Prometheus监控Docker主机
cAdvisor(Container Advisor)用于收集正在运行的容器资源使用和性能信息
一.Docker运行cAdvisor
sudo docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8899:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
二、访问cAdvisor
http://10.210.13.20:8899
三、Prometheus对接cAdvisor
- job_name: 'dev_docker'
scrape_interval: 5s
static_configs:
- targets: ['10.210.13.20:8899']
四、重启Prometheus容器
docker restart prometheus
五、Grafana添加模板
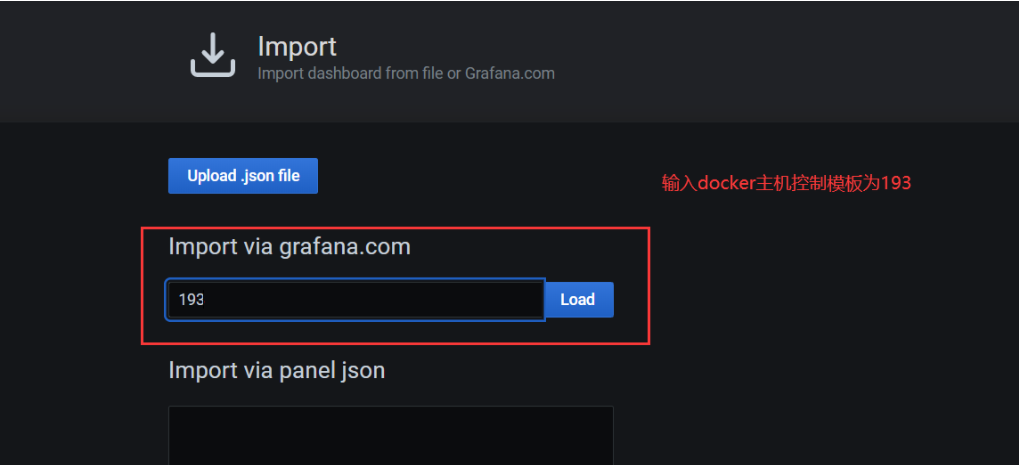
但是这个模板,无法选择根据主机选择。推荐另外一个模板,它是可以选择主机的。
https://grafana.com/grafana/dashboards/10566
六、配置告警:我们新创建一个规则文件:alert_rules.yml,把它和prometheus.yml放在一起,官方有一个模板 Templating,直接copy过来
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
上面规则文件大意:就是创建了2条alert规则 alert: InstanceDown 和 alert: APIHighRequestLatency :
InstanceDown 就是实例宕机(up==0)触发告警,5分钟后告警(for: 5m);
APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警
七、重启Prometheus容器
docker restart prometheus

 浙公网安备 33010602011771号
浙公网安备 33010602011771号