数据类型
介绍
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的
详细参考链接:http://www.runoob.com/mysql/mysql-data-types.html
mysql常用数据类:
#1. 数字: 整型:tinyint int bigint 小数: float :在位数比较短的情况下不精准 double :在位数比较长的情况下不精准 0.000001230123123123 存成:0.000001230000 decimal:(如果用小数,则用推荐使用decimal) 精准 内部原理是以字符串形式去存 #2. 字符串: char(10):简单粗暴,浪费空间,存取速度快 root存成root000000 varchar:精准,节省空间,存取速度慢 sql优化:创建表时,定长的类型往前放,变长的往后放 比如性别 比如地址或描述信息 >255个字符,超了就把文件路径存放到数据库中。 比如图片,视频等找一个文件服务器,数据库中只存路径或url。 #3. 时间类型: 最常用:datetime #4. 枚举类型与集合类型 enum 和set
一 . 数值类型
整数类型 : tinyint , smallint , mediumint , int , bigint
作用 : 存储年龄 , 等级(比如腾讯的 vip ,svip....) , id , 各种号码等


======================================== tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127 无符号: ~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 ======================================== int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: ~ 4294967295 ======================================== bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: ~ 18446744073709551615
验证1 : 有符号和无符号 tinyint
============有符号tinyint============== # 创建数据库db4 create database db4 charset utf8; # 切换到当前db4数据库 mysql> use db4; # 创建t1 规定x字段为tinyint数据类型(默认是有符号的) mysql> create table t1(x tinyint); # 验证,插入-1这个数 mysql> insert into t1 values(-1); # 查询 表记录,查询成功(证明默认是有符号类型) mysql> select * from t1; +------+ | x | +------+ | -1 | +------+ #执行如下操作,会发现报错。因为有符号范围在(-128,127) mysql> insert into t1 values(-129),(128); ERROR 1264 (22003): Out of range value for column 'x' at row 1 ============无符号tinyint============== # 创建表时定义记录的字符为无符号类型(0,255) ,使用unsigned mysql> create table t2(x tinyint unsigned); # 报错,超出范围 mysql> insert into t2 values(-129); ERROR 1264 (22003): Out of range value for column 'x' at row 1 # 插入成功 mysql> insert into t2 values(255); Query OK, 1 row affected (0.00 sec)
验证2 : int 类型后面的存储是显示宽度,而不是存储宽度
mysql> create table t3(id int(1) unsigned); #插入255555记录也是可以的 mysql> insert into t3 values(255555); mysql> select * from t3; +--------+ | id | +--------+ | 255555 | +--------+ ps:以上操作还不能够验证,再来一张表验证用zerofill 用0填充 # zerofill 用0填充 mysql> create table t4(id int(5) unsigned zerofill); mysql> insert into t4 value(1); Query OK, 1 row affected (0.00 sec) #插入的记录是1,但是显示的宽度是00001 mysql> select * from t4; +-------+ | id | +-------+ | 00001 | +-------+ row in set (0.00 sec)
注意:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,存储范围如下
其实我们完全没必要为整数类型指定显示宽度,使用默认的就可以了
默认的显示宽度,都是在最大值的基础上加1
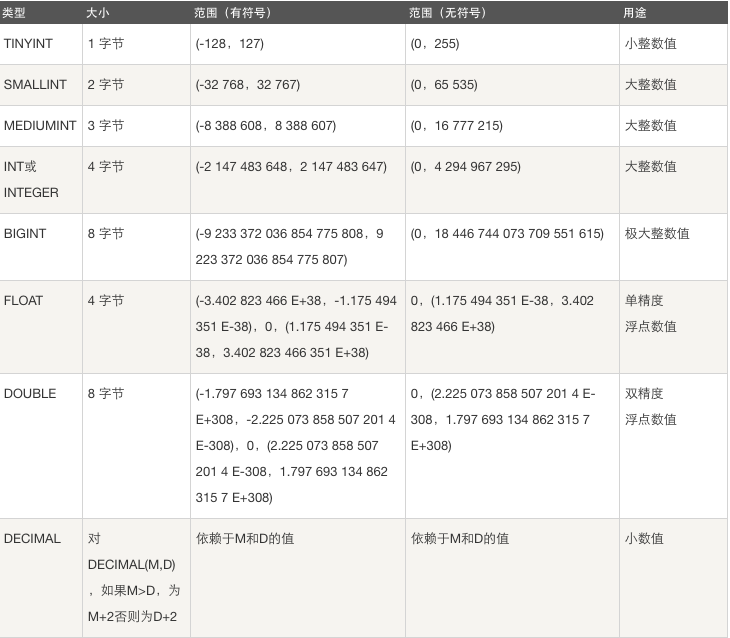
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok.
二 . 浮点型
定点数类型: dec 等同于 declmal
浮点类型:float double
作用:存储薪资、身高、体重、体质参数等
语法:
-------------------------FLOAT------------------- FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] #参数解释:单精度浮点数(非准确小数值),M是全长,D是小数点后个数。M最大值为255,D最大值为30 #有符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 #无符号: 1.175494351E-38 to 3.402823466E+38 #精确度: **** 随着小数的增多,精度变得不准确 **** -------------------------DOUBLE----------------------- DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] #参数解释: 双精度浮点数(非准确小数值),M是全长,D是小数点后个数。M最大值为255,D最大值为30 #有符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 #无符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 #精确度: ****随着小数的增多,精度比float要高,但也会变得不准确 **** ====================================== --------------------DECIMAL------------------------ decimal[(m[,d])] [unsigned] [zerofill] #参数解释:准确的小数值,M是整数部分总个数(负号不算),D是小数点后个数。 M最大值为65,D最大值为30。 #精确度: **** 随着小数的增多,精度始终准确 **** 对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。
验证三种类型建表 :
#1验证FLOAT类型建表: mysql> create table t5(x float(256,31)); ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30. mysql> create table t5(x float(256,30)); ERROR 1439 (42000): Display width out of range for column 'x' (max = 255) mysql> create table t5(x float(255,30)); #建表成功 Query OK, 0 rows affected (0.03 sec) #2验证DOUBLE类型建表: mysql> create table t6(x double(255,30)); #建表成功 Query OK, 0 rows affected (0.03 sec) #3验证deimal类型建表: mysql> create table t7(x decimal(66,31)); ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30. mysql> create table t7(x decimal(66,30)); ERROR 1426 (42000): Too big precision 66 specified for column 'x'. Maximum is 65. mysql> create table t7(x decimal(65,30)); #建表成功 Query OK, 0 rows affected (0.00 sec)
验证三种类型的精度 :
# 分别对三张表插入相应的记录 mysql> insert into t5 values(1.1111111111111111111111111111111);#小数点后31个1 Query OK, 1 row affected (0.01 sec) mysql> insert into t6 values(1.1111111111111111111111111111111); Query OK, 1 row affected (0.01 sec) mysql> insert into t7 values(1.1111111111111111111111111111111); Query OK, 1 row affected, 1 warning (0.00 sec) # 查询结果 mysql> select * from t5; #随着小数的增多,精度开始不准确 +----------------------------------+ | x | +----------------------------------+ | 1.111111164093017600000000000000 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select * from t6; #精度比float要准确点,但随着小数的增多,同样变得不准确 +----------------------------------+ | x | +----------------------------------+ | 1.111111111111111200000000000000 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select * from t7; #精度始终准确,d为30,于是只留了30位小数 +----------------------------------+ | x | +----------------------------------+ | 1.111111111111111111111111111111 | +----------------------------------+ 1 row in set (0.00 sec)
总结 :
小数 : float : 在为数比较短的情况下不精确 double : 在为数比较长的情况下不精确 0.000001230123123123 存成:0.000001230000 decimal : 精确 , 内部原理是以字符串形式去存.#(推荐)
三 . 日期类型
date , time , datetime , timestamp , year .
作用 : 存储用户注册时间,文章发布时间 , 员工入职时间,出生时间 , 过期时间等.
语法: YEAR YYYY(1901/2155) DATE YYYY-MM-DD(1000-01-01/9999-12-31) TIME HH:MM:SS('-838:59:59'/'838:59:59') DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
验证 :
1 . year
mysql> create table t8(born_year year);
#无论year指定何种宽度,最后都默认是year(4) Query OK, 0 rows affected (0.03 sec) #插入失败,超出范围(1901/2155) mysql> insert into t8 values -> (1900), -> (1901), -> (2155), -> (2156); ERROR 1264 (22003): Out of range value for column 'born_year' at row 1 mysql> select * from t8; Empty set (0.01 sec) mysql> insert into t8 values -> (1905), -> (2018); Query OK, 2 rows affected (0.00 sec) #插入记录成功 Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from t8; +-----------+ | born_year | +-----------+ | 1905 | | 2018 | +-----------+ 2 rows in set (0.00 sec)
2 . date , year , datetime (*****)
#创建t9表 mysql> create table t9(d date,t time,dt datetime); Query OK, 0 rows affected (0.06 sec) #查看表的结构 mysql> desc t9; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | d | date | YES | | NULL | | | t | time | YES | | NULL | | | dt | datetime | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 3 rows in set (0.14 sec) # 调用mysql自带的now()函数,获取当前类型指定的时间 如下结构 mysql> insert into t9 values(now(),now(),now()); Query OK, 1 row affected, 1 warning (0.01 sec) mysql> select * from t9; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2018-06-09 | 09:35:20 | 2018-06-09 09:35:20 | +------------+----------+---------------------+ 1 row in set (0.00 sec)
3 . timestamp(了解)
mysql> create table t10(time timestamp); Query OK, 0 rows affected (0.06 sec) mysql> insert into t10 values(); Query OK, 1 row affected (0.00 sec) mysql> insert into t10 values(null); Query OK, 1 row affected (0.00 sec) mysql> select * from t10; +------+ | time | +------+ | NULL | | NULL | +------+ mysql> insert into t10 values(now()); Query OK, 1 row affected (0.01 sec) mysql> select * from t10; +---------------------+ | time | +---------------------+ | 2018-06-09 09:44:48 | +---------------------+ 1 row in set (0.01 sec)
datatime 和 timestamp 的区别
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。 下面就来总结一下两种日期类型的区别。 1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。 2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器, 操作系统以及客户端连接都有时区的设置。 3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。 4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP), 如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
注意事项 :
============注意啦,注意啦,注意啦=========== #1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入 #2. 插入年份时,尽量使用4位值 #3. 插入两位年份时,<=69,以20开头,比如50, 结果2050 >=70,以19开头,比如71,结果1971 create table t12(y year); insert into t12 values (50),(71); select * from t12; +------+ | y | +------+ | 2050 | | 1971 | +------+
练习 :
创建一张学生表(student),有id ,姓名 , 出生年份 , 出生的年月日 , 上学时间 , 和到学校的具体时间.
mysql> create table student( -> id int, -> name varchar(20), -> born_year year, -> birth date, -> class_time time, -> reg_time datetime -> ); Query OK, 0 rows affected (0.02 sec) mysql> insert into student values -> (1,'alex',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"), -> (2,'egon',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"), -> (3,'wsb',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13"); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from student; +------+------+-----------+------------+------------+---------------------+ | id | name | born_year | birth | class_time | reg_time | +------+------+-----------+------------+------------+---------------------+ | 1 | alex | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 | | 2 | egon | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 | | 3 | wsb | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 | +------+------+-----------+------------+------------+---------------------+ rows in set (0.00 sec)
四 . 字符类型
官网 : https://dev.mysql.com/doc/refman/5.7/en/char.html
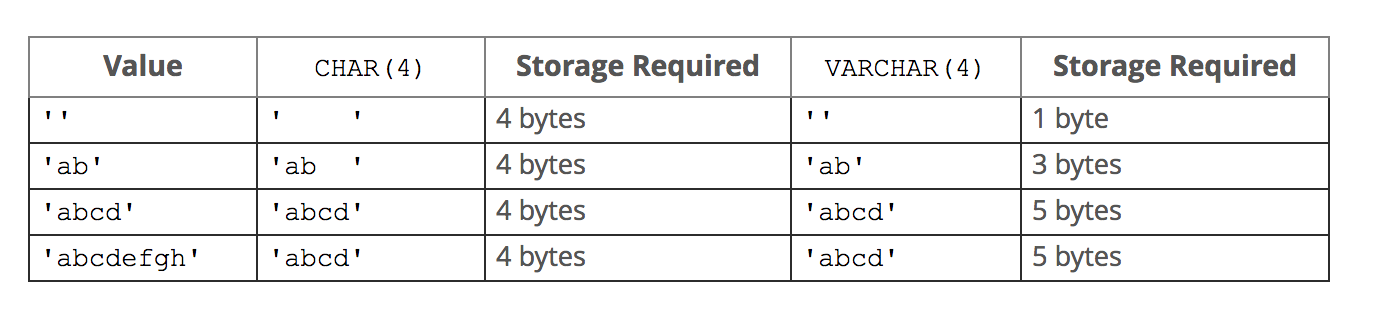
#注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(设置SQL模式:SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; 查询sql的默认模式:select @@sql_mode;) #varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html) 存储: varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
官网解释如下 :
注意 : 两个函数
length(); #查看字节数 char_length(); #查看字符数
char 填充空格来满足固定长度,但是在查询的时候却会将尾部的空格删除(装作自己没有浪费空间一样). 但是可以通过修改 sql_mode 让其现原形.
# 创建t1表,分别指明字段x为char类型,字段y为varchar类型 mysql> create table t1(x char(5),y varchar(4)); Query OK, 0 rows affected (0.16 sec) # char存放的是5个字符,而varchar存4个字符 mysql> insert into t1 values('你瞅啥 ','你瞅啥 '); Query OK, 1 row affected (0.01 sec) # 在检索时char很不要脸地将自己浪费的2个字符给删掉了,装的好像自己没浪费过空间一样,而varchar很老实,存了多少,就显示多少 mysql> select x,char_length(x),y,char_length(y) from t1; +-----------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-----------+----------------+------------+----------------+ | 你瞅啥 | 3 | 你瞅啥 | 4 | +-----------+----------------+------------+----------------+ row in set (0.02 sec) #略施小计,让char现原形 mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) #查看当前mysql的mode模式 mysql> select @@sql_mode; +-------------------------+ | @@sql_mode | +-------------------------+ | PAD_CHAR_TO_FULL_LENGTH | +-------------------------+ row in set (0.00 sec) #原形毕露了吧。。。。 mysql> select x,char_length(x) y,char_length(y) from t1; +-------------+------+----------------+ | x | y | char_length(y) | +-------------+------+----------------+ | 你瞅啥 | 5 | 4 | +-------------+------+----------------+ row in set (0.00 sec) # 查看字节数 #char类型:3个中文字符+2个空格=11Bytes #varchar类型:3个中文字符+1个空格=10Bytes mysql> select x,length(x),y,length(y) from t1; +-------------+-----------+------------+-----------+ | x | length(x) | y | length(y) | +-------------+-----------+------------+-----------+ | 你瞅啥 | 11 | 你瞅啥 | 10 | +-------------+-----------+------------+-----------+ row in set (0.02 sec)
总结 :
字符串 : char(10) : 简单粗暴 , 浪费空间,存取速度快 root 存成 root000000 varchar : 精确 , 节省空间 , 存取速度慢 sql 优化 : 创建表时, 定长的类型往前放 , 变长的往后放 >255个字符,超了就把文件路径存放到数据库中。 图片,视频等找一个文件服务器,数据库中只存路径或url。
整数 : tinyint , int , bigint 浮点型 : float , double , decimal 时间 : year , date , time , datetime 布尔类型 : boolean tinyint(1) #存1表示true , 存0表示false. 字符 : char 定长 > varchar 变长 > text 文本 #注意 : 虽然varchar使用起来比较灵活,但是从整个系统的性能角度来说,char 数据类型的处理速度更快 , text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.
五 . 枚举类型和集合类型
字段的值只能在给定的范围内选择,如单选框,多选框
enum 单选, 只能在给定的范围内选一个值,如性别 sex 男male / 女female
set 多选. 在给定的范围内可以选择一个或者多个值,(爱好1,爱好2,爱好3......)
mysql> create table consumer( -> id int, -> name varchar(50), -> sex enum('male','female','other'), -> level enum('vip1','vip2','vip3','vip4'),#在指定范围内,多选一 -> fav set('play','music','read','study') #在指定范围内,多选多 -> ); Query OK, 0 rows affected (0.03 sec) mysql> insert into consumer values -> (1,'赵云','male','vip2','read,study'), -> (2,'赵云2','other','vip4','play'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from consumer; +------+---------+-------+-------+------------+ | id | name | sex | level | fav | +------+---------+-------+-------+------------+ | 1 | 赵云 | male | vip2 | read,study | | 2 | 赵云2 | other | vip4 | play | +------+---------+-------+-------+------------+ rows in set (0.00 sec)
六 . 数据的增删改查
增删改
- 插入数据 insert
- 更新数据 update
- 删除数据 delete
一、 在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括 1.使用INSERT实现数据的插入 2.UPDATE实现数据的更新 3.使用DELETE实现数据的删除 4.使用SELECT查询数据以及。 二、插入数据 INSERT 1. 插入完整数据(顺序插入) 语法一: INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); 语法二: INSERT INTO 表名 VALUES (值1,值2,值3…值n); 2. 指定字段插入数据 语法: INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…); 3. 插入多条记录 语法: INSERT INTO 表名 VALUES (值1,值2,值3…值n), (值1,值2,值3…值n), (值1,值2,值3…值n); 4. 插入查询结果 语法: INSERT INTO 表名(字段1,字段2,字段3…字段n) SELECT (字段1,字段2,字段3…字段n) FROM 表2 WHERE …; 三、更新数据UPDATE 语法: UPDATE 表名 SET 字段1=值1, 字段2=值2, WHERE CONDITION; 示例: UPDATE mysql.user SET password=password(‘123’) where user=’root’ and host=’localhost’; 四、删除数据DELETE 语法: DELETE FROM 表名 WHERE CONITION; 示例: DELETE FROM mysql.user WHERE password=’’;
查
单表查询
语法 :
一、单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE #条件 GROUP BY field #分组查询 HAVING # 筛选 ORDER BY field #查询排序 LIMIT #限制条数 二、关键字的执行优先级(重点) 重点中的重点:关键字的执行优先级 from where group by having select distinct order by limit 1.找到表:from 2.拿着where指定的约束条件,去文件/表中取出一条条记录 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组 4.将分组的结果进行having过滤 5.执行select 6.去重 7.将结果按条件排序:order by 8.限制结果的显示条数
创建公司员工表,表的字段和数据类型
company.employee
员工id id int
姓名 name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表,设置字段的约束条件 create table employee( id int primary key auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int,#一个部门一个屋 depart_id int ); # 查看表结构 mysql> desc employee; +--------------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | emp_name | varchar(20) | NO | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(3) unsigned | NO | | 28 | | | hire_date | date | NO | | NULL | | | post | varchar(50) | YES | | NULL | | | post_comment | varchar(100) | YES | | NULL | | | salart | double(15,2) | YES | | NULL | | | office | int(11) | YES | | NULL | | | depart_id | int(11) | YES | | NULL | | +--------------+-----------------------+------+-----+---------+----------------+ rows in set (0.08 sec) #插入记录 #三个部门:教学,销售,运营 insert into employee(name ,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('xiaomage','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ; 创建员工表,并插入记录
(1) . where 约束
where子句中可以使用 1.比较运算符:>、<、>=、<=、<>、!= 2.between 80 and 100 :值在80到100之间 3.in(80,90,100)值是10或20或30 4.like 'xiaomagepattern': pattern可以是%或者_。%小时任意多字符,_表示一个字符 5.逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
验证 :
#1 :单条件查询 mysql> select id,emp_name from employee where id > 5; +----+------------+ | id | emp_name | +----+------------+ | 6 | jingliyang | | 7 | jinxin | | 8 | xiaomage | | 9 | 歪歪 | | 10 | 丫丫 | | 11 | 丁丁 | | 12 | 星星 | | 13 | 格格 | | 14 | 张野 | | 15 | 程咬金 | | 16 | 程咬银 | | 17 | 程咬铜 | | 18 | 程咬铁 | #2 多条件查询 mysql> select emp_name from employee where post='teacher' and salary>10000; +----------+ | emp_name | +----------+ | alex | | jinxin | +----------+ #3.关键字BETWEEN AND SELECT name,salary FROM employee WHERE salary BETWEEN 10000 AND 20000; SELECT name,salary FROM employee WHERE salary NOT BETWEEN 10000 AND 20000; #注意''是空字符串,不是null SELECT name,post_comment FROM employee WHERE post_comment=''; ps: 执行 update employee set post_comment='' where id=2; 再用上条查看,就会有结果了 #5:关键字IN集合查询 mysql> SELECT name,salary FROM employee WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ; +------------+---------+ | name | salary | +------------+---------+ | yuanhao | 3500.00 | | jingliyang | 9000.00 | +------------+---------+ rows in set (0.00 sec) mysql> SELECT name,salary FROM employee WHERE salary IN (3000,3500,4000,9000) ; +------------+---------+ | name | salary | +------------+---------+ | yuanhao | 3500.00 | | jingliyang | 9000.00 | +------------+---------+ mysql> SELECT name,salary FROM employee WHERE salary NOT IN (3000,3500,4000,9000) ; +-----------+------------+ | name | salary | +-----------+------------+ | egon | 7300.33 | | alex | 1000000.31 | | wupeiqi | 8300.00 | | liwenzhou | 2100.00 | | jinxin | 30000.00 | | xiaomage | 10000.00 | | 歪歪 | 3000.13 | | 丫丫 | 2000.35 | | 丁丁 | 1000.37 | | 星星 | 3000.29 | | 格格 | 4000.33 | | 张野 | 10000.13 | | 程咬金 | 20000.00 | | 程咬银 | 19000.00 | | 程咬铜 | 18000.00 | | 程咬铁 | 17000.00 | +-----------+------------+ rows in set (0.00 sec) #6:关键字LIKE模糊查询 通配符’%’ mysql> SELECT * FROM employee WHERE name LIKE 'jin%'; +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ | 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | | 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ rows in set (0.00 sec) 通配符'_' mysql> SELECT age FROM employee WHERE name LIKE 'ale_'; +-----+ | age | +-----+ | 78 | +-----+ row in set (0.00 sec) 练习: 1. 查看岗位是teacher的员工姓名、年龄 2. 查看岗位是teacher且年龄大于30岁的员工姓名、年龄 3. 查看岗位是teacher且薪资在9000-1000范围内的员工姓名、年龄、薪资 4. 查看岗位描述不为NULL的员工信息 5. 查看岗位是teacher且薪资是10000或9000或30000的员工姓名、年龄、薪资 6. 查看岗位是teacher且薪资不是10000或9000或30000的员工姓名、年龄、薪资 7. 查看岗位是teacher且名字是jin开头的员工姓名、年薪 #对应的sql语句 select name,age from employee where post = 'teacher'; select name,age from employee where post='teacher' and age > 30; select name,age,salary from employee where post='teacher' and salary between 9000 and 10000; select * from employee where post_comment is not null; select name,age,salary from employee where post='teacher' and salary in (10000,9000,30000); select name,age,salary from employee where post='teacher' and salary not in (10000,9000,30000); select name,salary*12 from employee where post='teacher' and name like 'jin%'; where约束
(2) . group by 分组查询
#1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的 #2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等 #3、为何要分组呢? 取每个部门的最高工资 取每个部门的员工数 取男人数和女人数 小窍门:‘每’这个字后面的字段,就是我们分组的依据 #4、大前提: 可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
当执行以下sql语句的时候,是以 post 字段查询了组中的第一条数据,没有任何意义,因为我们现在想查出当前组的多条记录.
mysql> select * from employee group by post; +----+--------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+--------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | | 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | | 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 | | 1 | egon | male | 18 | 2017-03-01 | 驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 | +----+--------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ 4 rows in set (0.00 sec) #由于没有设置ONLY_FULL_GROUP_BY,于是也可以有结果,默认都是组内的第一条记录,但其实这是没有意义的 如果想分组,则必须要设置全局的sql的模式为ONLY_FULL_GROUP_BY mysql> set global sql_mode='ONLY_FULL_GROUP_BY'; Query OK, 0 rows affected (0.00 sec) #查看MySQL 5.7默认的sql_mode如下: mysql> select @@global.sql_mode; +--------------------+ | @@global.sql_mode | +--------------------+ | ONLY_FULL_GROUP_BY | +--------------------+ 1 row in set (0.00 sec) mysql> exit;#设置成功后,一定要退出,然后重新登录方可生效 Bye
继续验证通过 group by 分组之后,只能查询当前字段,如果想看组内信息,需要借助聚合函数.
mysql> select * from emp group by post;# 报错 ERROR 1054 (42S22): Unknown column 'post' in 'group statement' mysql> select post from employee group by post; +-----------------------------------------+ | post | +-----------------------------------------+ | operation | | sale | | teacher | | 驻沙河办事处外交大使 | +-----------------------------------------+ 4 rows in set (0.00 sec)
(3) . 集合函数
max()求最大值 min()求最小值 avg()求平均值 sum() 求和 count() 求总个数 #强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组 # 每个部门有多少个员工 select post,count(id) from employee group by post; # 每个部门的最高薪水 select post,max(salary) from employee group by post; # 每个部门的最低薪水 select post,min(salary) from employee group by post; # 每个部门的平均薪水 select post,avg(salary) from employee group by post; # 每个部门的所有薪水 select post,sum(age) from employee group by post;
1. 查询岗位名以及岗位包含的所有员工名字 2. 查询岗位名以及各岗位内包含的员工个数 3. 查询公司内男员工和女员工的个数 4. 查询岗位名以及各岗位的平均薪资 5. 查询岗位名以及各岗位的最高薪资 6. 查询岗位名以及各岗位的最低薪资 7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
(4) . having 过滤
having 和 where 的区别 : #1 . 执行优先级从高到低 : where > group by > having #2 . where 发生在分组 group by 之前,因而 where 中可以有任意字段,但是绝对不能使用聚合函数. #3 . having 发生在分组 group by 之后,因而 having 中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数.
验证 :
验证: mysql> select * from employee where salary>1000000; +----+------+------+-----+------------+---------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------+------+-----+------------+---------+--------------+------------+--------+-----------+ | 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 | +----+------+------+-----+------------+---------+--------------+------------+--------+-----------+ 1 row in set (0.00 sec) mysql> select * from employee having salary>1000000; ERROR 1463 (42000): Non-grouping field 'salary' is used in HAVING clause # 必须使用group by才能使用group_concat()函数,将所有的name值连接 mysql> select post,group_concat(name) from emp group by post having salary > 10000; ##错误,分组后无法直接取到salary字段 ERROR 1054 (42S22): Unknown column 'post' in 'field list'
#1. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 #2. 查询各岗位平均薪资大于10000的岗位名、平均工资 #3. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资 # 题1: mysql> select post,group_concat(name),count(id) from employee group by post; +-----------------------------------------+-----------------------------------------------------------+-----------+ | post | group_concat(name) | count(id) | +-----------------------------------------+-----------------------------------------------------------+-----------+ | operation | 程咬铁,程咬铜,程咬银,程咬金,张野 | 5 | | sale | 格格,星星,丁丁,丫丫,歪歪 | 5 | | teacher | xiaomage,jinxin,jingliyang,liwenzhou,yuanhao,wupeiqi,alex | 7 | | 老男孩驻沙河办事处外交大使 | egon | 1 | +-----------------------------------------+-----------------------------------------------------------+-----------+ rows in set (0.00 sec) mysql> select post,group_concat(name),count(id) from employee group by post having count(id)<2; +-----------------------------------------+--------------------+-----------+ | post | group_concat(name) | count(id) | +-----------------------------------------+--------------------+-----------+ | 老男孩驻沙河办事处外交大使 | egon | 1 | +-----------------------------------------+--------------------+-----------+ row in set (0.00 sec) #题2: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ rows in set (0.00 sec) #题3: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000; +-----------+--------------+ | post | avg(salary) | +-----------+--------------+ | operation | 16800.026000 | +-----------+--------------+ row in set (0.00 sec)
(5) . order by 查询排序
按单列排序 SELECT * FROM employee ORDER BY age; SELECT * FROM employee ORDER BY age ASC; SELECT * FROM employee ORDER BY age DESC; 按多列排序:先按照age升序排序,如果年纪相同,则按照id降序 SELECT * from employee ORDER BY age ASC, #asc 升序 id DESC; # desc 降序
验证多列排序: SELECT * from employee ORDER BY age ASC,id DESC; mysql> SELECT * from employee ORDER BY age ASC,id DESC; +----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | 18 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 | | 17 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 | | 16 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 | | 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 | | 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 | | 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 | | 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | | 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | | 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 | | 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | | 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 | | 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 | | 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 | | 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | | 8 | xiaomage | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 | | 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 | | 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 | | 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 | +----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ rows in set (0.01 sec) mysql> 验证多列排序
#1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 #2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 #3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列 # 题目1 select * from employee ORDER BY age asc,hire_date desc; # 题目2 mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ rows in set (0.00 sec) # 题目3 mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | teacher | 151842.901429 | | operation | 16800.026000 | +-----------+---------------+ rows in set (0.00 sec) mysql> 小练习答案
(6) . limit 限制查询的记录数
select * from employee order by salary desc limit 3; #起始位置是0 select * from employee order by salary desc limit 0,5; #从第0条开始,显示个数是5个 select * from employee order by salary desc limit 5,5; #从第五条开始,即先查询出第六条,包含这一天向后查5条
# 第1页数据 mysql> select * from employee limit 0,5; +----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 | | 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 | | 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 | | 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 | | 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 | +----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ rows in set (0.00 sec) # 第2页数据 mysql> select * from employee limit 5,5; +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ | 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | | 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | | 8 | xiaomage | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 | | 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | | 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 | +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ rows in set (0.00 sec) # 第3页数据 mysql> select * from employee limit 10,5; +----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ | 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 | | 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 | | 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 | | 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | | 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 | +----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ rows in set (0.00 sec) 小练习答案
多表查询
创建两张表 , 部门表(department) , 员工表(employee).
#创建表 create table department( id int, name varchar(20) ); create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into department values (200,'技术部门'), (201,'人力济源'), (202,''销售), (203,'运营'); insert into employee values(name,sex,age,dep_id ) values ('egon','male',18,200), ('alex','female',48,201), ('wupeiqi','male',38,201), ('yuanhao','female',28,202), ('nvshen','male',18,200), ('xiaomage','female',18,204); #查看表结构和数据 # 查看表结构和数据 mysql> desc department; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.19 sec) mysql> desc employee; +--------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(11) | YES | | NULL | | | dep_id | int(11) | YES | | NULL | | +--------+-----------------------+------+-----+---------+----------------+ 5 rows in set (0.01 sec) mysql> select * from department; +------+--------------+ | id | name | +------+--------------+ | 200 | 技术 | | 201 | 人力资源 | | 202 | 销售 | | 203 | 运营 | +------+--------------+ 4 rows in set (0.02 sec) mysql> select * from employee; +----+----------+--------+------+--------+ | id | name | sex | age | dep_id | +----+----------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | nvshen | male | 18 | 200 | | 6 | xiaomage | female | 18 | 204 | +----+----------+--------+------+--------+ 6 rows in set (0.00 sec)
注意 : 在两张表中,发现department 表中 id=203 部门在employee没有对应的员工,发现 employee 中 id=6 的员工在 department 表中没有对应的关系.
多表连接查询
外链接语法 : ********
select 字段列表 from 表1 inner | left |right join 表2 on 表1.字段 = 表2.字段; # inner join 内链接 # left join 左链接 # right join 又链接
(1) . 交叉链接 : 不适用任何匹配条件(会生成 笛卡尔积--映射)
mysql> select * from employee,department; +----+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 1 | egon | male | 18 | 200 | 201 | 人力资源 | | 1 | egon | male | 18 | 200 | 202 | 销售 | | 1 | egon | male | 18 | 200 | 203 | 运营 | | 2 | alex | female | 48 | 201 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 2 | alex | female | 48 | 201 | 202 | 销售 | | 2 | alex | female | 48 | 201 | 203 | 运营 | | 3 | wupeiqi | male | 38 | 201 | 200 | 技术 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 202 | 销售 | | 3 | wupeiqi | male | 38 | 201 | 203 | 运营 | | 4 | yuanhao | female | 28 | 202 | 200 | 技术 | | 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 4 | yuanhao | female | 28 | 202 | 203 | 运营 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | 5 | nvshen | male | 18 | 200 | 201 | 人力资源 | | 5 | nvshen | male | 18 | 200 | 202 | 销售 | | 5 | nvshen | male | 18 | 200 | 203 | 运营 | | 6 | xiaomage | female | 18 | 204 | 200 | 技术 | | 6 | xiaomage | female | 18 | 204 | 201 | 人力资源 | | 6 | xiaomage | female | 18 | 204 | 202 | 销售 | | 6 | xiaomage | female | 18 | 204 | 203 | 运营 |
(2) . 内链接 : 只链接匹配的行
#找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出匹配的结果. #department 没有 204 这个部门,因而employee 表中关于 204这条的员工信息没有匹配出来 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id; +----+---------+------+--------+--------------+ | id | name | age | sex | name | +----+---------+------+--------+--------------+ | 1 | egon | 18 | male | 技术 | | 2 | alex | 48 | female | 人力资源 | | 3 | wupeiqi | 38 | male | 人力资源 | | 4 | yuanhao | 28 | female | 销售 | | 5 | nvshen | 18 | male | 技术 | +----+---------+------+--------+--------------+ 5 rows in set (0.00 sec) #上述sql等同于 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id; #employee.id,employee.name,employee.age,employee.sex,department.name 相当于 *
(3) . 左链接 : 优先显示左表的全部内容
#以左表为准,即找出所有员工信息,当然包括没有部门的员工 #本质就是:在内连接的基础上增加左边有,右边没有的结果 mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id; +----+----------+--------------+ | id | name | depart_name | +----+----------+--------------+ | 1 | egon | 技术 | | 5 | nvshen | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 6 | xiaomage | NULL | +----+----------+--------------+ 6 rows in set (0.00 sec)
(4) . 右链接 : 优先显示右表的全部记录
#以右表为准,即找出所有部门信息,包括没有员工的部门 #本质就是:在内连接的基础上增加右边有,左边没有的结果 mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id; +------+---------+--------------+ | id | name | depart_name | +------+---------+--------------+ | 1 | egon | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 5 | nvshen | 技术 | | NULL | NULL | 运营 | +------+---------+--------------+ 6 rows in set (0.00 sec)
(5) . 全外链接 : 显示左右两个表的全部记录
#外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果 #注意:mysql不支持全外连接 full JOIN #强调:mysql可以使用此种方式间接实现全外连接 语法:select * from employee left join department on employee.dep_id = department.id union all select * from employee right join department on employee.dep_id = department.id; mysql> select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id ; +------+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | xiaomage | female | 18 | 204 | NULL | NULL | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+----------+--------+------+--------+------+--------------+ 7 rows in set (0.01 sec) #注意 union与union all的区别:union会去掉相同的纪录
总结 :
外链接 : 内链接 : 只链接匹配的行 select * from employee inner join department on employee.dep_id = department.id; 左链接 : 优先显示左表中的记录 select * from employee left join department on employee.dep_id = department.id; 右链接 : 优先显示右表中的内容 select * from employee right join department on employee.dep_id = department.id; 全外链接 : select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id;
符合条件链接查询
示例1 : 以内连接的方式查询 employee 表和department表,并且 employee表中的age字段值必须大于25,即找出年龄大于25岁的员工以及员工所在的部门.
select employee.name,department.name from employee inner join department on employee.dep_di = department.id where arg > 25;
示例2 : 以内链接的方式查询employee和department表,且以arg字段升序的方式显示
#方法一 : select employee.id,employee.name,employee.age,department.name from employee inner join department on employee.dep_di = department.id where age > 25 order by age asc; #方法二 : 简单点 select employee.id,employee.name,employee.age,department.name from employee,department where employee.dep_id = department.id and age > 25 order by age asc;
子查询
#1 . 子查询是将一个查询语句嵌套在另一个查询语句中. #2 . 内层查询语句的查询结果,可以为外层查询语句提供条件. #3 . 子查询中可以包含: in,not in , any , exists , not exists 等关键字. #4 . 还可以包含比较运算符 : = , != ,> , < ......
(1) . 带in关键字的子查询
#查询平均年龄在25岁以上的部门名 select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25); # 查看技术部员工姓名 select name from employee where dep_id in (select id from department where name='技术'); #查看不足1人的部门名 select name from department where id not in (select dep_id from employee group by dep_id); #先查询人数,让人数不属于1
(2) . 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<> #查询大于所有人平均年龄的员工名与年龄 mysql> select name,age from employee where age > (select avg(age) from employee); +---------+------+ | name | age | +---------+------+ | alex | 48 | | wupeiqi | 38 | +---------+------+ #查询大于部门内平均年龄的员工名、年龄 思路: (1)先对员工表(employee)中的人员分组(group by),查询出dep_id以及平均年龄。 (2)将查出的结果作为临时表,再对根据临时表的dep_id和employee的dep_id作为筛选条件将employee表和临时表进行内连接。 (3)最后再将employee员工的年龄是大于平均年龄的员工名字和年龄筛选。 mysql> select t1.name,t1.age from employee as t1 inner join (select dep_id,avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age; +------+------+ | name | age | +------+------+ | alex | 48 |
(3) . 带 exists 关键字的子查询
#EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。而是返回一个真假值。True或False #当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询 #department表中存在dept_id=203,Ture mysql> select * from employee where exists (select id from department where id=200); +----+----------+--------+------+--------+ | id | name | sex | age | dep_id | +----+----------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | nvshen | male | 18 | 200 | | 6 | xiaomage | female | 18 | 204 | +----+----------+--------+------+--------+ #department表中存在dept_id=205,False mysql> select * from employee where exists (select id from department where id=204); Empty set (0.00 sec)
练习 : 查询每个部门最新入职的员工
#创建表 create table employee( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); #查看表结构 mysql> desc employee; +--------------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(3) unsigned | NO | | 28 | | | hire_date | date | NO | | NULL | | | post | varchar(50) | YES | | NULL | | | post_comment | varchar(100) | YES | | NULL | | | salary | double(15,2) | YES | | NULL | | | office | int(11) | YES | | NULL | | | depart_id | int(11) | YES | | NULL | | +--------------+-----------------------+------+-----+---------+----------------+ #插入记录 #三个部门:教学,销售,运营 insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ;
#答案 select * from employee as t1 inner join (select post,max(hire_date) as new_date from employee group by post) as t2 on t1.post=t2.post where t1.hire_date=t2.new_date;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号