


一、spark概述
1、Spark是什么
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
(1) Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
(2)Spark Core中提供了Spark最基础与最核心的功能
(3) Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
(4) Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。 由上面的信息可以获知,Spark出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实Spark一直被认为是Hadoop 框架的升级版。
2、Spark特点
(1)快:Hadoop的 MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG【优化】执行引擎,可以通过基于内存来高效处理数据流。
(2)易用:Spark支持Java、Python和Scala和R的API,还支持超过80种高级算法,使用户可以
快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell 中使用Spark集群来验证解决问题的方法。
(3)通用:一站式的解决方案: 支持:离线处理、实时处理、sql【交互式的查询】。
(4)兼容性:MR基于Yarn来分配资源,但是Spark可以基于也可以单独运行。
3、Spark模块结构图
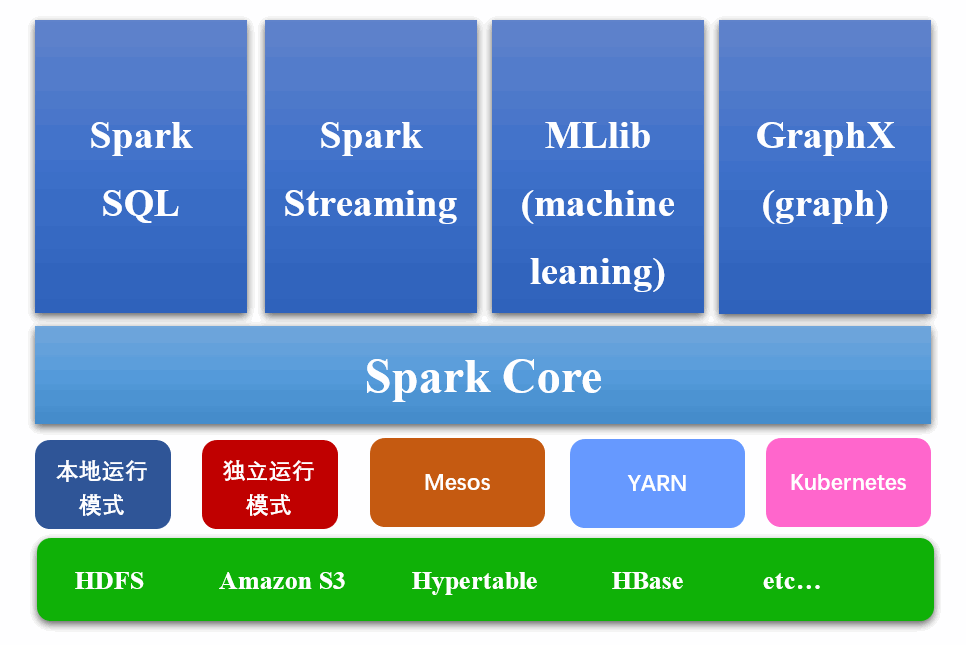
- Spark Core:
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的
- Spark SQL:
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
- Spark Streaming:
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
- Spark MLlib:
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- Spark GraphX:
GraphX是Spark面向图计算提供的框架与算法库。
二、spark安装
1、部署方式
(1)local模式
直接在本地运行,spark以函数库的形式起作用
(2)standalone模式
利用spark自带的集群部署工具搭建集群,功能较为单一,如果集群只用spark可以考虑,但这个场景极少
(3)yarn模式.
让spark运行在yarn上,这个yarn可以用spark自带的,此时要下载spark-2.4.5-bin-hadoop2.7.tgz这个库;也可以先部署好hadoop,再将spark运行在已经运行起来的hadoop集群上,此时要下载spark-2.4.5-bin-without-
hadoop.tgz这个库
2、Standalone模式部署流程
(1)上传安装包spark-2.2.0-bin-hadoop2.7.tgz到虚拟机中
(2)解压spark安装包到指定目录,tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /kkb/install/

(3) 重命名mv spark-2.2.0-bin-hadoop2.7 spark2.2.0

重命名spark-env.sh.template 为 spark-env.sh

重命名slaves.template 为slaves

(4)sudo -s进入管理员修改配置文件
修改spark-env.sh:

修改slaves:
将文件末尾的localhost去掉,增加三个节点的主机名
配置环境变量vim /etc/profile(将SPARK_HOME配置在JAVA_HOME之前):

source /etc/profile使环境生效
(5)将配置好的Spark发送给其他节点:
scp -rq spark2.2.0 node02:/kkb/install

scp -rq spark2.2.0 node03:/kkb/install

scp /etc/profile node02:/etc/profile
scp /etc/profile node03:/etc/profile

(6)最后在shell命令窗口使用命令: source /etc/profile 让全部的节点环境生效。
(7)启动spark集群:

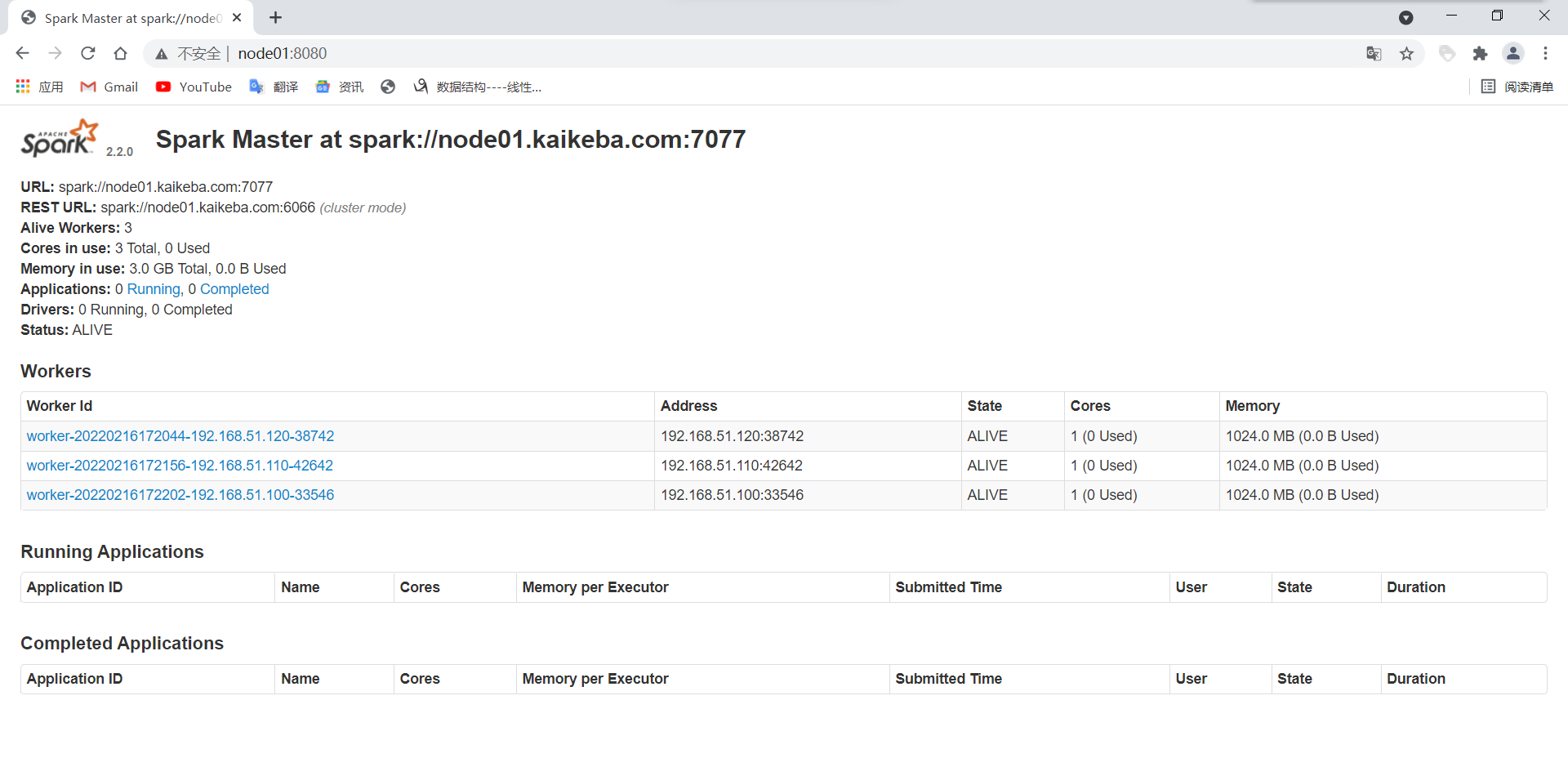
(8) 验证:访问主节点的8080端口来查看集群信息 http://node01:8080/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY