寒假作业(2/2)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21/homework/11672 |
| 这个作业的目标 | 对《构建之法》提出几个具体问题以及对词频统计作业的描述 |
| GitHub地址 | https://github.com/Zmeiting/PersonalProject-Java |
| 其他参考文献 | 无 |
- 关于《构建之法》提出的几个具体问题
- 问题及回答
- 1、 P33 为什么使用了int count=m_wordList.Count 后System.Collection.ArrayList.get_Count的调用次数和实践都大幅度减少
- 2、 P51 瓦茨总结说,软件领域分为技艺创新的大爆发和坚持不懈的工程工作,而其中工程工作占了90%-95%的比例,那么剩下的技艺创新具体体现在哪些方面呢?怎么看出来有技艺创新?
- 3、 P65 程序设计进行到一半,发现自己原来设计中存在弱点,要解决这个弱点才能避免额外工作,但是如果现在改变设计,会不会让公司、同事以为自己能力不行?
- 4、 P86 结对编程虽然能够不间断地复审,使代码质量提高,但是编写效率明显下降,要怎么比较质量和时间哪个更重要?怎么能够看出项目是结对编程更好还是个人编程更好?
- 5、 P117 当自己想认领某个任务时,发现自己不具备足够的知识去完成这个任务,而团队里面其他成员对这个任务不感兴趣时,该怎么办?有些人认领的多,有些人认领的少,忙闲不均怎么办?
- 6、 P142 高质量的代码在当用户改变了需求,并且这个需求非常模糊时,是否要舍弃掉之前的高质量代码,选择重新编写?
- 冷知识
- 问题及回答
- 关于词频统计作业的描述
关于《构建之法》提出的几个具体问题
问题及回答
1、 P33 为什么使用了int count=m_wordList.Count 后System.Collection.ArrayList.get_Count的调用次数和实践都大幅度减少
2、 P51 瓦茨总结说,软件领域分为技艺创新的大爆发和坚持不懈的工程工作,而其中工程工作占了90%-95%的比例,那么剩下的技艺创新具体体现在哪些方面呢?怎么看出来有技艺创新?
答:软件工程有这三个方面的技术要素:软件工程的方法(开发方法)、工具(支持方法的工具)、过程(管理过程),其中管理过程应该是比较稳定的,《构建之法》后面提到过每个公司都有自己的开发模式和管理模式,所以在这方面创新应该比较少,其次是工具,包括编程语言编程软件什么的,这些一般是由编程软件的开发公司来进行创新更新,而使用者一般不会去创新,最后,最优可能创新的就是方法,如何提高程序运行的效率就在如何写出高质量的方法。
3、 P65 程序设计进行到一半,发现自己原来设计中存在弱点,要解决这个弱点才能避免额外工作,但是如果现在改变设计,会不会让公司、同事以为自己能力不行?
答:对于公司来讲,公司的利益肯定大于自己个人的利益的,所以如果选择不解决弱点把弱点留给同事来做的话,不仅让老板觉得你能力不行,同事也会看不起你,倒不如直接坦诚相告,早点解决问题比较好。
4、 P86 结对编程虽然能够不间断地复审,使代码质量提高,但是编写效率明显下降,要怎么比较质量和时间哪个更重要?怎么能够看出项目是结对编程更好还是个人编程更好?
答:如果两个人的编程水平都比较高的话,就不需要结对编程,因为结对编程主要是为了提高代码质量,而一个人写出来的代码已经足够好了,就不用修改,而如果两个人水平都比较低的话,还是结对编程比较好,这样能找出对方的错误,从而改进
5、 P117 当自己想认领某个任务时,发现自己不具备足够的知识去完成这个任务,而团队里面其他成员对这个任务不感兴趣时,该怎么办?有些人认领的多,有些人认领的少,忙闲不均怎么办?
答:任务一定要有人做,倒不如接了这个任务,迫使自己去获得更多的知识。忙闲不均的时候,比如说有的人已经完成了任务,那这时候也可以进行结对编程,刚好有人帮你看看你的代码有没有明显错误,但是看得那个人最好不要想修改代码,因为一眼看过去的肯定没有编程的人更了解,避免代码乱七八糟,没有统一风格。
6、 P142 高质量的代码在当用户改变了需求,并且这个需求非常模糊时,是否要舍弃掉之前的高质量代码,选择重新编写?
答:我去询问了已经在软件公司工作的学姐,虽然她负责的部分不是代码部分,但是负责与客户沟通,她说如果客户需求非常模糊时,不应该急着舍弃,而是先陪着客户弄清楚他到底想要怎样的软件,同客户讨论协商,在协商过程中比较确定的新的需求就可以开始做了,最后一步一步让软件走向成熟。
冷知识
一位军机大臣长途跋涉前来拜访编程大师。军机大臣原以为这位大师既有钱又有势,但他失望了。了看见大师身穿T 恤衫和蓝色的牛仔裤,正端坐在一间小小的工作室里。
身穿三件套的军机大臣又臂交叉抱在胸前,向下注视着大师。"你因头脑精明而著称,"军机大臣说,"那么,我问你,计算机的秘密是什么?"
大师抬起头看着军机大臣,一句话没说。随后他领着军机大臣来到花园,那里有一只蜘蛛已经在两根之间吐织出了一张网。露珠挂在网上,阳光被反向成千万条细细的彩虹。
大师低声说:"仔细看着。"然后他拾起一根细枝,轻轻碰了一下蜘蛛网,那张网便像个生灵一样颤动着。"这就是计算机的秘密。"他说。
军机大臣认为大师在嘲弄他,便捡起一块石头朝那张网扔去。石头穿网而过,那张网只留下了破碎褴褛的丝缕挂在潮湿的叶缘上。他走了,与来的时候相比,他一点也没有变聪明。
关于词频统计作业的描述
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 60 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | 420 | 600 |
| • Analysis | • 需求分析 (包括学习新技术) | 20 | 40 |
| • Design Spec | • 生成设计文档 | 60 | 50 |
| • Design Review | • 设计复审 | 10 | 60 |
| • Design | • 具体设计 | 20 | 30 |
| • Coding | • 具体编码 | 180 | 480 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Code Review | • 代码复审 | 40 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 180 | 480 |
| Reporting | 报告 | 90 | 60 |
| • Test Repor | • 测试报告 | 30 | 40 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1280 | 2065 |
解题思路描述
功能需求分析
- 统计文件的字符数(对应输出第一行):
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
-
统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
-
统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
详细分析
可执行程序命名为:WordCount.exe,该程序处理用户需求的模式为:
WordCount.exe [parameter] [input_file_name]
存储统计结果的文件默认为output.txt,放在与WordCount.exe相同的目录下
输出格式为:
characters: number
words: number
lines: number
word1: number
word2: number
结构图

代码规范链接,即github中的codestyle
https://github.com/Zmeiting/PersonalProject-Java/tree/main/221801339_zhoumeiting
模块接口的设计与实现过程
类:工具类和主函数类
函数:主函数类中逻辑主要是由循环语句和条件判断语句完成
工具类中涉及到的方法有:
返回字符数ReturnCharactersNum方法,返回查询结果(String类型),参数为输入文件的集合
返回单词数ReturnWordsNum方法,返回查询结果(String类型),参数为输入文件的集合
返回行数ReturnLinesNum方法,返回查询结果(String类型),参数为输入文件的集合
返回出现频率最高的前10个单词方法ReturnMaxWordsNum方法,返回查询结果(String类型),参数为输入文件的集合
输出结果OutputFile方法,将结果保存在文件中,返回boolean型,参数为文件路径和内容
接口部分的性能改进
1、工具类CountUtil中包含了上面所有的方法除了主函数,主函数将在测试类中设置
2、返回频率最高的前10个单词还需要另外设置一个类来实现其功能,我这里设置了WordEntity类来实现,使用了Map,这样单词和其出现的次数就可以同时输出
3、仔细审题后发现至少要四个字母开头才算单词,并且中文在里面也得算分割符号,所以首先用正则表达式把所有非字母数字替换成空格,然后使用substring方法取所有单词的前四个字符(如果没有到四个字符就直接不算是单词),用循环语句来判断是否为字母
4、因为测试次数较多,所以不想每次手动清空测试文本中的内容,所以在OutputFile中设置清空文件内容功能
5、又发现作业要求中要求输出格式为小写格式,所以再对字符串进行判断,将为大写字母的字母都变为小写
模块部分单元测试展示
1、全是字母符号

2、全是数字符号


3、全是中文符号
这里我多按了两个回车


4、字母中有中文夹杂

这里输出很奇怪,一种是中字后面的单词没了,一种是跟中文字临近的一个字母没了,我也不知道怎么解决,百度了也不懂

5、字母中有数字夹杂(在前四个字母内,不在前四个字母内)


6、单词符号个数没到4个

7、全是大写字母符号


8、写一个测试类进行大量字符测试,我设置的是1000个



模块部分异常处理说明
1、题目要求是能同时输入输出文件名和输入文件名,我现在已经写了多个输入(方便多种情况测试),然后固定一个输出文件路径,暂时不知道如何同时输入多个文件输入和多个文件输出,所以先固定一个输出文件路劲为E:\output.txt
2、在求字符数时如果用字节数组进行求解的话,得先用字符串导入文本后,把中文替换掉,再把字符串转变成字节数组进行字符数加减,所以不需要考虑中文的意思是就是直接使用字节数组?
3、英文夹杂中文那个bug突然好像知道是为什么了,可能是因为中文是两个英文字母,把中文替换掉空格之后是有两个空格,然后第一个空格进行分割了,后续的跟后面的字母组成了一个单词?但是对于最后一种情况,把中文字后面的一个字母一起消掉了也无法理解,一个字母去掉后后面的又可以输出了?
4、使用cmd进行译码时不能直接javac,还要加上-encoding utf8 因为好像默认是用GBK
Converage结果
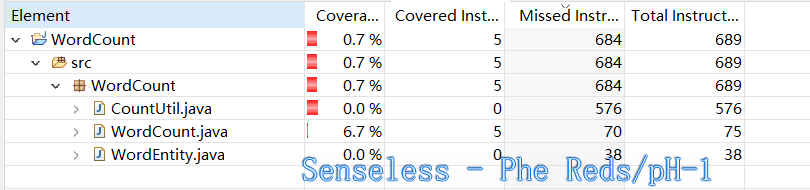
一直是红色的,不太懂为什么
关键代码
CountUtil类
返回字符数
in = new FileInputStream(file_path);//得到字符输入流,string为文件绝对路径
while ((bytes = in.read(item,0,len))!=-1) {
count+=bytes;//统计累计读取的字符数,一个英文字符占一个字节
}
result += "characters: "+count+"\n";//结果字符串拼接
count = 0;
返回单词数
tmp = saveString.toString(); //用字符串存储,以用split方法区分单词
//tmp.replaceAll("[\\W]|_", " ");//所有非字母数字符号替换成空格
tmp=tmp.replaceAll("[^A-Za-z0-9]", " ");//替换所有非字母数字的符号为空格
tmp=tmp.toLowerCase();//全部变为小写方便计算前四个是否为字母
String [] total = tmp.split("[\\s+]");//单词以空格分割
count=total.length;
for(int i=0;i<total.length;i++)
{
String s=total[i].toString();
if(s.length()<4)
{
count--;
}
else
{
for(int j=0;j<4;j++)
{
char c=s.charAt(j);
if(!(c>='a'&&c<='z'))//只要是字母都已经换成小写了
{
count--;
break;
}
}
}
}
result += "words: "+count+"\n"; //结果字符串拼接
count=0;
返回行数
while(bis.readLine()!=null)
{
count++;
}
result += "lines: "+count+"\n"; //结果字符串拼接
count=0;
返回次数最多的前10个单词
Map<String,Integer>map = new HashMap<String, Integer>();//运用哈希排序的方法进行排序
tmp = saveString.toString(); //用字符串存储,以用split方法区分单词
tmp=tmp.replaceAll("[^A-Za-z0-9]", " ");//所有非字母数字符号替换成空格
tmp=tmp.toLowerCase();//全部换成小写
StringTokenizer st = new StringTokenizer(tmp," ");//分割字符串
//把分割好的单词保存在letter字符串中
while (st.hasMoreTokens())
{
String letter = st.nextToken();
int count;
if (map.get(letter) == null) {
count = 1;//表明了没有进行分割。
} else {
count = map.get(letter).intValue() + 1;
}
map.put(letter,count);
}
Set<WordEntity> set = new TreeSet<WordEntity>();
for (String key : map.keySet()) {
set.add(new WordEntity(key,map.get(key)));
}
int count=1;
for (Iterator<WordEntity> it = set.iterator(); it.hasNext();) {
WordEntity w = it.next();
boolean isWords=true;
if(w.getKey().length()>4)
{
String s=w.getKey();
for(int i=0;i<4;i++)
{
char c=s.charAt(i);
if(!(c>='a'&&c<='z'))//只要是字母都已经换成小写了
{
isWords=false;
break;
}
}
if(isWords==true)
{
result+=w.getKey()+": "+w.getCount()+"\n";
if(count==10)
{
break;
}
count++;
}
}
}
输出文件
if(!OutputFile.exists()) { //判断文件是否存在
OutputFile.createNewFile(); //不存在,创建一个文件
}
FileWriter fileWriter =new FileWriter(File_path);//设置清空文件内容功能
fileWriter.write("");
fileWriter.flush();
fileWriter.close();
os = new FileOutputStream(OutputFile); //获得输出流对象
a = Context.getBytes(); //将Context转化为Byte数组,以便写入文件
os.write(a); //将byte数组写入文件
结合在构建之法中学到的内容,写下心得
1、虽然项目很小,但是编程真的写了很久,包括计划设计开发测试总结,太多太多了,一方面是能感到自己的编程水平还不够,一方面又想到《构建之法》中的团队协作编程,包括结对编程啊等等,每个人负责一个部分,就能做到又快又精,效率很高。
2、debug部分真的太累了,测试时间是开发时间的好几倍,不仅要考虑还有什么功能没有实现,还要测试数据要求是否有达到,有没有编译错误
3、对使用Converage来进行运行效率观察,还不会使用,WordCount这个程序还是红色的很多,不知道怎么解决,希望未来与小组成员共同编程能学到更多
4、如果可以的话,想在未来跟小组成员都试试《构建之法》上提到的几个开发模式
5、学无止境
6、《构建之法》还有两个问题不会,一个是编程上的问题,一个是实际问题
