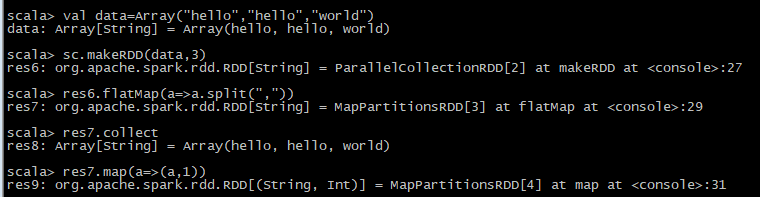
3、使用集合并行化的形式创建RDD

4、读取外部文件的形式创建RDD

备注:RDD是分布式的,读取数据的时候也是分布式的,其他服务器如果在指定的目录下没有指定的文件,就会报错,所以读取数据的时候最好是读取HDFS上的数据

