增删改查,$关键字,数据类型
增删改查
首先创建一个数据库:这里和一般的关系型数据库一样,都要建立一个属于自己的数据库空间.
注意 : MongoDB中如果你使用了不存在的对象,那么就等于你在创建这个对象哦
use my # 创建数据库,如果有 my 这个数据库就是使用 db # 显示当前使用的数据库

注意 : 创建完数据库后,如果查看是看不到的,因为如果不向数据库中添加数据,数据库存在在内存中,添加数据后,永久存在在磁盘中
创建一张表 : s1
db.s1 # 创建表 s1 db.s1.drop() # 删除表 db.dropDatabase() # 删除库

集合(表)的增删改查
添加
插入数据有三种方法 : insert , insertOne , insertMany .
官方推荐使用 insertOne , insertMany .
1 . insert : 插入一条或者多条数据.(官方不推荐)
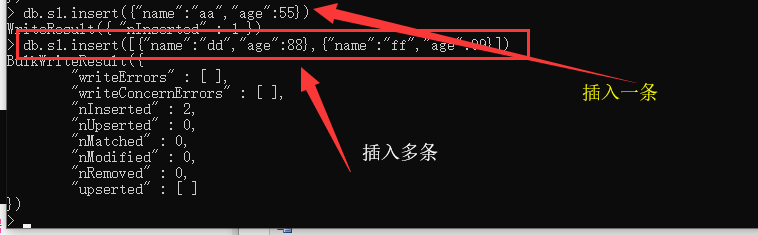
注意 : 插入多条数据的时候是 ([] {},{},{} ]),一个{} 代表一条数据 ,要放在列表中.
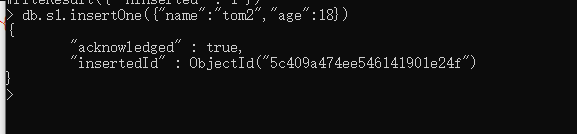
2 . insertOne : 插入一条数据
3 . insertMany : 插入多条数据
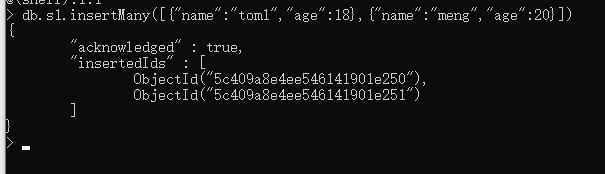
这就是我们向s1中插入的多条数据
[{ "name":"tom1", "age":18 }, { "name":"meng", "age":20 }]
查询
1 . find() : 无条件查询,将表中数据一次性返回多条数据
find({}) : 条件查询,会返回多条数据.

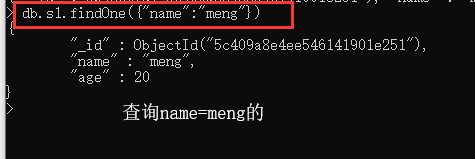
2 . findOne() : 无条件查询.默认返回表中的第一条数据
findOne({}) : 条件查询.默认返回一条,如果有多条则返回靠前的数据.
修改
1 . update : 跟距条件修改,官方不推荐
# 语法 : db.s1.update({"":""},{$set:{"":""}}) update({"name":"DragonFire"},{$set:{"age":21}}): # 把name等于DragonFire中的age改为21 # 这里要注意的是({"条件"},{"关键字":{"修改内容"}}),其中如果条件为空,那么将会修改Collection中所有的数据
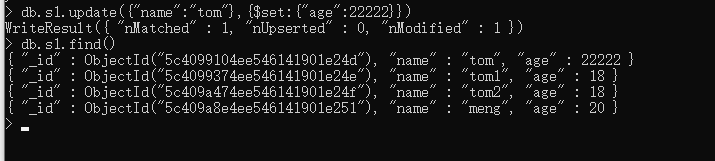
2 . updateOne : 根据条件修改一条数据,如果出现多条则修改最前的一条
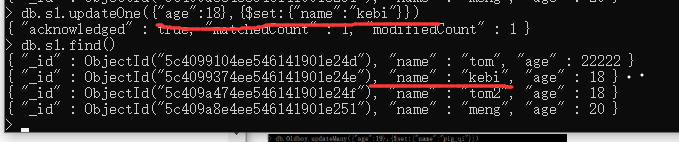
根据 age=18为条件,修改name=kebi,出现了2条,结果只是修改了靠前的一条
3 . updateMany : 根据条件修改所有符合条件的内容.多条修改
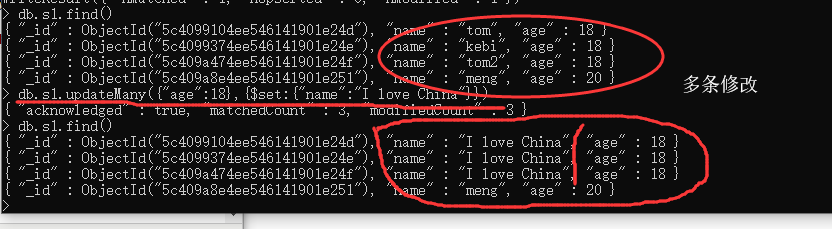
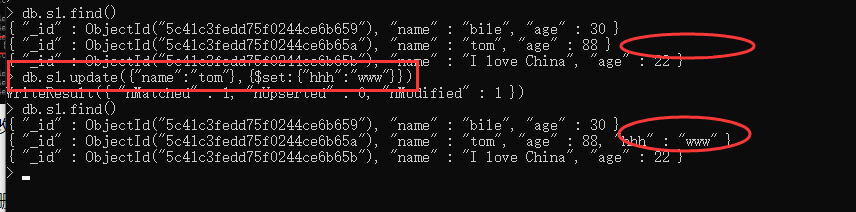
注意 : $set 是update的关键字,表示我要设置 xx属性的值为 xxx,但是由于MongoDB的灵活性,没有我就创建,所以说,如果这条Documents没有 xx 属性,他就会自动创建一个 xx 属性并且赋值为 "xxx" .
删除
1 . remone({}) : 无条件删除数据,删除所有数据,清空.
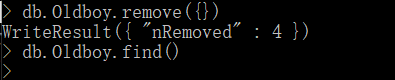
2 . remove({"name":"meng"}) : 删除条件 name=meng 的所有数据

$关键字及修改器
$关键字
1 . 等于 : " : "
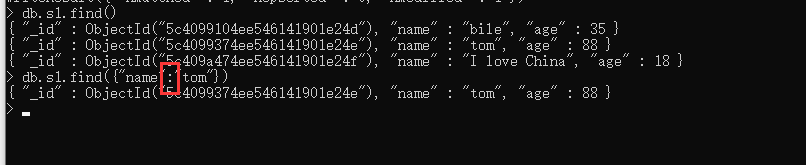
2 . 大于 : "$gt"

3 . 小于 : "$lt"

4 . 大于等于 : "$gte"
5 . 小于等于 : "$lte"
6 . 并列条件
find({"name":"1","age":2})
# 或条件 - 不同字段的或
$or findOne({$or:[{"name":"1"},{"age":2}]})
# 子集 位置可以发生变化
$in findOne({"age":{$in:[1,2,3,4,5]}})
# 完全符合 位置可以发生变化
$all findOne({"age":{$all:[1,2,3,4]}})
修改器
顾名思义,修改器对应的就是 update,在之前我们使用update的时候就用过$set,在update中还有很多的 $关键字,我们把update中的 $关键字 称为 修改器.
1 . $inc :
相当于python中 变量 +/-= 1. 将查询结果加上/减去某个值,然后保存.
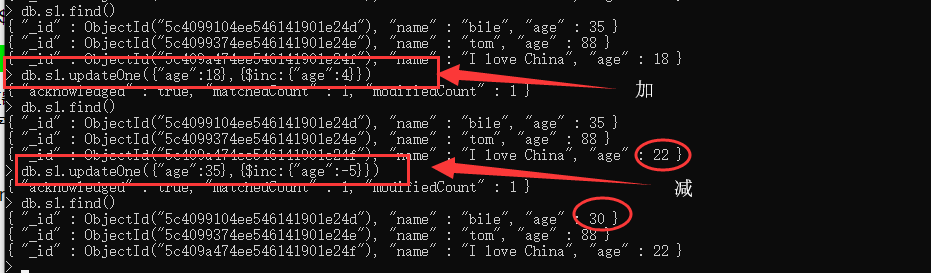
2 . $set : 强制修改,没有就自动增加一条
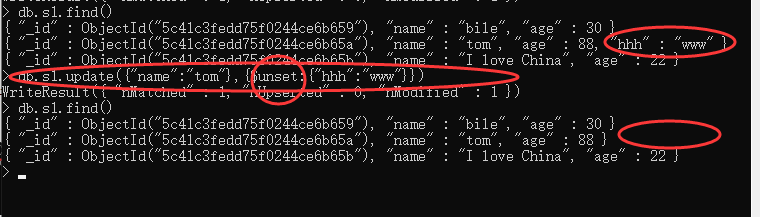
3 . $unset : 用来删除key(field)的
4 . $push :
它是用来对Array (list)数据类型进行 增加 新元素的,相当于我们大Python中 list.append() 方法,

5 . $pull :
有了$push 对Array类型进行增加,就一定有办法对其内部进行删减,$pull 就是指定删除Array中的某一个元素
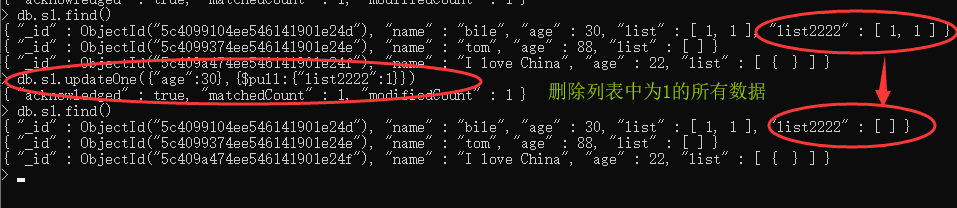
得出了一个结论,只要满足条件,就会将Array中所有满足条件的数据全部清除掉
6 . $pop : 指定删除Array中的第一个 或者 最后一个元素
做个小例子: 删除"score" 等于 100 分 test_list 的最后一个元素

怎么删除第一个呢?

{$pop:{"test_list" : -1}} -1 代表最前面, 1 代表最后边 (这和我们大Python正好相反) 记住哦
$ 代指符
在MongoDB中有一个非常神奇的符号 "$"
"$" 在 update 中 加上关键字 就 变成了 修改器
其实 "$" 字符 独立出现也是有意义的 , 我起名叫做代指符
首先看个例子: 还是这个Collection
![]()
现在把 "score": 100 的 test_list 里面的 2 改为 9

{$set :{"test_list.0" : 9}} 这样就是对应 Array 中的下标进行修改了 "test_list.下标"
问题来了 如果 是 一个很长很长很长的 Array 你要查找其中一个值,把这个值修改一下怎么整呢?

神奇不神奇?
$ 字符 在语句中代表了什么呢? 下标,位置
解释一下: 首先我们查询一下db.Oldboy.findOne({"score":100,"test_list":3}) 返回 给我们满足条件的数据对吧
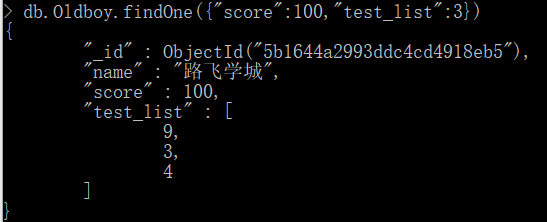
那么 如果 我们 使用 update的话, 满足条件的数据下标位置就会传递到 $ 字符中,在我们更新操作的时候就相当于 对这个位置 的元素进行操作
limit , skip , sort
我们已经学过MongoDB的 find() 查询功能了,在关系型数据库中的选取(limit),排序(sort) MongoDB中同样有,而且使用起来更是简单
首先我们看下添加几条Document进来

现在有四条Document 根据它们, 对 Limit Skip Sort 分别展开学习 最后来一个 大杂烩
1. Limit 选取 : 我要从这些 Document 中取出多少个
做个小例子 : 我只要 2 条 Document

结果是很明显的
但是我还是要解释一下 : limit(2) 就是选取两条Document, 从整个Collection的第一条 Document 开始选取两条
2.Skip 跳过 : 我要跳过多少个Document
做个小例子 : 我要跳过前两个 Document 直接从第三个Document 开始

解释一下 : skip(2) 就是跳过两条Document, 从整个Collection 的第一条 Document 开始跳,往后跳两条
另一个例子 : 跳过第一条 直接从 第二条 开始

3.Limit + Skip : 从这儿到那儿 的 选取
就是刚才的问题,一个小例子 : 我只想要第二条和第三条怎么处理呢

跳过第一条Document 从第二条开始选取两条 Document
别着急,还有另一种写法

两种写法完全得到的结果完全一样但是国际惯例的解释却不同
选取两条Document 但是要 跳过 第一条Document 从 第二条 开始 选取
4. Sort 排序 : 将结果按照关键字排序
做个小例子 : 将find出来的Document 按照 price 进行 升序 | 降序 排列


按照 price 字段进行升序 , 1 为升序 , -1 为降序
5. Limit + Skip + Sort 混搭来一把
一个例子 : 选取第二条第三条 并 按照 price 进行 升序排列

问题出现了, 按道理不应该是 9800 然后 19800 吗?
知识点来喽
重点 : Sort + Skip + Limit 是有执行优先级的 他们的界别分别是 优先 Sort 其次 Skip 最后 Limt
Skip + Limit 的优先级 也是先 Skip 再 Limit
sort > skip > limit
数据类型
首先我们要先了解一下MongoDB中有什么样的数据类型:
Object ID :Documents 自生成的 _id
String: 字符串,必须是utf-8
Boolean:布尔值,true 或者false (这里有坑哦~在我们大Python中 True False 首字母大写)
Integer:整数 (Int32 Int64 你们就知道有个Int就行了,一般我们用Int32)
Double:浮点数 (没有float类型,所有小数都是Double)
Arrays:数组或者列表,多个值存储到一个键 (list哦,大Python中的List哦)
Object:如果你学过Python的话,那么这个概念特别好理解,就是Python中的字典,这个数据类型就是字典
Null:空数据类型 , 一个特殊的概念,None Null
Timestamp:时间戳
Date:存储当前日期或时间unix时间格式 (我们一般不用这个Date类型,时间戳可以秒杀一切时间类型)
1 . Object ID :

"_id" : ObjectId("5b151f8536409809ab2e6b26") #"5b151f85" 代指的是时间戳,这条数据的产生时间 #"364098" 代指某台机器的机器码,存储这条数据时的机器编号 #"09ab" 代指进程ID,多进程存储数据的时候,非常有用的 #"2e6b26" 代指计数器,这里要注意的是,计数器的数字可能会出现重复,不是唯一的 #以上四种标识符拼凑成世界上唯一的ObjectID #只要是支持MongoDB的语言,都会有一个或多个方法,对ObjectID进行转换 #可以得到以上四种信息 #注意:这个类型是不可以被JSON序列化的
这是MongoDB生成的类似关系型DB表主键的唯一key,具体由24个字节组成:
0-8字节是时间戳,
9-14字节的机器标识符,表示MongoDB实例所在机器的不同;
15-18字节的进程id,表示相同机器的不同MongoDB进程。
19-24字节是计数器
2.String :

UTF-8字符串,记住是UTF-8字符串
3.Boolean :
![]()
true or false 这里首字母是小写的
4.Integer :
![]()
整数 (Int32 Int64 你们就知道有个Int就行了,一般我们用Int32)
5.Double :
![]()
浮点数 (MongoDB中没有float类型,所有小数都是Double)
6.Arrays :

{ "_id" : ObjectId("5b163830993ddc4cd4918ead"), "name" : "LuffyCity", "teacher" : [ "DragonFire", "WuSir2B", "Alex AGod" ] }
7 . Object : 相当于python中的 字典
![]()
{ "_id" : ObjectId("5b163915993ddc4cd4918eaf"), "name" : "LuffyCity", "course" : { "name" : "Python", "price" : 19800 } }
8 . Null
![]()
{ "_id" : ObjectId("5b163a0e993ddc4cd4918eb0"), "name" : "LuffyCity", "course" : null }
空数据类型 , 一个特殊的概念,None Null
9 . Timestamp : 时间戳
![]()
{ "_id" : ObjectId("5b163bbf993ddc4cd4918eb3"), "name" : "LuffyCity", "date" : 1528183743111 }
10 . Date :
![]()
{ "_id" : ObjectId("5b163ba1993ddc4cd4918eb2"), "name" : "LuffyCity", "date" : ISODate("2018-06-05T15:28:33.705+08:00") }
存储当前日期或时间格式 (我们一般很少使用这个Date类型,因为时间戳可以秒杀一切时间类型)
练习题
1. 查询岗位名以及各岗位内的员工姓名 2. 查询岗位名以及各岗位内包含的员工个数 3. 查询公司内男员工和女员工的个数 4. 查询岗位名以及各岗位的平均薪资、最高薪资、最低薪资 5. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资 6. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 7. 查询各岗位平均薪资大于10000的岗位名、平均工资 8. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资 9. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 10. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 11. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列,取前1个


1. 查询岗位名以及各岗位内的员工姓名 db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}}) 2. 查询岗位名以及各岗位内包含的员工个数 db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}}) 3. 查询公司内男员工和女员工的个数 db.emp.aggregate({"$group":{"_id":"$sex","count":{"$sum":1}}}) 4. 查询岗位名以及各岗位的平均薪资、最高薪资、最低薪资 db.emp.aggregate({"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"},"max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}}) 5. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资 db.emp.aggregate({"$group":{"_id":"$sex","avg_salary":{"$avg":"$salary"}}}) 6. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 db.emp.aggregate( { "$group":{"_id":"$post","count":{"$sum":1},"names":{"$push":"$name"}} }, {"$match":{"count":{"$lt":2}}}, {"$project":{"_id":0,"names":1,"count":1}} ) 7. 查询各岗位平均薪资大于10000的岗位名、平均工资 db.emp.aggregate( { "$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}} }, {"$match":{"avg_salary":{"$gt":10000}}}, {"$project":{"_id":1,"avg_salary":1}} ) 8. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资 db.emp.aggregate( { "$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}} }, {"$match":{"avg_salary":{"$gt":10000,"$lt":20000}}}, {"$project":{"_id":1,"avg_salary":1}} ) 9. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 db.emp.aggregate( {"$sort":{"age":1,"hire_date":-1}} ) 10. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 db.emp.aggregate( { "$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}} }, {"$match":{"avg_salary":{"$gt":10000}}}, {"$sort":{"avg_salary":1}} ) 11. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列,取前1个 db.emp.aggregate( { "$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}} }, {"$match":{"avg_salary":{"$gt":10000}}}, {"$sort":{"avg_salary":-1}}, {"$limit":1}, {"$project":{"date":new Date,"平均工资":"$avg_salary","_id":0}} ) 参考答案

