概率论与数理统计——中心极限定理
中心极限定理
零基础到精通概率论的重要内容——中心极限定理
作者:bhh
一、证明的关键思路
本节目的为概括方法,并推动接下来的代数运算。
1、基础知识
(1)、矩母函数:具备一个随机变量各阶中心矩的函数(正如其名)
2、正题
为了证明Zn收敛于服从标准正态分布的随机变量Z,我们只需要证明当|t| < δ 时, MZn (t) → MZ(t). 虽然矩母函数的收敛性貌似蕴含着相应概率密度函数的收敛性,但这是证明中最难的一步。因此我们需要正确地说明这一点。后续我们将会用到复分析里证明两个函数相等的方法,其中一种就是证明它们关于一大类测试函数又相同的积分。当然,困难在于(1)证明存在大量测试函数与其作用可以产生相等的积分,(2)证明积分相等会迫使函数相等。上述计算肯定存在问题。如果不知道被积函数是什么,我们如何证明积分相等呢?那么我们可以利用极限的思想,不去证明积分相等,而是证明某些极限是相等的,从而避免使用概率密度函数的精确卷积公式的痛苦。
二、中心极限定理的陈述
我们在概率中见过许多分布, 其中最重要的就是正态分布.。衡量某个量或概念对某个主题重要程度的一种方法是, 看一看我们使用了多少个不同的名称来指代它。对这个分布而言, 其名称包括正态分布、高斯分布和钟形曲线。
1、定义——正态分布

中心极限定理有很多版本.。它们之间的区别既包括假设条件又包括最终的收敛类型。不足为奇,我们假设的性质越好, 收敛性就越强, 证明也就越简单。这一点在我们学习数学分析的收敛时早有体会。接下来给出的这个定理,虽然不是最一般化的,但很容易陈述,并且我们遇到的大多数分布都能满足它的假设。
2、定理——中心极限定理(CLT)
设X1,X2...,Xn时独立同分布的随机变量

那么,当N → ∞ 时, Zn 的分布会收敛于标准正态分布。
存在这么一种解释上述内容的方法:不妨认为样本总体是描述某个过程或某种现象的N个相互独立的测量值。那么 就是这些值的平均数。且因为Xi均取自于某个常见的分布,并且期望具有线性性质,所以
就是这些值的平均数。且因为Xi均取自于某个常见的分布,并且期望具有线性性质,所以
又由Xi的独立性,我们易得
因此XN 的标准差是σ/√N。注意,当N →∞时,XN 的标准差趋向于0。这就引出了下列解释:随着测量次数的不断增加, 平均值的分布会越来越接近于真实的均值。把 Xn 的平均值记作 XN 是为了强调我们有 N 个随机变量的和。
补充一下:我们在这里需要弄清楚什么是正态分布非常重要。他描述的是一群Xi,这些Xi可以服从一个“好”的分布。服从正态分布的是Xi的平均值。但平均值的分布似乎与Xi的分布形状(Xi的序列如何排列)无关? 关于这一感觉,是错觉——平均值怎么可能与选取随机变量的分布无关呢,事实上,平均值确实与最初的分布有关,然而这种关系非常微弱。我们不难看出,基本分布的形状决定了正态分布的收敛速度。(贝里-埃森定理)
此外,我们要切记数学课上的基本概念,熟悉公式中的每一个字母。
三、均值、方差与标准差
虽然我们之前已经学习过均值、方差与标准差,但是我们有必要在这里再花些时间仔细地看一下这些概念,因为它们在《中心极限定理》中发挥着重要的作用。你对基本概念越熟悉,就越可能理解其中证明的论述次序。

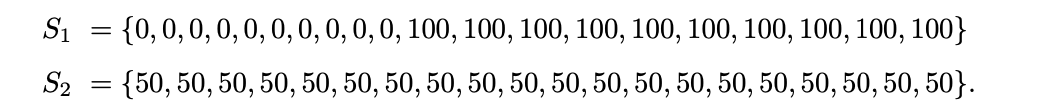
这里讲述两种基本方法来计算概率。接下来我们的讨论对于S1。第一种方法是把每个观察结果都视作不同的测量值。在这种情况下,x1=x2=...=x10=0,x11=x12=...=x20=100,每个值的概率为1/20。第二种方法是,认为x1=0点概率是1/2,x2=100的概率是1/2。但是要注意,虽然这两种方法所考察的数据点的个数不同,但被计算的量是一样的。(补充一下方法二,对于不同的值,把它们出现的频率认定为概率)
这里提供一个不错的测试:试证明不管xi等于多少,这两种方法总是给出相同的均值和方差。
四、 标准化
在上一节中,我们看到的随机变量的方差不是衡量波动水平的正确尺度,因为方差的单位是错误的。比如X是以秒为单位的,那么方差的单位就是“平方秒”这一神秘的物理单位。而标准差具有与X相同的单位,所以我们用标准差来描述数据集的分布情况。
找到讨论问题的正确尺度或单位是非常重要的。下面举一个例子:假设有一门数分课,其中学生完全相同,但老师不同(学生的学习能力是一样的) 。我们假设其中一位老师出的期末考试题非常简单,但另一位老师出了地狱难度的题目。如果第一门考试的李华取得了92分,第二门考试的张超取得了84分,那么哪个学生更优秀呢?如果没有其它信息,我们很难给出判断(甚至不能给出判断)
假设我们对这两门考试有更多了解,不妨设第一门课 (考试较简单的那门课) 的平均成绩是 97, 而标准差是 1;第二门课的平均成绩是 64, 且标准差是 10。这样以来,我们便很轻松地看出,张超在数分这门课上是比李华更优秀的学生(优绩主义)
1、定义
设 X 是一个均值为 μ 且标准差为 σ 的随机 变量, 并且 μ 和 σ 都是有限的. X 的标准化变量 Z 被定义为

标准化的过程是非常自然的,它把任意一个“好”的随机变量重新调整为均值为0且方差为1的心变量。我们需要的唯一假设是——这个变凉存在有限的均值和标准差。这是一个弱条件的假设,但不是所有分布都能满足这一点。例如柯西分布,这个分布显然没有有限的方差,且存在有争议的均值。
为了保持完整性,我们看看如何对一个随机变量做出调整,从而使其均值为0且方差为1。把X变换为(X-E[X])/StDev(X)即可。
五、证明一般的中心极限定理(CLT)
为了完成证明, 可以利用好几种方法来解决代数运算。 我们选择下列方法的原因是, 它强调了数学中最重要的技巧之一:每当看到乘积时, 你都应该认真考虑把它替换成一个和。这样做是因为我们有很多求和经验。 我们有计算特殊和的公式, 也可以利用泰勒级数把一个好函数展开成一个和。对于乘积, 我们了解的并不多, 也不清楚该如何把一个函数展开成乘积形式。
因此我们只需要先取对数,当完成分析后,再对该式取指数。我们有
注意,在上面的展开式中,对于固定的t,第一项的大小取决于√N。如果它不能被另外某相抵消,那么极限是不存在的。幸运的事,它被抵消了,而我们只关心 1/N 之前的项。 关注这么小的项是因为我们要乘以 N. 然而, 1/N3/2(N的二分之三次方)或更小的项不会在极限中发挥作用, 因为它们乘以 N 之后仍然很小。

但我们想求的是MX 在 t/σ√N 处的值, 而不是在 t 处的值。于是
![]() ,次数更低的项统统认为误差项。
,次数更低的项统统认为误差项。
在对上式展开并合并后,我们得到了中心极限定理:
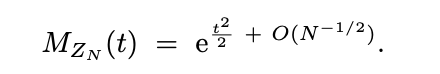
注意!!在上述证明中,舍弃t的三次方及更高次项时,必须要小心。因此我们利用了矩母函数在|t| < δ 时会收敛这一假设来说明矩不会过快地增长,从而使的这些项在极限中不会发挥作用。
这里给出一道拓展题目:
在证明中心极限定理时, 我们考察了 logMX(t/σ√N) 的级数展开式 (其中,
X 的矩母函数在 |t| < δ 时收敛) 并且只讨论到 t 的平方项. 关于这一点, 给出严格的 证明. 如果愿意的话, 你可以为这些矩添加一些较强的假设, 例如存在某个 ε > 0 使得 |μ′n| = O(n!1−ε).
-------------------------------------------
个性签名:生而为人,就要活的好
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号