48.Mysql中的checkpoint机制
1.checkpoint机制的作用:
- Mysql在进行增删改除的时候,是通过将数据页从磁盘上加载到buffer_pool中(内存),当Mysql对数据页进行了DML操作后,为了提高性能,减少磁盘I/O的次数,这时会设置一个刷脏页的策略:例如master thread checkpoint
- 为了防止内存中修改的脏页消失,Mysql引入了一个redolog日志,redolog日志最大的作用是1是保证binlog能安全落盘,2是能减少mysql数据库故障恢复时间
- 说回正题,关于checkpoint的总结是:按照一定的条件将内存中的脏页刷到磁盘上。
2.LSN
LSN全称:Log Sequence Number :日志序列号,该序列号是一个不断增大的数字,主要存在于数据页、buffer_pool、redolog_buffer、redologfile中
8.0.12版本
Log sequence number 93440256
Log buffer assigned up to 93440256
Log buffer completed up to 93440256
Log written up to 93440256
Log flushed up to 93440256
Added dirty pages up to 93440256
Pages flushed up to 93440256
Last checkpoint at 93440256
18 log i/o's done, 0.25 log i/o's/second
5.7.26版本
LOG
---
Log sequence number 4033522
Log flushed up to 4033522
Pages flushed up to 4033522
Last checkpoint at 4033513
0 pending log flushes, 0 pending chkp writes
10685 log i/o's done, 0.00 log i/o's/second
Log sequence number:表示当前redo log(in buffer)中的LSN
log flushed up to : 表示刷到redo log file on disk中的LSN
pages flushed up to :表示已经刷新到磁盘数据页上的LSN
last checkpoint at :上一次检查点所在的位置LSN
3.我们来说说LSN具体是怎么产生的?
1.首先修改内存中数据页时,在修改后的数据页中记录一个LSN号,暂时称为:data_in_buffer_lsn
2.在修改内存中数据页的同时,redo_log_buffer(也是一块内存区域,在buffer_pool中)中同时也会记录修改的物理变化,发生变化会产生redo log,这时会记录redo log 的一个LSN,注意这个LSN是在内存中,暂时称为:redo_log_in_buffer_lsn
3.当日志写了部分后会触发一个日志落盘策略,该策略是由参数:innodb_flush_log_at_trx_commit控制,该参数在前面的内容有介绍,当将redo_log_buffer中redo log日志刷到磁盘上后,此时在redo log日志也会记录一个LSN(该LSN此时在磁盘上),这个操作也是我们经常说的WAL机制,就是日志优先写机制,该机制是用来防止mysql在未经进行刷脏页时出现宕机,可以用redolog file 来进行恢复。暂时称为:redo_log_on_disk_lsn;
4.我们在内存中修改的数据页不可能一直在内存中,这时我们的猪脚出现(checkpoint机制),它就表示在一定的条件下将脏页(数据脏页和日志脏页)刷到磁盘上,当脏页刷到磁盘后,所以会在本次checkpoint刷页结束后,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
5.要记录checkpoint所在位置很快,只需要设置一个标志即可,但是刷数据页并不一定很快,比如一次性刷的数据页非常多,也就是说要刷入的数据页需要一定的时间来完成,中途刷入的每个数据页都会记录当前页所在的LSN,暂时称为data_page_on_disk_lsn
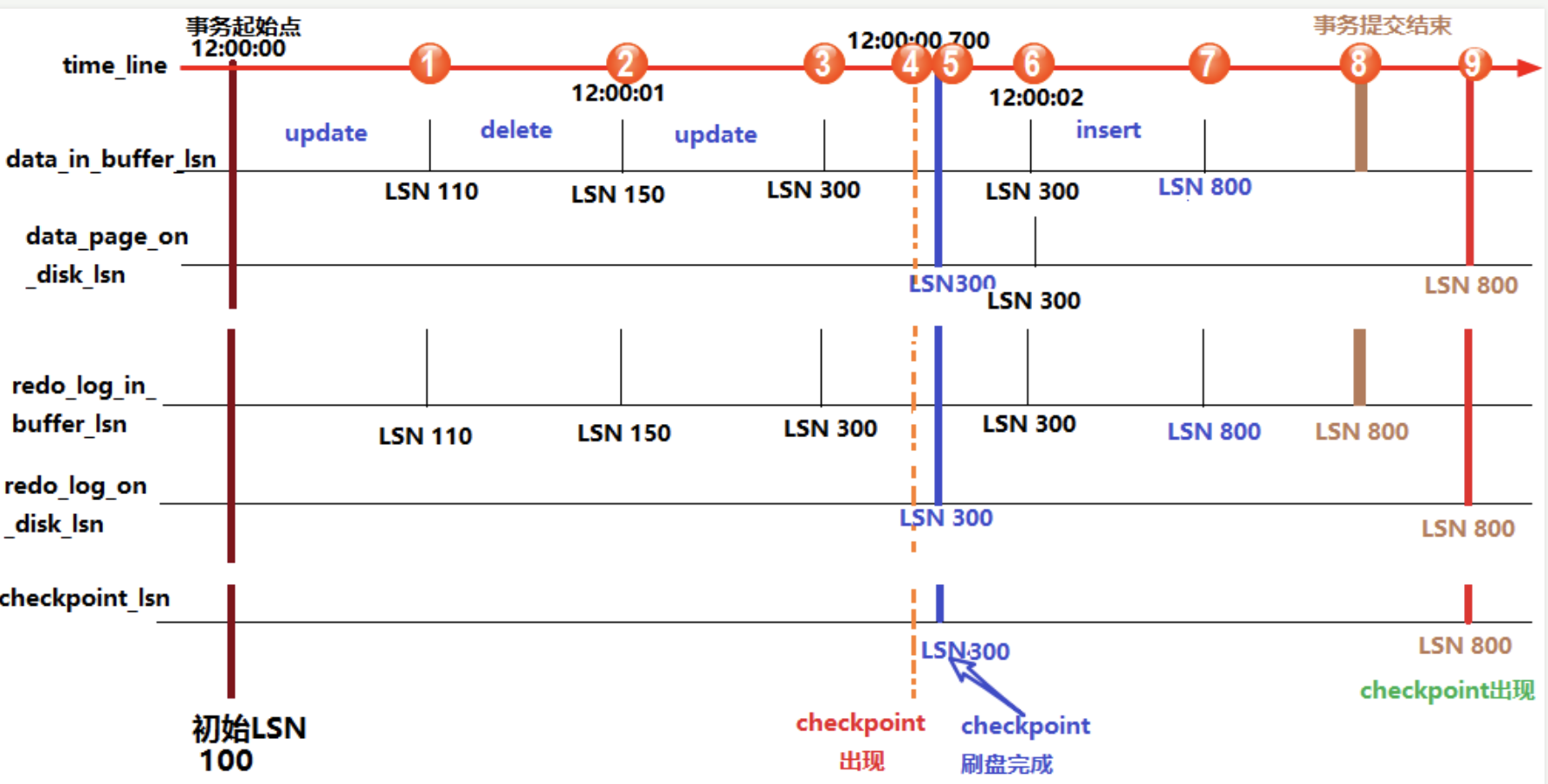
上边表示假如在12:00:00刻将所有的脏页(数据页脏页和日志脏页)刷到磁盘后,这时查看LSN的值是一致的,假如此时开启了一个事务,并执行了update操作,此时发现data_in_buffer_lsn和redo_log_in_buffer_lsn增大,此时用show engine innodb status命令可以发现有如下关系:
log sequence number >log flushed up to LSN=Pages flushed up to LSN =Last checkpoint at LSN
之后再执行一个deleter语句,可以发现data_in_buffer_lsn和redo_log_in_buffer_lsn又增大了,等到12:00:01时,触发redolog的一个刷盘规则(innodb_flush_at_timeout控制的默认日志刷盘频率为1s)
这时再用show engine innodb status命令可以发现有如下关系:
log sequence number LSN =log flushed up to LSN > pages flush up to LSN = last checkpoint at LSN
之后再执行一个update操作,此时可以发现data_in_buffer_lsn和redo_log_in_buffer_lsn继续增大,此时为:LSN=300,假设此时突然出现checkpoint检查点,即图中④的位置,checkepoint检查点会触发内存中的脏页和relog log日志进行刷盘,但是由于刷盘需要一定的时间,所以数据页刷盘还未完成时,检查点的LSN还是上一次检查点的LSN,但此时磁盘上数据页和日志页的LSN已经增长了,即:
log sequence number LSN >log flushed up to LSN 和 pages flush up to LSN > last checkpoint at LSN
这里log flushed up to 和pages flush up to 的大小无法确定,因为日志刷盘可能快于数据刷盘,也可能等于,还可能是慢于,但是checkpoint机制有保护数据刷盘速度是慢于日志刷盘的:当数据刷盘速度超过日志刷盘时,将会暂时停止数据刷盘,等待日志刷盘进度超过数据刷盘。
等到数据页和日志页刷盘完毕,即到了位置⑤的时候,所有的LSN都等于300。
随着时间的推移到了12:00:02,即图中位置⑥,又触发了日志刷盘的规则,但此时buffer中的日志LSN和磁盘中的日志LSN是一致的,所以不执行日志刷盘,所以此时用命令show engine innodb status命令查看发现他们的LSN都相等。
随后又执行了一个insert 语句,假设buffer中的LSN增长到了800,即图中位置⑦。此时各种LSN的大小和位置①时一样。随后执行了提交动作,即位置⑧。默认情况下,提交动作会触发日志刷盘,但不会触发数据刷盘,所以show engine innodb status发现:
log sequence number = log flushed up to > pages flushed up to = last checkpoint at
最后随着时间的推移,检查点再次出现,即图中位置⑨。但是这次检查点不会触发日志刷盘,因为日志的LSN在检查点出现之前已经同步了。假设这次数据刷盘速度极快,快到一瞬间内完成而无法捕捉到状态的变化,这时用show engine innodb status查看发现:它们各个LSN值都相等了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号