scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程
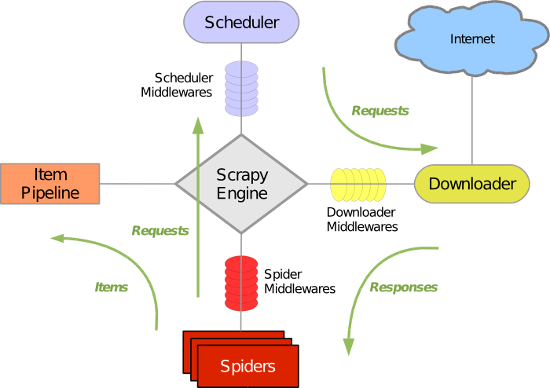
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。


五大核心组件 : spider : 从这里开始 ---> 作用 : 产生一个或者一批url / parse()对数据进行解析 url-->封装成请求对象-->引擎(接收spider提供的请求对象,但是还没有请求到数据) 引擎-->(请求对象)-->调度器(调度请求): 过滤器的类->去重(有可能会出现相同的请求对象)-->队列(数据类型,存的就是请求对象) 然后调度器从队列中调度出来一个请求对象给-->引擎-->给下载器-->请求对象-->互联网进行下载 互联网-->响应对象-->给下载器-->引擎(响应对象)-->给spider中的回调方法,进行解析 解析到的对象封装到item对象中-->引擎-->管道,持久化存储 然后 调度器再次从队列中调出来一个url,在......... 核心问题 : 引擎是用来触发事物的,但是引擎怎么知道在什么时候什么节点去触发那些事物? 解答 : 在工作过程中,所有的数据流都会经过'引擎',也就是说 '引擎'是根据接收到的数据流来判定应该去触发那个事物 比如 : 当 spider 给'引擎'提交了个item,引擎一旦接收了个数据类型是item的时候, 引擎马上就会知道下一步应该实例化管道,在掉管道中process_item方法 所有实例化的操作,事物的触发都是由引擎执行的
二 . post请求发送
- 在之前的代码中,我么你从来没有过手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确进行了请求的发送,这是怎么实现的呢?
- 解答 : 其实是爬虫文件中的爬虫类继承了Spider父类中的start_urls(self)这个方法,该方法就可以对start_urls列表中的url发起请求 :
def start_requests(self): for u in self.start_urls: yield scrapy.Request(url=u,callback=self.parse)
注意 : 该方法默认的是进行get请求的发送,如果想要进行post请求,就要重写该方法 :
def start_requests(self): #请求的url post_url = 'http://fanyi.baidu.com/sug' #post请求的参数,是个字典的形式 data = { 'kw':'dog' } #发送post请求 yield scrapy.FormRequest(url=post_url,formdata=data,callback=self.parse)

