
Mysql事务探索及其在Django中的实践(二)
继上一篇《Mysql事务探索及其在Django中的实践(一)》交代完问题的背景和Mysql事务基础后,这一篇主要想介绍一下事务在Django中的使用以及实际应用给我们带来的效率提升。
首先贴上Django官方文档中关于Database Transaction一章的介绍:https://docs.djangoproject.com/en/1.9/topics/db/transactions/。
在Django中实现事务主要有两种方式:第一种是基于django ORM框架的事务处理,第二种是基于原生地执行SQL语句的transaction处理。
基于django ORM框架的事务处理
默认情况下,django的事务处理是自动提交(auto-commit),即在执行model.save(),model.delete()时,所有的改动会被立即提交,相当于数据库设置了auto commit,没有任何隐藏的rollback。
在网上查了一些资料,了解到django手动配置事务的方式主要有三种:第一种是将一个http request的所有数据库操作包裹在一个transaction中,第二种是通过transaction中间件对http请求的事务拦截,第三种是自己在view中通过装饰器灵活控制事务(我们的平台最后用的就是这一种)。
1.将一个http request的所有数据库操作包裹在一个transaction中
这种方式配置非常简单,只需要在settings.py中的database配置中加入‘ATOMIC_REQUESTS’: True即可。如图1所示:
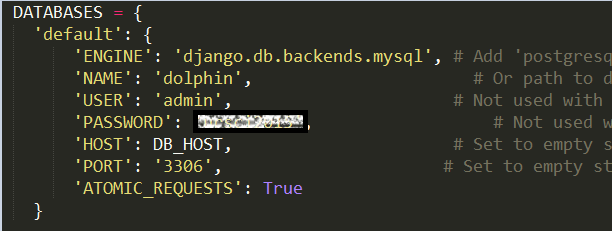
图1 Database中加入'ATOMIC_REQUESTS':True
通过这种配置,django在调每个view方法之前会开始一个事务,当且仅当该响应没有任何问题,django才会提交这个事务;如果view中出现了异常,则django会回滚该事务。这样做的好处显而易见,就是安全简便,但是随着网站的流量变大,如果每个view被调用时都打开一个事务就会变得有点繁重,从而会降低网站的效率。它对性能的影响取决于你的应用的查询效率以及你的数据库处理锁的能力。此外,使用这种方式,回退的只是数据库的状态,而不包括其他非数据库项的操作,例如发送email等。
2.通过transaction中间件对http请求的事务拦截
配置方法是在settings.py中配置MIDDLEWARE_CLASSES,如图2所示:
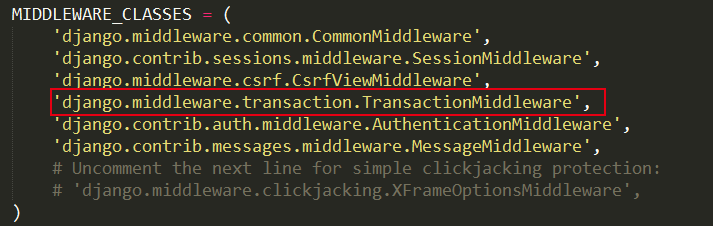
图2 transaction中间件配置
需要注意的是,这样配置之后,与你中间件的配置顺序是有很大关系的。在 TransactionMiddleware 之后的所有中间件都会受到事务的控制。但CacheMiddleware,UpdateCacheMiddleware,FetchFromCacheMiddleware 这些中间件不会受到影响,因为cache机制有自己的处理方式,用了内部的connection来处理。另外TransactionMiddleware 只对默认的数据库配置有效,如果要对另外的数据连接用这种方式,必须自己实现中间件。(此处必须声明,对于这种方法,本人没有仔细研究过,只是借鉴了一下网上的资料)
3.自己在view中通过装饰器灵活控制事务
最后种方式,通过装饰器灵活配置,也是我们平台最后采用的方式。
1)@transaction.autocommit
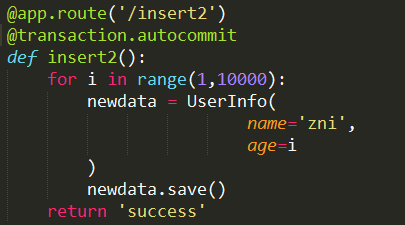
django默认的事务处理,采用此装饰模式这种方式可以忽视全局的transaction配置。
2)@transaction.commit_on_success
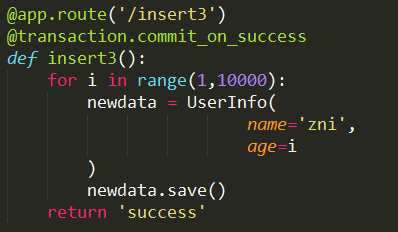
采用此装饰模式,当此方法的所有工作完成后,才会提交事务。
3)@transaction.commit_manually
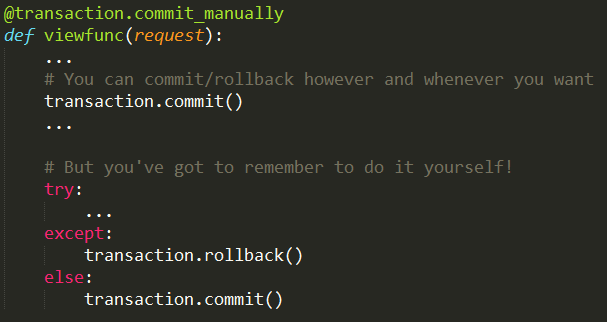
采用这种方式,你可以自由地随意提交或回滚事务,完全自己处理。如果没有调用commit()或rollback(),则程序会抛出TransactionManagementError异常。
基于原生地执行SQL语句的transaction处理
再来讲讲Django中第二种事务处理方式,即用原生地执行SQL语句的方式。
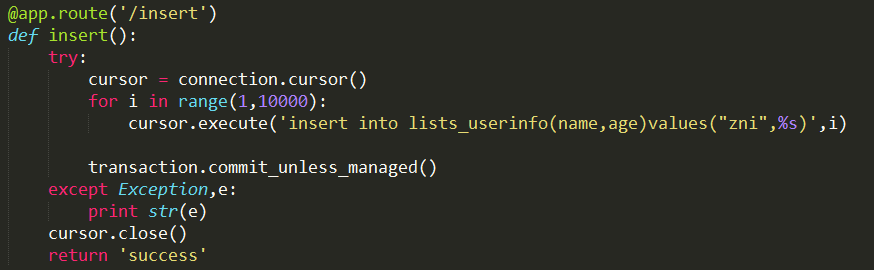
图3 原生地执行SQL语句中的事务处理
这种处理方式比较简单,以图3中的方法为例,首先定义了一个游标cursor,通过cursor任意地执行sql语句,最后通过transaction.commit_unless_managed()来提交事务。
延伸
上面介绍了Django中的两种事务处理的方式,到这里我突然想到一个问题:
如果一个方法中既包含了装饰器@transaction.commit_on_success,又执行了原生SQL语句的事务提交,当方法出现异常导致事务回滚时,原生的SQL语句所提交的事务会不会被回滚?
为了验证这个问题,我用Flask写了两个接口来进行验证:
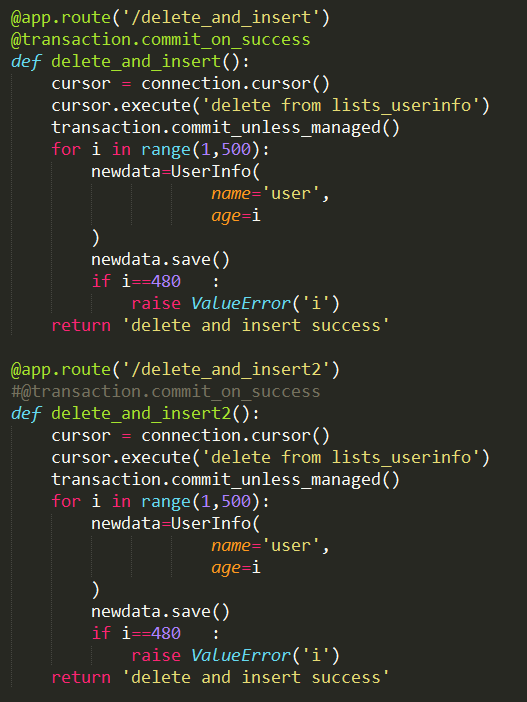
接口delete_and_insert和接口delete_and_insert2都是先通过cursor事务提交执行清除表,然后往表里循环插入数据,当满足条件i=480的时候,抛出一个ValueError。唯一的区别就是接口1中采用了装饰器@transaction.commit_on_success,而接口2中没有。实际执行发现:
1.在调接口1时,原数据库表中的数据不会变化,说明通过cursor执行清除表的操作也会回滚。
2.在调接口2时,原数据库表中的数据被删除,数据库留下的是新的数据:所有的name都为user,而age从1到480。
从而证明,当view方法加了装饰器@transaction.commit_on_success后,即使view中使用了cursor执行原生sql语句,并执行了transaction.commit_unless_managed(),但是如果view中有异常抛出,整个view方法的内容都会回滚。
实际应用
最后,回归最初的问题本身,当我把事务应用到我们平台的后台接口中后,发现了一个意外的惊喜:接口A的执行时间从原来的5-10分钟一下子缩短到了几秒钟就完成了。欣喜之余仔细思考了一下才觉得性能显著提升的原因应该是:在应用事务之前,所有SQL语句都是自动提交的,每插入一条数据,数据库表的索引可能就需要重建一次,当大量的sql语句逐一插入时,数据库表的索引就需要不断地重建,其中就需要耗费大量的时间。而在应用事务之后,所有的插入是一次性提交,数据库表的索引只需要重建一次,大大减少了开销。
这也验证了数据库的索引不是万能的,合理的建立索引确实能大大地优化查询速度,因为索引的存储结构就像一本字典一样,我们在查找某个特定的字时会根据拼音的首字母的方式先找到该字的第一个字母所在页数,然后直接跳到那一页往后去翻。然而这也决定了字典在初始存储这些字时就需要根据这些字的特点将每个字放在特定的存储位置。当有新的字加入时,为了插入到特定的位置,就必须重新建立映射关系。
补充:合理建立索引
下面是我工作中搜集的一些关于索引建立的规则,也欢迎大家参考,指正:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号