

Java集合篇
概述
本文阐述内容以JDK1.8为基准
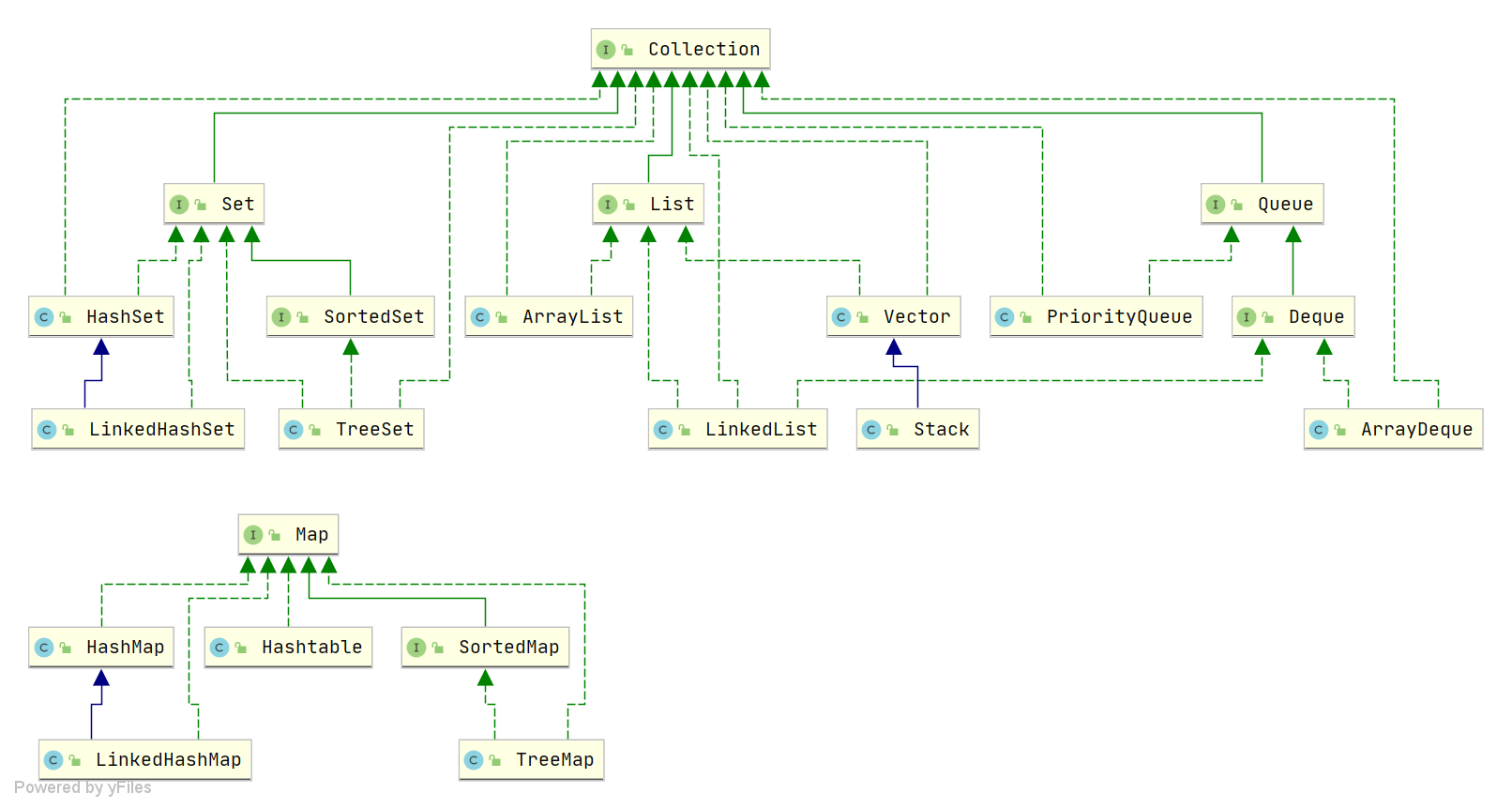
Java包含四类基本集合:Map、Set、List、Queue,其中Set、List、Queue基于Collection接口实现,Map类集合基于Map接口。
- List:提供链式和数组式结构,元素之间保证有序性,可重复
- Set: 元素之间不可重复,底层基于Map的key的唯一性来实现
- Queue: 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。
- Map: 存储key-value结构的元素,支持快速检索,key唯一不可重复
集合间依赖拓扑图如下:
List
ArrayList-非线程安全-有序
提供数组类型的List,底层通过开辟一片连续的空间存储元素,可以通过元素存储的下标快速访问,非线程安全。
- 类图结构
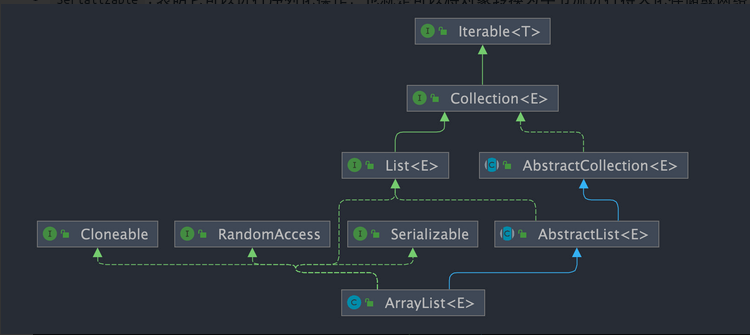
- List: 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。
- RandomAccess: 支持可随机快速访问,即通过下标可以直接访问元素。
- CloneableL:支持实例化对象的复制,可以进行深拷贝或浅拷贝。
- Serializable:表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
- 时间复杂度
访问:O(1),支持随机访问
插入\删除:由于数据是顺序存储,当在数组中间某个下标插入时,插入点后面的元素往后移动,在指定位置插入\删除时为O(n),在尾部插入\删除时不需要移动元素,复杂度为O(1) - 扩容机制
- 初始化时默认创建一个空数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
- add操作
a. 初次添加时默认初始化长度为10的空间private static int calculateCapacity(Object[] var0, int var1) { return var0 == DEFAULTCAPACITY_EMPTY_ELEMENTDATA ? Math.max(10, var1) : var1; }private void ensureExplicitCapacity(int var1) { ++this.modCount; if (var1 - this.elementData.length > 0) { // 当前元素下标大于数组空间长度时触发扩容 this.grow(var1); } }private void grow(int var1) { int var2 = this.elementData.length; int var3 = var2 + (var2 >> 1); if (var3 - var1 < 0) { var3 = var1; } if (var3 - 2147483639 > 0) { //判断数组是否溢出,没溢出重新指定最大长度为Integer.MAX_VALUE var3 = hugeCapacity(var1); } // 按照新数组长度申请内存,并拷贝原数组中的元素 this.elementData = Arrays.copyOf(this.elementData, var3); }
- 避免扩容
- 初始化时设置合适的长度
- 添加完元素后,若预感需要更大的空间,可调用ensureCapacity(int var1)方法将数组直接扩容到指定大小的1.5,减少add后的扩容次数
Vector-线程安全-有序
Vector的实现逻辑与ArrayList类似,不同于Vector中所有改变数组的操作都加上了同步关键字synchronized,属于线程安全的数组。
- 时间复杂度
访问:O(1),支持随机访问
插入\删除:由于数据是顺序存储,当在数组中间某个下标插入时,插入点后面的元素往后移动,在指定位置插入\删除时为O(n),在尾部插入\删除时不需要移动元素,复杂度为O(1) - 扩容机制
除了初始化时会默认申请长度为10的数组控件,其它过程与ArrayList一致。
LinkedList-非线程安全-有序
双向链表结构,结构自身提供了size、first和三个属性。非线程安全
size:链表元素个数
first:链表头部节点
last:链表尾部节点
- 时间复杂度
访问:
头部、尾部节点访问为O(1),其它节点访问为O(n)
插入\删除:
链表特性插入\删除操作本身并不会导致其它元素移位,但是需要先查找到元素才能做删除\插入操作,因此时间复杂度与访问元素一致。
CopyOnWriteArrayList-线程安全-有序
数组类型的List,由于Vector对大量的方法都添加了同步关键字synchronized,所以在实际高并发场景因为锁的粒度太大,容易引起阻塞,降低处理效率。CopyOnWriteArrayList通过给改变数组结构的方法添加可重入锁保证数据安全,同时在相关加锁操作中先copy数组内容,让后操作拷贝副本,这样保证了原数组内容不变,在读取时不会出现脏数据。线程安全
- add操作
先加锁,然后拷贝副本,再操作副本元素
public boolean add(E var1) {
ReentrantLock var2 = this.lock;
var2.lock();
boolean var6;
try {
Object[] var3 = this.getArray();
int var4 = var3.length;
Object[] var5 = Arrays.copyOf(var3, var4 + 1);
var5[var4] = var1;
this.setArray(var5);
var6 = true;
} finally {
var2.unlock();
}
return var6;
}
- 时间复杂度
访问:
因为支持随机访问,所以时间复杂读为O(1)
删除/插入:
由于每次操作需要执行copy,因此时间复杂度为O(n)
Map
HashMap-非线程安全-无序
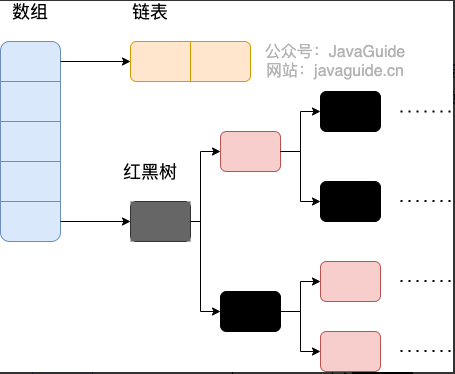
用于存储key-value数据结构,HashMap的底层结构为通过key散列的链表(链表数组),出现hash冲突的元素按顺序插入在映射的链表上;由于当数据量大且分布不均时,容易出现部分链表数据过长,降低HashMap的查询效率,因此在1.8中,对于较长(默认最大长度7)的链表分裂成了红黑树结构,通过红黑树的自平衡特性,提高了HashMap的检索效率。非线程安全
HashMap结构可以存储空的key,null的hash散列值为0
- 结构属性查看
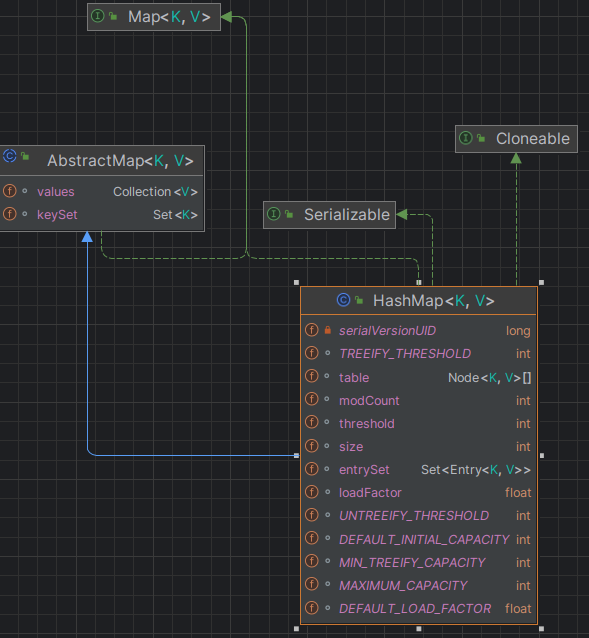
- loadFactor-负载因子:
loadFactor负责key的散列稀疏度,同时也确定了链表数组的数组扩容频次。loadFactor越小,key的散列密集度越低,出现hash冲突的几率小,但是需要频繁扩容开辟新的链表;loadFactor越大,key的散列密集度越高,出现hash冲突的几率越大,导致数据集中,影响查询效率。loadFactor的取值范围为(0,1),默认0.75 - size:键值对数量
- table:链表数组
- entrySet: key元素集合
- threshold-扩容阈值:
threshold = capacity * loadFactor,capacity指的是HashMap存储键值对的容量,默认为16;当键值对数量size超过threshold时,HashMap为了避免数量过多导致链表过长,影响检索效率,会将容量扩容到原来的两倍。
- loadFactor-负载因子:
- put方法
处理流程:
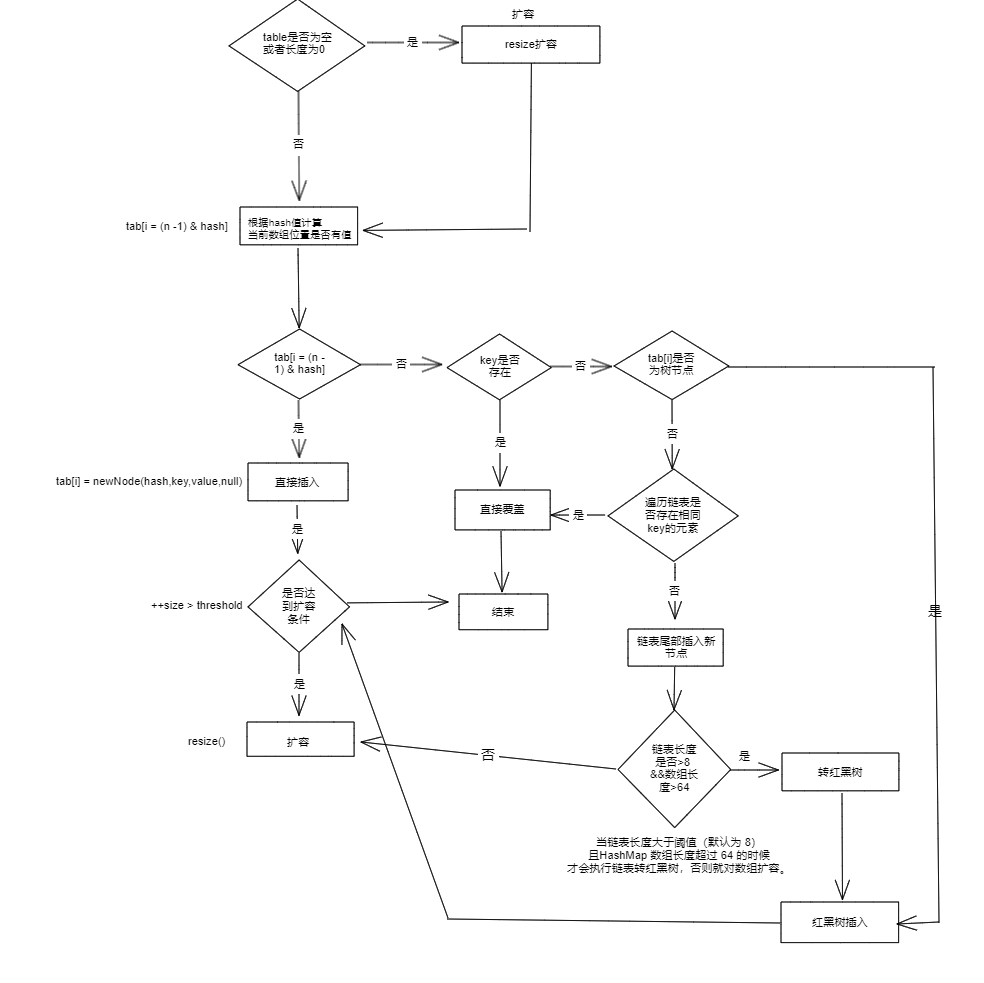
- 如果定位到的数组位置没有元素就直接插入。
- 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
- 对于链表结构添加元素成功后,当链表长度>=默认值7时会转换成红黑树
源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
Node<K,V> e; K k;
//快速判断第一个节点table[i]的key是否与插入的key一样,若相同就直接使用插入的值p替换掉旧的值e。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断插入的是否是红黑树节点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 不是红黑树节点则说明为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
- resize方法
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。resize 方法实际上是将 table 初始化和 table 扩容 进行了整合,底层的行为都是给 table 赋值一个新的数组。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
// 创建对象时初始化容量大小放在threshold中,此时只需要将其作为新的数组容量
newCap = oldThr;
else {
// signifies using defaults 无参构造函数创建的对象在这里计算容量和阈值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// 创建时指定了初始化容量或者负载因子,在这里进行阈值初始化,
// 或者扩容前的旧容量小于16,在这里计算新的resize上限
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 只有一个节点,直接计算元素新的位置即可
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 将红黑树拆分成2棵子树,如果子树节点数小于等于 UNTREEIFY_THRESHOLD(默认为 6),则将子树转换为链表。
// 如果子树节点数大于 UNTREEIFY_THRESHOLD,则保持子树的树结构。
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
- get方法
- 根据key计算散列值
- 判断散列值对应的桶是否为空,为空返回;同时判断桶里的第一个节点的key是否匹配,匹配返回
- 判断第一个节点类型,若为红黑树则迭代查询红黑树,否则遍历链表
# var1为计算的散列值
final Node<K, V> getNode(int var1, Object var2) {
Node[] var3;
Node var4;
int var6;
if ((var3 = this.table) != null && (var6 = var3.length) > 0 && (var4 = var3[var6 - 1 & var1]) != null) {
Object var7;
# 判断散列值对应的桶是否为空,为空返回;同时判断桶里的第一个节点的key是否匹配,匹配返回
if (var4.hash == var1 && ((var7 = var4.key) == var2 || var2 != null && var2.equals(var7))) {
return var4;
}
Node var5;
if ((var5 = var4.next) != null) {
# 判断第一个节点类型,若为红黑树则迭代查询红黑树,否则遍历链表
if (var4 instanceof TreeNode) {
return ((TreeNode)var4).getTreeNode(var1, var2);
}
do {
if (var5.hash == var1 && ((var7 = var5.key) == var2 || var2 != null && var2.equals(var7))) {
return var5;
}
} while((var5 = var5.next) != null);
}
}
return null;
}
LinkedHashMap-非线程安全-基本有序(快访问链表访问时会打乱插入顺序)
LinkedHashMap是对HashMap的继承,节点存储的底层结构由HashMap处理,因此数据结构仍然是具有红黑树的链表数组;LinkedHashMap基于链表数组的基础上单独为所有节点维护了一个双向链表,用于遍历Map时可以通过双向链表快速遍历。
双向链表的维护
- 插入
LinkedHashMap重写了newNode,当新增完元素时会按照顺序向双向链表尾部插入新元素 - 按key指定查找
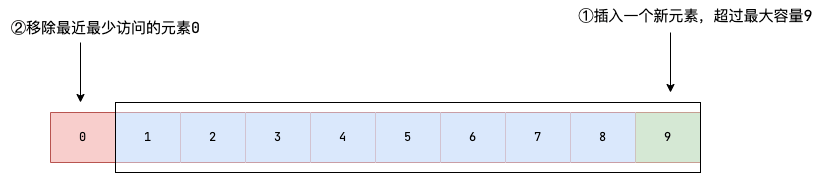
LinkedHashMap重写了get(key),当在HashMap中查找到了节点时,会按照LRU算法(最近最少使用),将找到的节点移动到访问链表尾部,这样链表头部就是最近最少使用的节点。
结构图
LinkedHashMap整体数据结构
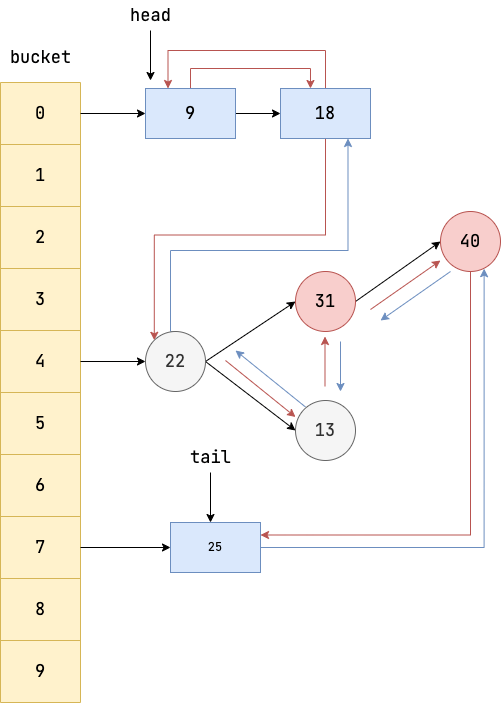
LRU结构模拟
源码
重写afterNodeInsertion,当HashMap执行put完成后调用,判断快速访问链表容量是否不够,是则移除链表头部的元素
void afterNodeInsertion(boolean var1) {
Entry var2;
// 判断链表容量
if (var1 && (var2 = this.head) != null && this.removeEldestEntry(var2)) {
Object var3 = var2.key;
// 移除头部元素
this.removeNode(hash(var3), var3, (Object)null, false, true);
}
}
重写get方法,获取元素后进行LRU操作
public V get(Object var1) {
HashMap.Node var2;
if ((var2 = this.getNode(hash(var1), var1)) == null) {
return null;
} else {
if (this.accessOrder) {
// 开启快速访问时执行LRU
this.afterNodeAccess(var2);
}
return var2.value;
}
}
重写forEach,遍历Map时直接遍历快速访问链表
public void forEach(BiConsumer<? super K, ? super V> var1) {
if (var1 == null) {
throw new NullPointerException();
} else {
int var2 = this.modCount;
// 从链表头部开始遍历快速访问链表
for(Entry var3 = this.head; var3 != null; var3 = var3.after) {
var1.accept(var3.key, var3.value);
}
if (this.modCount != var2) {
throw new ConcurrentModificationException();
}
}
}
Hashtable-线程安全-无序
采用了传统的链表数组方式存储数据,但是没有数据扩容操作,对大部分的操作添加了同步关键字synchronized保证数据的安全性,因此对于大量元素的情况下虽然保证了数据安全,但是锁的颗粒度太大容易造成阻塞,同时无法保证数据散列的密集度,因此也无法保证查询效率。
ConcurrentHashMap-线程安全-无序
数据存储结构与HashMap一致,采用了链表数组的结构,对于较长(默认最大长度8)的链表支持转换会红黑树;区别在于ConcurrentHashMap中的put方法中使用了CAS和synchronized同步快保证了数据安全。
- put源码
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化,初始化过程采用CAS确保线程安全。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容,扩容过程中会插入新的元素,并使用CAS保障线程安全。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要执行树化方法,在 treeifyBin 中会首先判断当前数组长度 ≥64 时才会将链表转换为红黑树。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目标位置元素
Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 数组桶为空,初始化数组桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加锁加入节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// 说明是链表
if (fh >= 0) {
binCount = 1;
// 循环加入新的或者覆盖节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
TreeMap-非线程安全-有序
TreeMap区别与HashMap,采用红黑树的结构存储所有数据集,因此TreeMap中按照key的大小进行有序存储。
Set
Set集合用于保障数据为唯一性。所有的Set集合底层都是基于Map的key来保证唯一性的,即添加一个Set数据key时,实际存储的是<key, new Object()>元素
HashSet-非线程安全-无序
基于HashMap实现数据的存储。基于HashMap可以存储null的key的特性,HashSet也可以存储空。
LinkedHashSet-非线程安全-基本有序
基于LinkeHashMap存储数据,利用LinkeHashMap的特性实现了按插入顺序有序存储。
LinkedHashSet在实例化时利用了HashSet的构造方法
HashSet(int var1, float var2, boolean var3) {
this.map = new LinkedHashMap(var1, var2);
}
此构造方法中生成的是LinkedHashMap实例对象
TreeSet-非线程安全-有序
TreeSet使用了TreeMap存储数据,因此也利用的红黑树的结构,保证了按照key值大小排序。
Queue
区别于其它数据接口,队列支持双端操作,可以实现先入先出或先入后出(栈的实现)的操作。
阻塞队列
ArrayBlockingQueue
双端循环阻塞队列,常用于线程池的使用,特点是队列为空时take操作被阻塞,队列已满时put操作阻塞;ArrayBlockingQueue中任务存储的数据结构是数组。
- 结构图谱
- 提供的基本操作
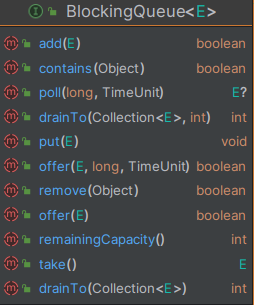
- 阻塞等待操作:
- put: 生产者生产任务,当队列已满,则阻塞
- take: 消费者消费任务,队列已空阻塞
- 阻塞超时等待操作:
- offer(E,long,TimeUnit):生产者生产任务,当队列已满,则阻塞,超过时间后返回false
- poll(E,long,TimeUnit):消费者消费任务,队列已空阻塞,超过时间后返回null
- 非阻塞操作:
- add: 向队列添加任务,添加失败返回异常
- offer:向队列添加任务,添加失败返回false
- poll:向队列获取任务,队列为空返回null
- peek: 向队列中获取任务,但是不会删除任务
- 阻塞等待操作:
- 核心属性
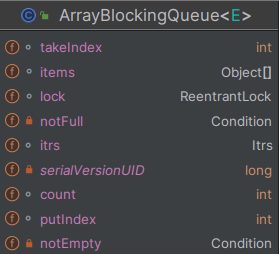
- takeIndex: 指向下一个被消费的元素位置,当takeIndex等于数组长度时,takeIndex会被重置为0,用于实现循环队列
- putIndex: 指向下一个被生产的元素位置,当putIndex等于数组长度时,putIndex会被重置为0,用于实现循环队列
- lock:可重入锁,约束各消费者生产者并发操作队列数组,保证线程安全
- notFull:临界资源监听器Condition,用于阻塞生产者,当队列已满,会执行notFull.await()阻塞生产者,等待队列被消费后的notFull.signal()唤醒
- notEmpty: 临界资源监听器Condition,用于阻塞消费者,当队列为空,会至执行notEmpty.await()阻塞消费者,等待队列被生产后的notEmpty.signal()唤醒
- count: 统计队列中任务的数量
- 阻塞队列操作过程
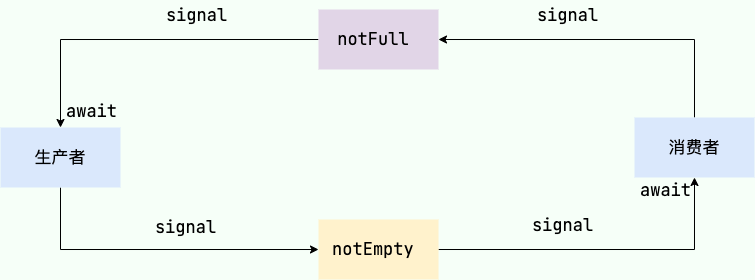
生产者生产任务时,若队列已满,则通过notFull.await()进行阻塞,等待消费者消费,若成功生产,则执行notEmpty.signal()唤醒阻塞的消费者;
消费者消费任务时,若队列已空,则通过notEmpty.await()进行阻塞,等待生产者生产,若成功消费,则执行notFull.signal()唤醒阻塞的生产者;
LinkedBlockingQueue
链式阻塞队列,相较于ArrayBlockingQueue通过数组存储任务空间有限,链式存储的空间无限,切结构更简单,不需要支持循环消费任务;其它实现过程与ArrayBlockingQueue一致。LinkedBlockingQueue是线程池中默认使用的阻塞队列。
非阻塞队列
PriorityQueue
优先级队列,存储数据的结构为数组。当新增或获取任务时,会使用队列比较器(没提供比较器使用插入到数组中的下标进行比较)进行比较,比较算法使用完全二叉树,最终得到小丁堆的拓扑结构,并按照最新的拓扑结构重排数组中元素的顺序,这样得到的结果是对顶元素存储在数组第一个;获取任务获取数组头部任务,保证了每次获取的任务都是优先级最高的任务。
- 结构图
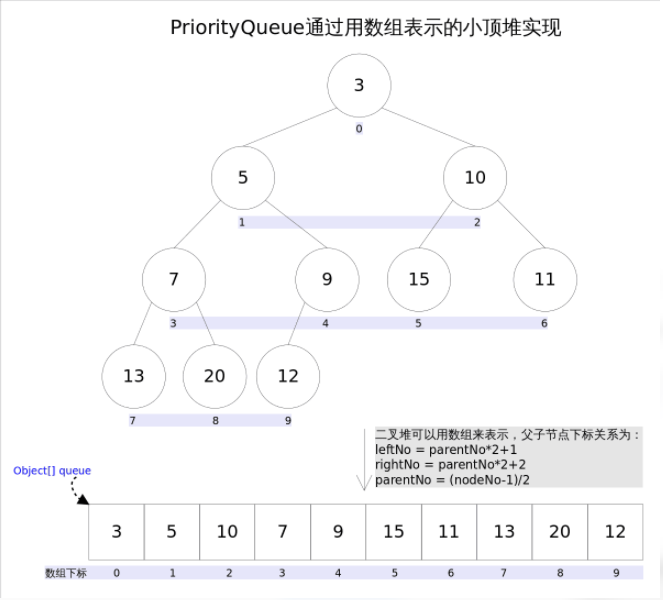
- 源码
- add/offer操做,向队列中添加任务
- 数组越界时进行扩容,并拷贝旧数组元素
- 数组为空时直接插入元素
- 数组不为空则通过比较器,重排数组顺序,并将元素插入到排序位置
// 提交任务 public boolean offer(E var1) { if (var1 == null) { throw new NullPointerException(); } else { ++this.modCount; int var2 = this.size; // 数组越界时进行扩容,并拷贝旧数组元素 if (var2 >= this.queue.length) { this.grow(var2 + 1); } this.size = var2 + 1; if (var2 == 0) { // 数组为空时直接插入元素 this.queue[0] = var1; } else { // 数组不为空则通过比较器,重排数组顺序,并将元素插入到排序位置 this.siftUp(var2, var1); } return true; } } // 重新排序、插入元素 private void siftUpUsingComparator(int var1, E var2) { while(true) { if (var1 > 0) { int var3 = var1 - 1 >>> 1; Object var4 = this.queue[var3]; if (this.comparator.compare(var2, var4) < 0) { this.queue[var1] = var4; var1 = var3; continue; } } this.queue[var1] = var2; return; } } - poll消费任务
- 获取数据头部任务
- 数组重新排序
public E poll() { if (this.size == 0) { return null; } else { int var1 = --this.size; ++this.modCount; Object var2 = this.queue[0]; Object var3 = this.queue[var1]; this.queue[var1] = null; if (var1 != 0) { this.siftDown(0, var3); } return var2; } }
- add/offer操做,向队列中添加任务
DelayQueue
延迟队列,底层是基于PriorityQueue优先队列实现;生产者生产任务需要基于Delayed接口的实现,实现了Delayed接口的任务需要提供延时时间和比较器Comparable的实现,PriorityQueue队列根据Comparable的实现对队列数据进行排序,保证延迟时间最小的元素在数组头部。
- 核心成员
//可重入锁,实现线程安全的关键
private final transient ReentrantLock lock = new ReentrantLock();
//延迟队列底层存储数据的集合,确保元素按照到期时间升序排列
private final PriorityQueue<E> q = new PriorityQueue<E>();
//指向准备执行优先级最高的线程
private Thread leader = null;
//实现多线程之间等待唤醒的交互
private final Condition available = lock.newCondition();
* lock:保证高并发下的线程安全
* q:优先级队列,延时队列的最终载体
* leader: 最小延时时间的任务匹配到的线程,但超过延时时间后,该线程最先执行,并唤醒其它等待获取任务的线程
* available:用于阻塞或唤醒获取队列任务的线程
- 任务的基本实现
基类接口Delayed,DelayQueue定义的任务泛型必须是Delayed的子类
// 集成了Comparable比较器,任务需要实现比较器方法,提供给优先级队列做数组顺序重组时的比较依据
// 需要实现getDelay方法,提供延时时间
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit var1);
}
- add操作
- 使用优先级队列添加任务
- 任务添加成功后,判断新添加的任务是否为需要被最先消费的任务,如果是,则唤醒获取任务的阻塞线程
public boolean offer(E var1) { ReentrantLock var2 = this.lock; var2.lock(); boolean var3; try { // 使用优先队列添加任务 this.q.offer(var1); if (this.q.peek() == var1) { this.leader = null; // 若新添加的任务为需要被最先消费的任务,则唤醒等待消费的线程 this.available.signal(); } var3 = true; } finally { var2.unlock(); } return var3; } - take 获取任务
- 获取重入锁,成功后开始循环获取队列任务
- 队列任务不存在,则进行阻塞等待唤醒
- 队列任务存在,则判断任务是否已经超过延时时间,若已超过,则从队列中拉取任务进行返回
- 任务已到达延时消费时间,则判断是否已经有线程在等待消费任务,若存在,则当前线程阻塞,等待唤醒消费
- 若当前不存在线程在等待消费任务,则按照最近需要被消费的任务剩余延时时间阻塞当前线程,待超过延时时间后自动唤醒消费,阻塞过程中并指定当前线程为最先等待消费的线程
- 获取任务成功后,唤醒其它等待消费的线程
public E take() throws InterruptedException { ReentrantLock var1 = this.lock; // 获取重入锁,成功后开始循环获取队列任务 var1.lockInterruptibly(); try { while(true) { while(true) { Delayed var2 = (Delayed)this.q.peek(); if (var2 != null) { // 队列任务存在,则判断任务是否已经超过延时时间,若已超过,则从队列中拉取任务进行返回 long var3 = var2.getDelay(TimeUnit.NANOSECONDS); if (var3 <= 0L) { Delayed var14 = (Delayed)this.q.poll(); return var14; } var2 = null; if (this.leader != null) { // 任务已到达延时消费时间,则判断是否已经有线程在等待消费任务,若存在,则当前线程阻塞,等待唤醒消费 this.available.await(); } else { // 若当前不存在线程在等待消费任务,则按照最近需要被消费的任务剩余延时时间阻塞当前线程,待超过延时时间后自动唤醒消费,阻塞过程中并指定当前线程为最先等待消费的线程 Thread var5 = Thread.currentThread(); this.leader = var5; try { this.available.awaitNanos(var3); } finally { if (this.leader == var5) { this.leader = null; } } } } else { // 队列任务不存在,则进行阻塞等待唤醒 this.available.await(); } } } } finally { if (this.leader == null && this.q.peek() != null) { // 获取任务成功后,唤醒其它等待消费的线程 this.available.signal(); } var1.unlock(); } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)