
二、kafka的文件存储机制
简图:

producer 将数据写入kafka后,集群需要对数据进行保存。
kafka将数据保存在磁盘,kafka初始会单独开辟一块磁盘空间,顺序写入(效率比随机写入高)。
1、partition结构
partition在服务器上表现形式是一个个文件夹,生产者将生产的消息不断追加到log文件的末尾,为防止log文件过大导致数据定位效率低,kafka采取分片和索引的机制,将每个partition分为多个segment。
每组segment文件包含 .index文件、.log文件 、.timeindex文件。
log和index文件位于一个文件夹下,该文件夹命名规范为: topic名称+分区序号。例如:simon这topic有2个分区,对应的文件夹 simon-0 、simin-1

log文件就是实际存储message的地方,二index和timeindex文件为索引文件,用于检索消息。

2、message 结构
log 文件就实际是存储 Message 的地方,我们在 Producer 往 Kafka 写入的也是一条一条的 Message。
消息主要包含:
Offset:Offset 是一个占 8byte 的有序 id 号,它可以唯一确定每条消息在 Parition 内的位置;
消息大小:消息大小占用 4byte,用于描述消息的大小;
消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
index和log文件以当前segment的第一条消息的offset命名,下图为index文件和log文件的结构示意图:
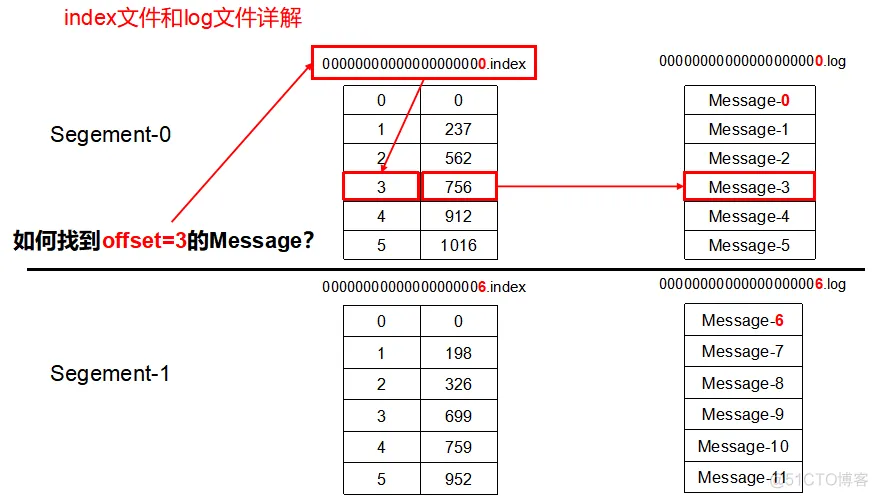
例如:进入simon-0目录下查看

3、存储策略
无论消息是否被消费,Kafka 都会保存所有的消息。那对于旧数据有什么删除策略呢?
基于时间,默认配置是 168 小时(7 天);
基于大小,默认配置是 1073741824。
需要注意的是,Kafka 读取特定消息的时间复杂度是 O(1),所以这里删除过期的文件并不会提高 Kafka 的性能。
原文:https://blog.51cto.com/u_56701/9656766


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?