PBFT共识算法详解
PBFT(Practical Byzantine Fault Tolerance,实用拜占庭容错)
一.概述
拜占庭将军问题最早是由 Leslie Lamport 在 1982 年发表的论文《The Byzantine Generals Problem 》提出的, 他证明了在将军总数大于 3f ,背叛者为f 或者更少时,忠诚的将军可以达成命令上的一致,即 3f+1<=n 。算法复杂度为 O(nf+1) 。而 Miguel Castro 和 Barbara Liskov 在1999年发表的论文《 Practical Byzantine Fault Tolerance 》中首次提出 PBFT算法,该算法容错数量也满足 3f+1<=n,也即最大的容错作恶节点数f=(n-1)/3。算法复杂度为 O(n2),将系统的复杂度由指数级别降低为多项式级别,使得拜占庭容错算法在实际系统应用中变得可行。
那么为什么PBFT算法的容错数量满足3f+1<=n呢?
因为 PBFT 算法的除了需要支持容错故障节点之外,还需要支持容错作恶节点。假设集群节点数为 N,有问题的节点为 f。有问题的节点中,可以既是故障节点,也可以是作恶节点,或者只是故障节点或者只是作恶节点。那么会产生以下两种极端情况:
- 这f 个有问题节点既是故障节点,又是作恶节点,那么根据少数服从多数的原则,集群里正常节点只需要比f个节点再多一个节点,即 f+1 个节点,确节点的数量就会比故障节点数量多,那么集群就能达成共识,即总节点数为f+(f+1)=n,也就是说这种情况支持的最大容错节点数量是 (n-1)/2。
- 故障节点和作恶节点都是不同的节点。那么就会有 f 个作恶节点和 f 个故障节点,当发现节点是作恶节点后,会被集群排除在外,剩下 f 个故障节点,那么根据少数服从多数的原则,集群里正常节点只需要比f个节点再多一个节点,即 f+1 个节点,确节点的数量就会比故障节点数量多,那么集群就能达成共识。所以,所有类型的节点数量加起来就是 f+1 个正常节点,f个故障节点和f个作恶节点,即 3f+1=n。
结合上述两种情况,因此PBFT算法支持的最大容错节点数量是(n-1)/3。
二.PBFT共识算法流程
角色划分
-
Client:客户端节点,负责发送交易请求。
-
Primary: 主节点,负责将交易打包成区块和区块共识,每轮共识过程中有且仅有一个Primary节点。
-
Replica: 副本节点,负责区块共识,每轮共识过程中有多个Replica节点,每个Replica节点的处理过程类似。
其中,Primary和Replica节点都属于共识节点。
算法流程
PBFT 算法的基本流程主要有以下四步:
- 客户端发送请求给主节点
- 主节点广播请求给其它节点,节点执行PBFT算法的三阶段共识流程。
- 节点处理完三阶段流程后,返回消息给客户端。
- 客户端收到来自 f+1 个节点的相同消息后,代表共识已经正确完成。
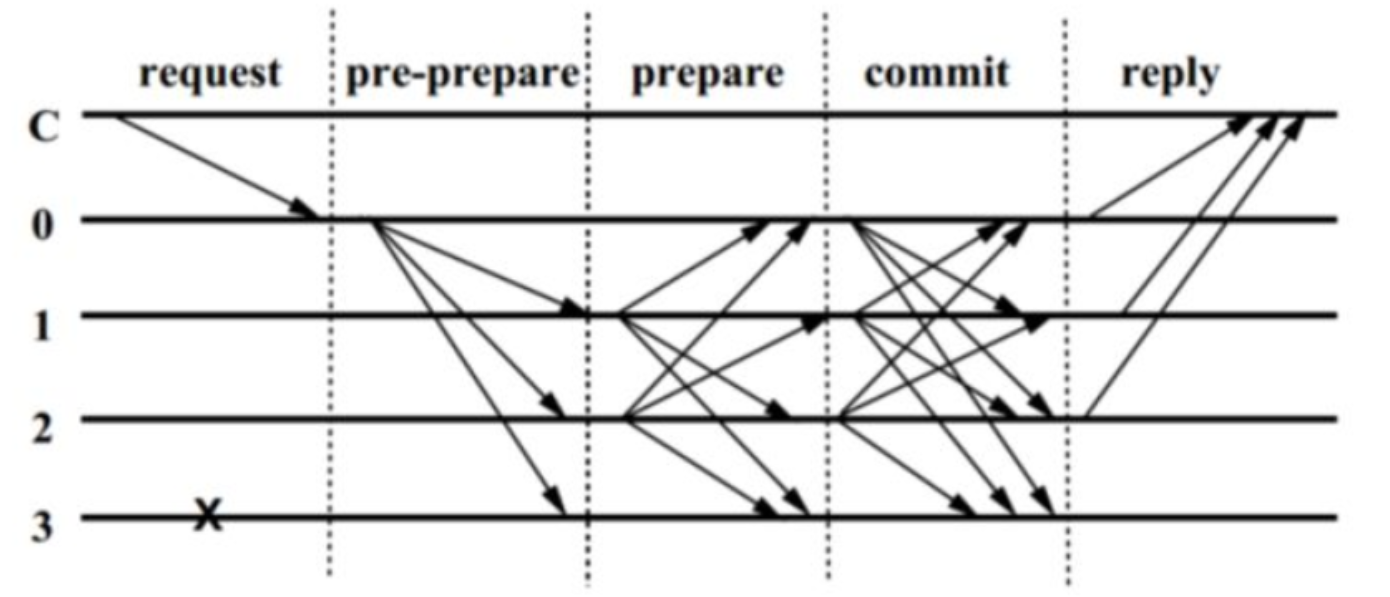
算法的核心三个阶段分别是 pre-prepare 阶段(预准备阶段),prepare 阶段(准备阶段), commit 阶段(提交阶段)。图中的C代表客户端,0,1,2,3 代表节点的编号,其中0 是主节点primary,打×的3代表可能是故障节点或者是作恶节点,这里表现的行为就是对其它节点的请求无响应。整个过程大致是如下:
首先,客户端向主节点0发起请求<<REQUEST,o,t,c>> 其中t是时间戳,o表示操作,c是这个client,主节点收到客户端请求,会向其它节点发送 pre-prepare 消息,其它节点就收到了pre-prepare 消息,就开始了这个核心三阶段共识过程了。
-
Pre-prepare 阶段:副本节点replica收到 pre-prepare 消息后,会有两种选择,一种是接受,一种是不接受。什么时候才不接受主节点发来的 pre-prepare 消息呢?一种典型的情况就是如果一个replica节点接受到了一条 pre-prepare 消息
<<PRE_PREPARE,v,n,d>,m>,其中,v 代表视图编号(视图的编号是什么意思呢?比如当前主节点为 A,视图编号为 1,如果主节点换成 B,那么视图编号就为 2),n代表序号(主节点收到客户端的每个请求都以一个编号来标记),d代表消息摘要,m代表原始消息数据。消息里的 v 和 n 在之前收到里的消息是曾经出现过的,但是 d 和 m 却和之前的消息不一致,或者请求编号n不在高低水位之间,这时候就会拒绝请求。拒绝的逻辑就是主节点不会发送两条具有相同的 v 和 n ,但 d 和 m 却不同的消息。Replia节点接收到pre-prepare消息,进行以下消息验证:
- 消息m的签名合法性,并且消息摘要d和消息m相匹配:d=hash(m)
- 节点当前处于视图v中
- 节点当前在同一个(view v ,sequence n)上没有其它pre-prepare消息,即不存在另外一个m'和对应的d' ,d'=hash(m')
- h<=n<=H,H和h代表序号n的高低水位。
-
Prepare 阶段:当前节点同意请求后会向其它节点发送 prepare 消息
<PREPARE,v,n,d,i>同时将消息记录到log中,其中i用于表示当前节点的身份。同一时刻不是只有一个节点在进行这个过程,可能有 n 个节点也在进行这个过程。因此节点是有可能收到其它节点发送的 prepare 消息的,当前节点i验证这些prepare消息和自己发出的prepare消息的v,n,d三个数据是否都是一致的。验证通过之后,当前节点i将prepared(m,v,n) 设置为true,prepared(m,v,n) 代表共识节点认为在(v,n)中针对消息m的Prepare阶段是否已经完成。在一定时间范围内,如果收到超过 2f 个其他节点的prepare 消息,就代表 prepare 阶段已经完成。最后共识节点i发送commit消息并进入Commit阶段。 -
Commit 阶段:当前节点i接收到2f个来自其他共识节点的commit消息
<COMMIT,v,n,d,i>同时将该消息插入log中(算上自己的共有2f+1个),验证这些commit消息和自己发的commit消息的v,n,d三个数据都是一致后,共识节点将committed-local(m,v,n)设置为true,committed-local(m,v,n)代表共识节点确定消息m已经在整个系统中得到至少2f+1个节点的共识,而这保证了至少有f+1个non-faulty节点已经对消息m达成共识。于是节点就会执行请求,写入数据。
处理完毕后,节点会返回消息<<REPLY,v,t,c,i,r>>给客户端,当客户端收集到f+1个消息后,共识完成,这就是PBFT算法的全部流程。
三.垃圾回收
根据前面的算法部分可以发现,我们需要不断地往log中插入消息,在view change时恢复需要用到。于是log很快就会变得很占内存,这时候需要有一种方式清理掉无用的log。当某一request已经被f+1个正常节点执行完毕后,并当view change可以向其他节点证明当前状态的正确性,与该request相关的message就可以删除了。
每执行一个request就产生一次证明效率过于低下,论文中是每处理一定的request后产生一次证明。也就是当request的序号n % C ( 某 一 定 值 ) =0时,产生一个checkpoint,节点i多播消息<<CHECKPOINT,n,d,i>>给其他节点,当节点接收2f+1个消息时,该checkpoint变为stable checkpoint,也就是这2f+1个节点可以证明该状态的正确性,同时可以删除序号≤n的消息相关的log信息和checkpoint信息。
什么是 checkpoint 呢? checkpoint 就是当前节点处理的最新请求序号。前文已经提到主节点收到请求是会给请求记录编号的。比如一个节点正在共识的一个请求编号是101,那么对于这个节点,它的 checkpoint 就是101。
什么是 stable checkpoint (稳定检查点)呢?stable checkpoint 就是大部分节点 (2f+1个) 已经共识完成的最大请求序号。比如系统有 4 个节点,三个节点都已经共识完了的请求编号是 213 ,那么这个 213 就是 stable checkpoint 了,也就可以删除213 号之前的记录了。
什么是高低水位呢?低水位就是stable checkpoint的序号n,高水位是stable checkpoint的序号n + K,其中K是定值,一般是C(上面提及到的某一定值)的整数倍。
四.视图更换(view change)
正常情况下,client将request发给一个主节点primary,然后主节点将request多播到其他节点replica,进行一个view。然而当主节点出错或成为恶意节点时,就需要进行视图更换(view change),也就是选择(轮换法)下一个replica节点作为主节点,视图编号v进行+1操作,共识过程进入下一个view。
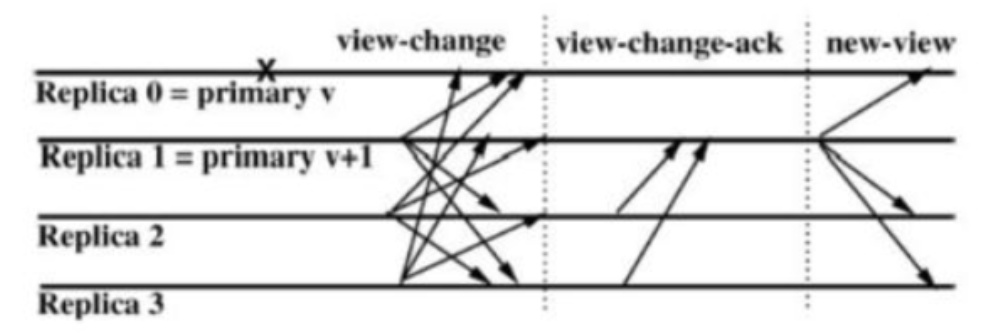
如图所示, view change 会有三个阶段,分别是 view-change , view-change-ack 和 new-view 阶段。replica节点认为主节点primary有问题时,会向其它节点发送 view-change 消息<<VIEW−CHANGE,v+1,n,C,P,i>> 其中:
- v:上一个视图编号
- n:节点i的stable checkpoint的编号
- C:2f+1个节点的有效checkpoint信息的集合
- P:节点i中的上一个视图中编号大于n并且达到prepared状态的请求消息的集合
- i:节点的编号
当前存活的节点编号最小的节点将成为新的主节点。当新的主节点收到 2f 个其它节点的 view-change 消息,则证明有足够多人的节点认为主节点有问题,于是就会向其它节点广播 new-view 消息<<NEW-VIEW,v+1,V,O>>
其中:
-
v:上一个视图编号
-
V:新的主节点接收到的有效的视图编号为v+1的view-change消息集合
-
O:pre-prepare消息的集合。假设 O 集合里消息的编号范围:(min~max),则 Min 为 V 集合最小的 stable checkpoint , Max 为 V 集合中最大序号的 prepare 消息。最后一步执行 O 集合里的 pre-preapare 消息,每条消息会有两种情况: 如果 max-min>0,则产生消息 <<pre-prepare,v+1,n,d>> ;如果 max-min=0,则产生消息 <<pre-prepare,v+1,n,d(null)>>
注意:replica节点不会发起 new-view 事件。对于主节点,发送 new-view 消息后会继续执行上个视图未处理完的请求,从 pre-prepare 阶段开始。其它节点验证 new-view 消息通过后,就会处理主节点发来的 pre-prepare 消息,这时执行的过程就是前面描述的PBFT过程。到这时,正式进入 v+1 (视图编号加1)的时代了。
五.优缺点
优点:
- 通信复杂度O(n2),解决了原始拜占庭容错(BFT)算法效率不高的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错算法在实际系统应用中变得可行。
- 首次提出在异步网络环境下使用状态机副本复制协议,该算法可以工作在异步环境中,并且通过优化在早期算法的基础上把响应性能提升了一个数量级以上。作者使用这个算法实现了拜占庭容错的网络文件系(NFS),性能测试证明了该系统仅比无副本复制的标准NFS慢了3%。
- 使用了加密技术来防止欺骗攻击和重播攻击,以及检测被破坏的消息。消息包含了公钥签名(RSA算法)、消息验证编码(MAC)和无碰撞哈希函数生成的消息摘要(message digest)。
缺点:
- 仅仅适用于permissioned systems (联盟链/私有链)。
- 通信复杂度过高,可拓展性比较低,一般的系统在达到100左右的节点个数时,性能下降非常快。
- PBFT在网络不稳定的情况下延迟很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号