协程与IO多路复用
IO多路复用
I/O多路复用 : 通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作.
Python
Python中有一个select模块,其中提供了 : select , poll , epoll ,三个方法,分别调用系统的select , poll , epoll ,从而实现IO多路复用.
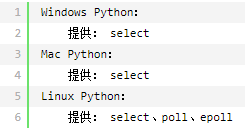

注意:网络操作、文件操作、终端操作等均属于IO操作,对于windows只支持Socket操作,其他系统支持其他IO操作,但是无法检测 普通文件操作 自动上次读取是否已经变化。
单线程实现并发
对于select方法:
句柄列表11, 句柄列表22, 句柄列表33 = select.select(句柄序列1, 句柄序列2, 句柄序列3, 超时时间) 参数: 可接受四个参数(前三个必须) 返回值:三个列表 select方法用来监视文件句柄,如果句柄发生变化,则获取该句柄。 1、当 参数1 序列中的句柄发生可读时(accetp和read),则获取发生变化的句柄并添加到 返回值1 序列中 2、当 参数2 序列中含有句柄时,则将该序列中所有的句柄添加到 返回值2 序列中 3、当 参数3 序列中的句柄发生错误时,则将该发生错误的句柄添加到 返回值3 序列中 4、当 超时时间 未设置,则select会一直阻塞,直到监听的句柄发生变化 当 超时时间 = 1时,那么如果监听的句柄均无任何变化,则select会阻塞 1 秒,之后返回三个空列表,如果监听的句柄有变化,则直接执行。
import socket import select client1 = socket.socket() client1.setblocking(False) # 百度创建连接: 非阻塞(原本要等待回复或者连接,现在是发送之后再阻塞的时间就可以去执行别的任务 try: client1.connect(('www.baidu.com',80)) #执行了,但是报错了 except BlockingIOError as e: pass client2 = socket.socket() client2.setblocking(False) # 搜狗创建连接: 非阻塞 try: client2.connect(('www.sogou.com',80)) except BlockingIOError as e: pass client3 = socket.socket() client3.setblocking(False) # 搜狐创建连接: 非阻塞 try: client3.connect(('www.souhu.com',80)) except BlockingIOError as e: pass socket_list = [client1,client2,client3] conn_list = [client1,client2,client3] while True: """ socket_list:检测是否服务端给我返回数据,可读 conn_list:检测其中的所有socket是否已经和服务端连接成功,可写 rlist :就是有 [client2 , client3 不一定有1,2,3哪一个] wlist:[client1,client2] [] : 是连接不成功的放这里 0.005 : 最多0.005秒检测一次,检测是否连接成功 / 返回数据 """ rlist,wlist,elist = select.select(socket_list,conn_list,[],0.005) # wlist中表示已经连接成功的socket对象 for sk in wlist: if sk == client1: sk.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n') elif sk==client2: sk.sendall(b'GET /web?query=fdf HTTP/1.0\r\nhost:www.sogou.com\r\n\r\n') else: sk.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.souhu.com\r\n\r\n') conn_list.remove(sk) """ 连接成功之后就不用继续监听是否连接成功了,所有剔除 """ for sk in rlist: chunk_list = [] while True: """ 不阻塞,但是如果没有了会报错,都接受之后 """ try: chunk = sk.recv(8096) if not chunk: break chunk_list.append(chunk) except BlockingIOError as e: break body = b''.join(chunk_list) print('------------>',body) sk.close() socket_list.remove(sk) if not socket_list: break


import socket import select class Req(object): def __init__(self,sk,func): self.sock = sk self.func = func def fileno(self): return self.sock.fileno() class Nb(object): def __init__(self): self.conn_list = [] self.socket_list = [] def add(self,url,func): client = socket.socket() client.setblocking(False) # 非阻塞 try: client.connect((url, 80)) except BlockingIOError as e: pass obj = Req(client,func) self.conn_list.append(obj) self.socket_list.append(obj) def run(self): while True: rlist,wlist,elist = select.select(self.socket_list,self.conn_list,[],0.005) # wlist中表示已经连接成功的req对象 for sk in wlist: # 发生变换的req对象 sk.sock.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n') self.conn_list.remove(sk) for sk in rlist: chunk_list = [] while True: try: chunk = sk.sock.recv(8096) if not chunk: break chunk_list.append(chunk) except BlockingIOError as e: break body = b''.join(chunk_list) # print(body.decode('utf-8')) sk.func(body) sk.sock.close() self.socket_list.remove(sk) if not self.socket_list: break def baidu_repsonse(body): print('百度下载结果:',body) def sogou_repsonse(body): print('搜狗下载结果:', body) def souhu_repsonse(body): print('老男孩下载结果:', body) t1 = Nb() t1.add('www.baidu.com',baidu_repsonse) t1.add('www.sogou.com',sogou_repsonse) t1.add('www.souhu.com',oldboyedu_repsonse) t1.run()
基于事件循环实现的异步非阻塞框架 Twisted
异步 : 执行完某个任务后自动调用分配的函数
非阻塞 : 不等待 (给个任务之后不用等待回复)
from lzl import Nb def baidu_repsonse(body): print('百度下载结果:',body) def sogou_repsonse(body): print('搜狗下载结果:', body) def souhu_repsonse(body): print('搜狐下载结果:', body) t1 = Nb() t1.add('www.baidu.com',baidu_repsonse) t1.add('www.sogou.com',sogou_repsonse) t1.add('www.souhu.com',oldboyedu_repsonse) t1.run() #连接网络请求之后,不用去等着回复直接去执行后面相对应的函数
总结 :
1. IO多路复用的作用 : 检测多个socket是否发送变化 (三种模式 select , poll, epoll .Windows系统只支持 select).
2.异步非阻塞:
异步:通知,执行之后自动执行回调函数或自动执行某些操作(通知).
非阻塞 : 不等待 :
比如:创建socket对某个地址进行 connect,获取接收数据recv时默认都会等待(连接成功或接收数据),才执行后续操作.-----如果设置了 setblocking(False),以上两个过程就不在等待,但是会报错-BiockingIOError的错误,只要捕获即可.
3.同步阻塞 :
阻塞: 等待
同步 : 按照顺序逐步执行.
key_list = ['ab','db','sb'] for item in key_list: ret = requests.get('https://www.baidu.com/s?wd=%s' %item) print(ret.text)
协程
概念
协程 : 是单线程下的并发,又称"微线程",是由程序员创造出来的一个不是真实存在的东西.
作用是 : 对一个线程进行切片,使得线程在代码块之间进行来回切换执行任务,而不是原来逐行执行.
注意 :
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) #2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统的线程的切换,用户在单线程内控制协程的切换 :
#优点: #1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 #2. 单线程内就可以实现并发的效果,最大限度地利用cpu #缺点: #1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 #2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
协程的特点 :
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
greenlet 模块
先安装greenlet模块 ; pip3 install greenlet
import greenlet def f1(): print(11) gr2.switch() print(22) gr2.switch() def f2(): print(33) gr1.switch() print(44) # 协程 gr1 gr1 = greenlet.greenlet(f1) # 协程 gr2 gr2 = greenlet.greenlet(f2) gr1.switch() 结果: 11 33 22 44
注意 :单纯的切换有时候还会降低程序的执行速度,greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块。
所以说 当--- 协程 + 遇到IO就切换 ===厉害了!!!
gevent 模块
安装 : pip3 install gevent
from gevent import monkey monkey.patch_all() # 以后代码中遇到IO都会自动执行greenlet的switch进行切换 import requests import gevent def get_page1(url): ret = requests.get(url) print(url,ret.content) def get_page2(url): ret = requests.get(url) print(url,ret.content) def get_page3(url): ret = requests.get(url) print(url,ret.content) gevent.joinall([ gevent.spawn(get_page1, 'https://www.python.org/'), # 协程1 gevent.spawn(get_page2, 'https://www.yahoo.com/'), # 协程2 gevent.spawn(get_page3, 'https://github.com/'), # 协程3 ]) #结果的顺序是不确定的,A,B,C三个请求,当执行A的时候遇到阻塞,那么久在阻塞的这个时间段去执行不阻塞的B或者C,当执行B的时候遇到阻塞就去执行A/C,在网络编程中会有请求时候的阻塞和接收时候的阻塞.
总结 :
1.协程能提高并发吗 ?
答:协程本身是无法提高并发的,但是协程+IO切换可以.
2.单线程提高并发的方法:
--- 协程+IO切换 gevent
--- 基于事件循环的异步非阻塞框架 Twisted
3.进程,线程,协程的区别 : ★★★★★★★★★★★★
--- 进程是资源分配的最小单位,线程是CPU调度的最小单位.
--- 在一个程序中可以有多个进行,一个进程最少有一个线程.
--- 和其他语言相比较,其他语言几乎不用进程的,但是在Python中,它的进程和线程是有差异的,Python有个GIL锁,GIL锁保证一个进程在同一时刻只有一个线程被CPU调到.
--- 对于协程来说,它是有程序员创造出来的不是一个真实存在的东西,它本身是没有意义的,但是当 协程+IO切换放到一起的时候就可以提高单线程并发的性能.

