[CMU 15-418] (Lecture2) A Modern Multi-Core Processor
本系列文章为 CMU 15-418/15-618: Parallel Computer Architecture and Programming, Fall 2018 课程学习笔记
课程官网:CMU 15-418/15-618: Parallel Computer Architecture and Programming
参考文章:CMU 15-418 notes
相关资源与介绍:CMU 15-418/Stanford CS149: Parallel Computing - CS自学指南
Forms of parallelism: multicore, SIMD, threading + understanding latency and bandwidth
Part 1 parallel execution

Part 2 access memory
术语:延迟与带宽的区别

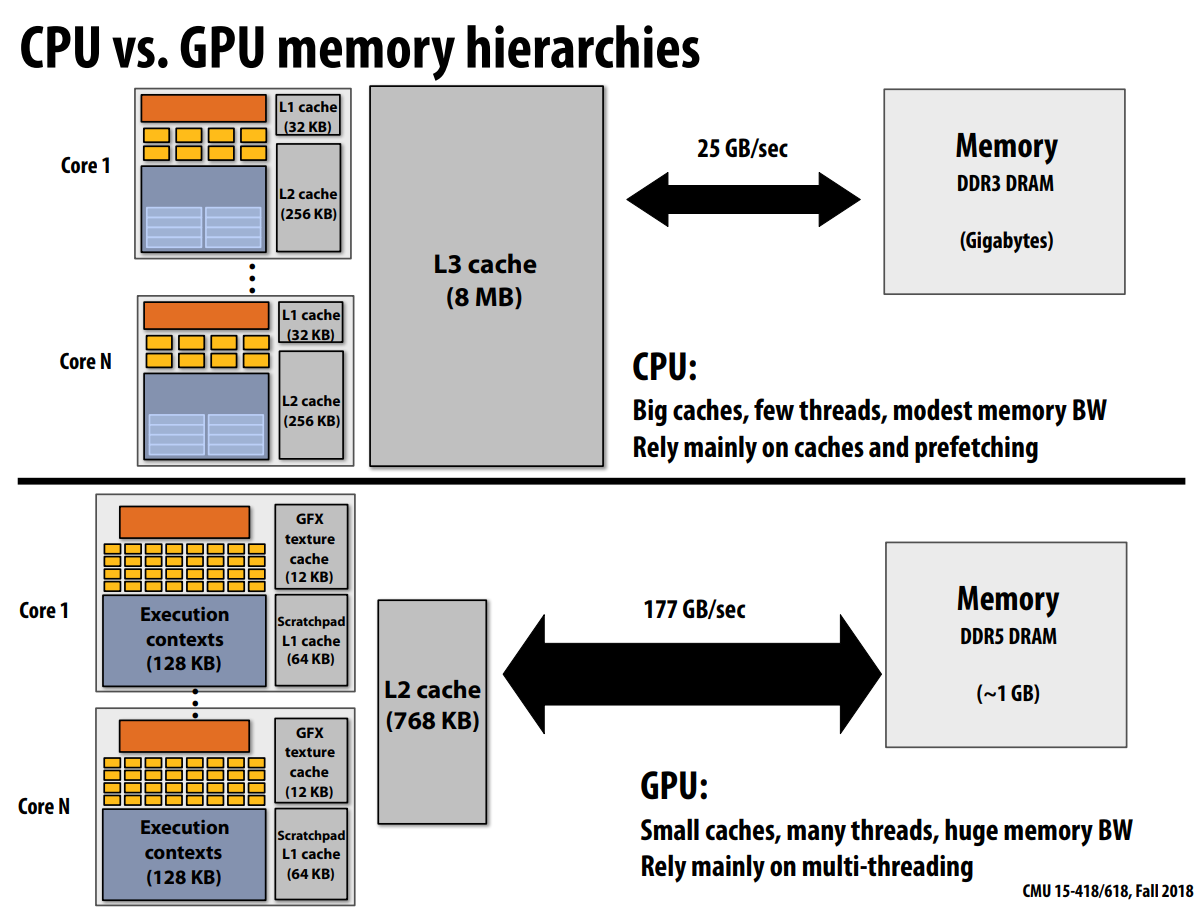
CPUs利用预取(prefeching)来隐藏(hide而不是reduce)访存阻塞(Hiding stalls)
GPUs利用多线程(multi-threading)来隐藏访存阻塞
GPUs一般需要自己的更高速的memory而不是主存,同时其caches更小,级数更少
Interleaved multi-threading是指相对粗粒度的多线程操作,每个核仍然是在执行一个指令流,出现延迟操作时可以切换线程,由CPU以及硬件进行调度
SMT是多线程与超标量的结合,即一个核不止执行一个指令流中的单条命令,而是可以执行若干线程中的若干指令,相当于指令级别(ILP)的粒度

一个线程的ILP不够时就可以用SMT来达到更高的ILP
Costs:
- 需要更多的空间保存线程上下文(multi-thread)
- 增加了单一线程的运行时间
- 需要更高的带宽,因为更多的线程->更大的工作集->每个线程的缓存空间减少->更经常访问主存

Examples
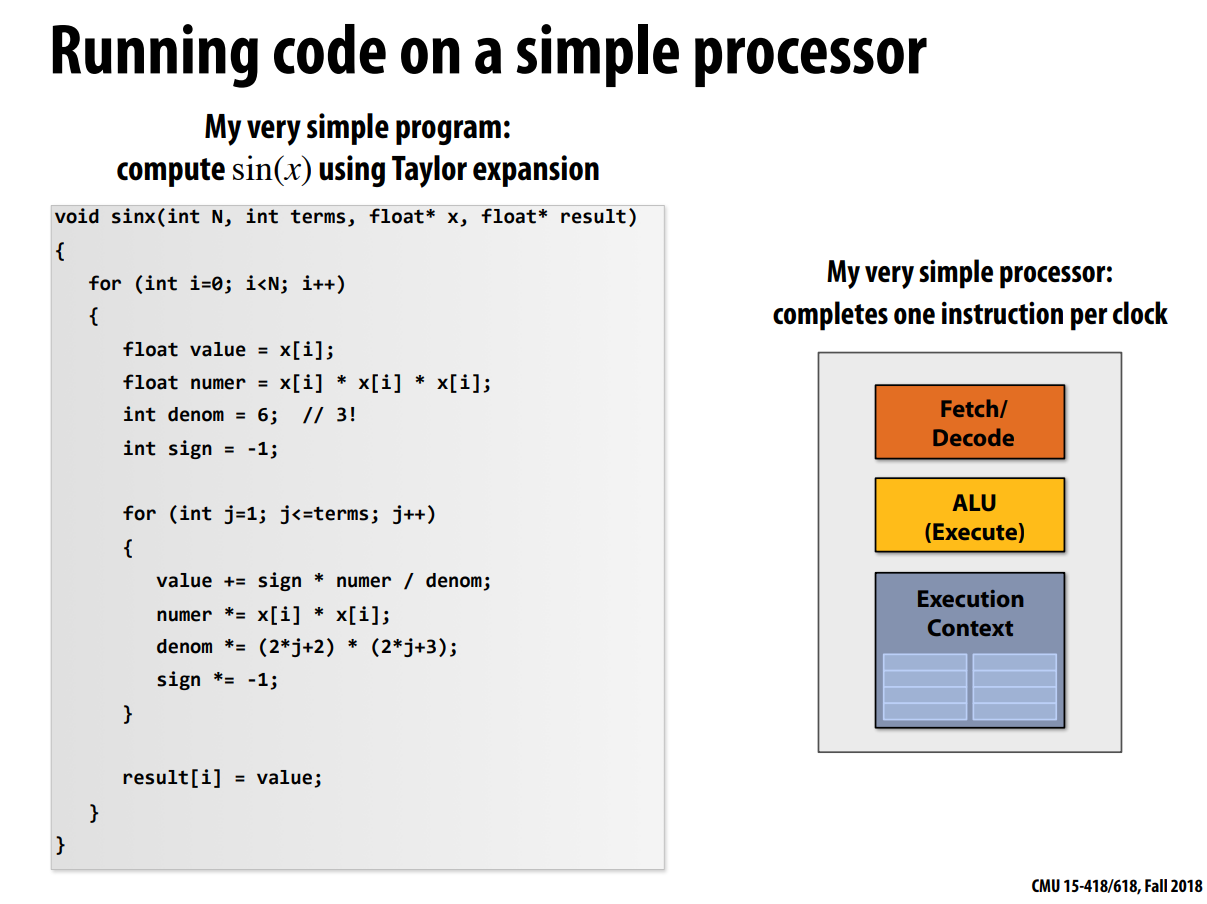
超标量(superscalar)执行 (ILP)
从一个指令流中每次选出多条指令执行,有多个取指令与ALU硬件
需要处理器在执行阶段检测出在指令流中独立(independent)的操作
每个核每个时钟周期执行多条指令
如图:每个时钟周期执行2条指令

多核(multi-core)执行
使用pthread并将其划分为两个指令流
有多个指令流,每个指令流进入一个核中执行
每个核每个时钟周期执行一条指令
如图:2个核每个时钟周期执行1条指令 = 2条指令per clock

多核+超标量执行
每个核每个时钟周期执行多条指令
如图:2个核每个时钟周期执行2条指令 = 4条指令per clock

四核
使用independent loop iterations
如图:4个核每个时钟周期执行1条指令 = 4条指令per clock

SIMD(single instruction multiple data)单指令流多数据流
SIMD宽度不是byte或bit而是value个数(总宽度/数据类型大小)
总宽度多大要看使用的数据类型MMX SSE AVX等(和要使用的寄存器大小有关)SIMD
如图:4个核每个时钟周期执行1个SIMD指令 = 4个SIMD指令per clock
每个SIMD指令不一定能达到宽度倍数的指令效果,因为如果有条件判断(if else)情况,需要全都执行,然后通过掩码进行舍弃

使用multi-thread技术来hide stalls
有多个线程执行上下文
能够在遇见stalls时切换指令流

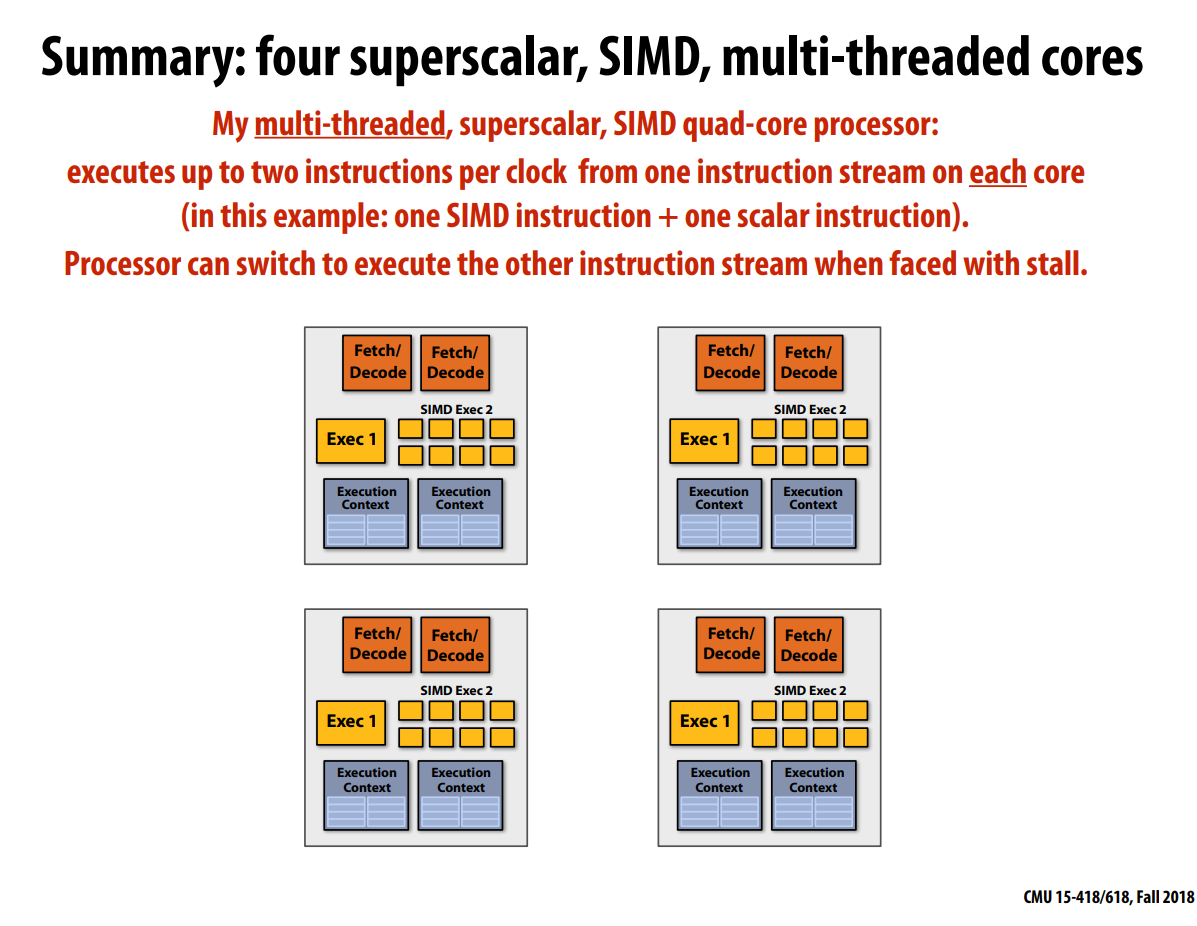
综合 超标量与SIMD与多线程
一个芯片的所有结构连接在一起结果
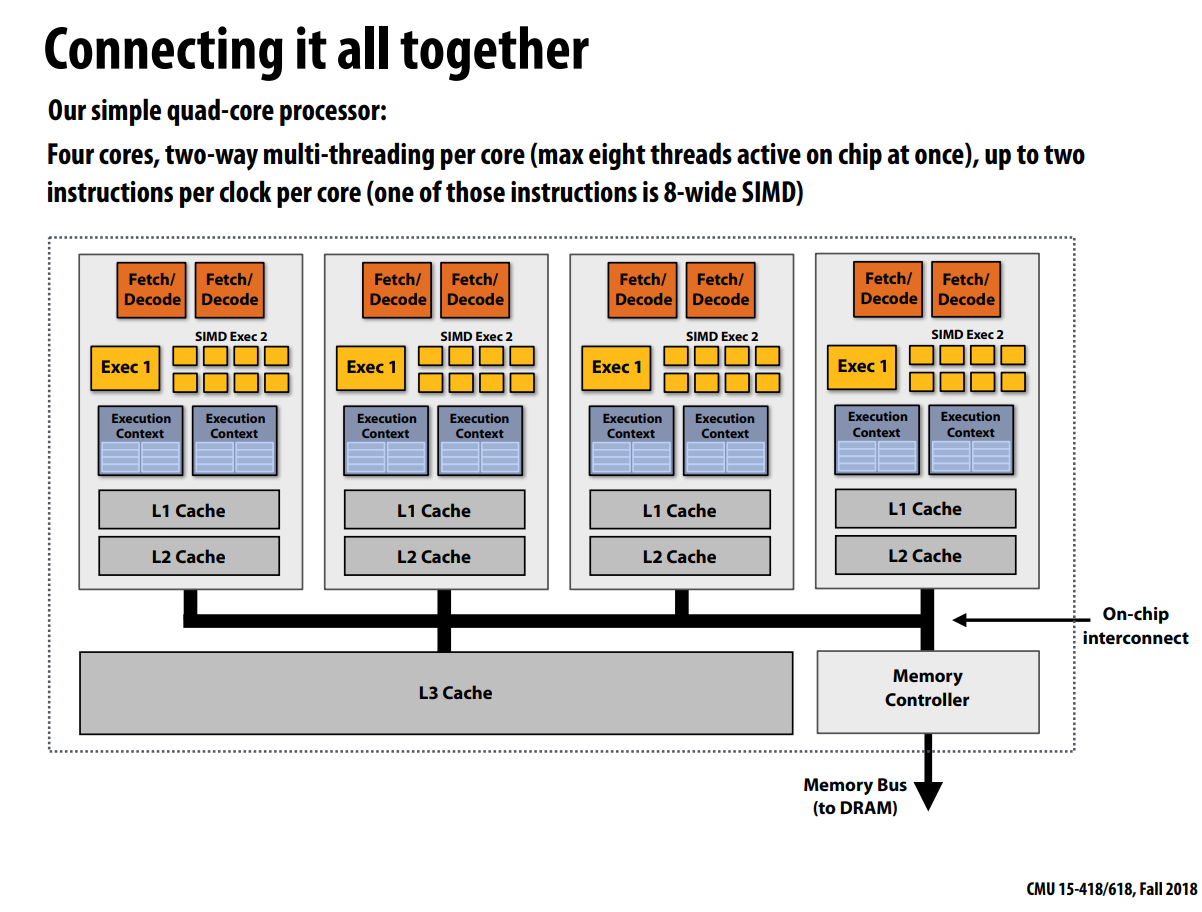
Summary
芯片CPUs/GPUs的运算能力一般远远大于访问内存的速度,所以许多并行程序被存储带宽(memory bandwidth)所限制

需要了解的术语:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号