一、kafka的工作流程
工作流程:
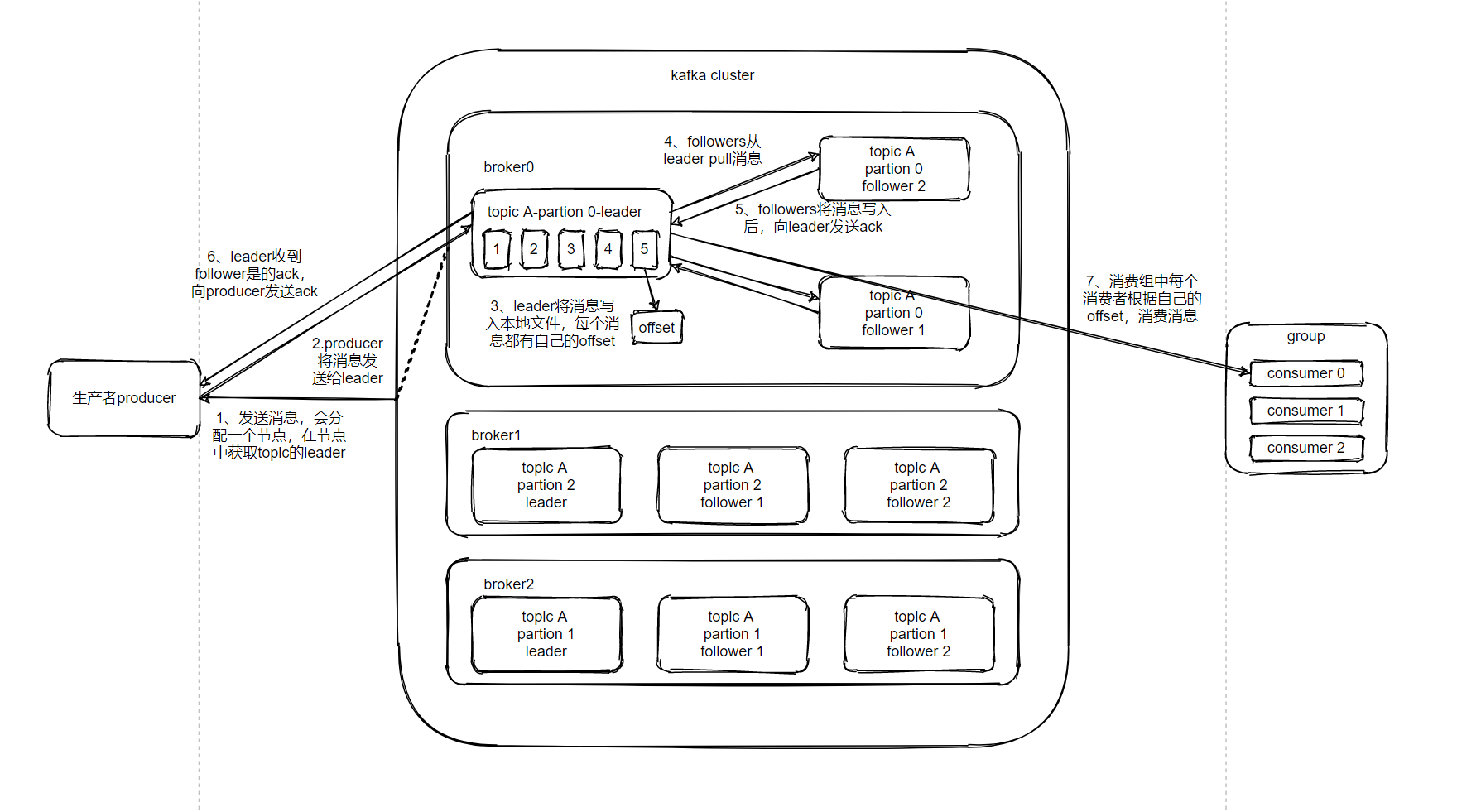
如图所示哈,整个工作环境包括:
一个生产者(producer),
一个消费者组(含有三个消费者),
一个主题:A,
三个节点(broker),
三个分区(partition),
三个副本(副本数=1个leader+2个follower)。
注意事项:
1、kafka中的消息都是面向topic进行分类,生产消息、消费消息都是面向topic。
2、每个分区都有消息的编号,成为偏移量(offset),它的作用是可以让消费者追踪消息在分区里的位置。注意:偏移量不是全局的,是分区独立使用的。因此,kafka只保证分区内消息的有序(生产顺序和消费顺序相同)。
3、topic是逻辑的概念,而partition是物理上的概念,每个partition都有自己的对应的log文件,该log文件存储就是producer生产的数据。producer生产的数据会被不断地追加到该log文件末端(log文件太大时会被切分),且每条数据都有自己的offset。
4、消费者组中的每个消费者,都会实时记录自己消费的offset,消费消息;如果出错复活后,从上次的位置继续消费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号