MapReduce经典案例——数据去重
MapeReduce经典案例————数据去重
1、案例分析:
(1)测试文件:
-
File1.txt:
2018-3-1 a
2018-3-2 b
2018-3-3 c
2018-3-4 d
2018-3-5 a
2018-3-6 b
2018-3-7 c
2018-3-3 c -
File2.txt
2018-3-1 b
2018-3-2 a
2018-3-3 b
2018-3-4 d
2018-3-5 a
2018-3-6 c
2018-3-7 d
2018-3-3 c
(2)案例实现:
-
Map阶段实现
package cn.itcast.mr.dedup; //Map阶段实现 import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class DedupMapper extends Mapper<LongWritable, Text, Text, NullWritable> { private static Text field = new Text(); // <0,2018-3-3 c><11,2018-3-4 d> @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { field = value; context.write(field, NullWritable.get()); } // <2018-3-3 c,null> <2018-3-4 d,null> } -
Reducer阶段
package cn.itcast.mr.dedup; //Reducer阶段 import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class DedupReducer extends Reducer<Text, NullWritable, Text, NullWritable> { // <2018-3-3 c,null> <2018-3-4 d,null><2018-3-4 d,null> @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } -
Driver程序主类实现
package cn.itcast.mr.dedup; //Driver程序主类实现 import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class DedupDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(DedupDriver.class); job.setMapperClass(DedupMapper.class); job.setReducerClass(DedupReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("E:\\hadoop\\fileStorage\\DataDeduplication\\input")); // 指定处理完成之后的结果所保存的位置 FileOutputFormat.setOutputPath(job, new Path("E:\\hadoop\\fileStorage\\DataDeduplication\\output\\dow")); job.waitForCompletion(true); } }
(3)效果测试:
-
程序执行效果

-
本地主机查看
-
打开part-r-00000文件
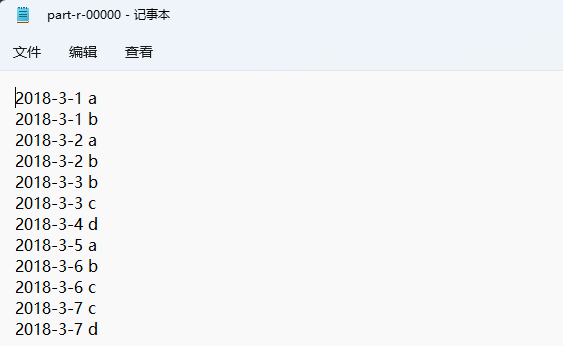
-
Finish

 浙公网安备 33010602011771号
浙公网安备 33010602011771号