
Redis部署-集群
基本原理
Redis集群是一个提供在多个Redis节点间共享数据的程序集,可以支持多个Master。
作用
- 支持多个Master,每个Master可以挂载多个Slave,可以支持读写分离、数据的高可用、海量数据的存储
- 支持故障迁移机制,不需要单独的Sentinel节点
- 客户端与Redis的节点连接时,不需要要连接所有节点,连接其中任一节点即可
- 槽位slot负责分配到各个物理服务器,实现数据的分片
实现原理
哈希取余分区
对key做hash计算,根据计算结果对集群节点数量取余得到key分布的节点位置。
优点
实现简单好管理,起到了负载均衡的作用
缺点
由于取余的分母是节点数,会发生变化,扩容缩容时影响数据范围较大,大量数据的同步会影响性能
一致性哈希算法分区
针对哈希取余分取,扩容\缩容时因为取余的分母发生变化,导致所有分片需要重新计算;一致性hash通过引入一致性hash环解决这个问题。
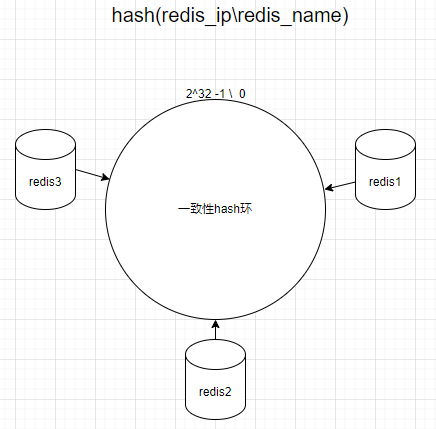
- redis分片
设置一个较大的hash函数取值空间,如2^23 -1,构成hash环,如下图;通过对redis节点的ip或其它唯一属性做hash计算,再对计算结果做2^23 -1的取余得到节点在hash环上的位置
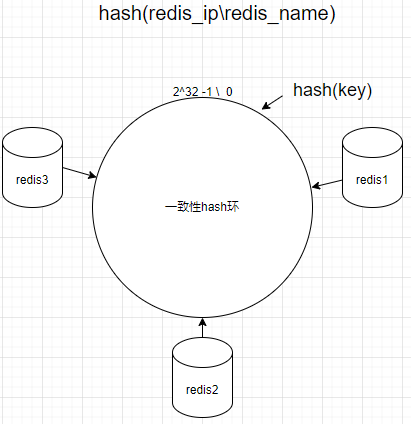
- 数据存储\读取
对缓存数据的key做hash计算,再对计算结果做2^23 -1的取余得到节点在hash环上的位置,从hash环的顺时针方向找到的下一个redis节点便是数据存储节点
优点
扩容\缩容时,数据的映射会按照hash环顺时针找到下一个可用的节点,因此影响的数据范围仅限变化节点逆时针方向区域的数据
缺点
hash函数的取值空间分配不合理时,容易造成数据分配不均,可能出现在部分节点堆积的情况,影响集群分片的效果。
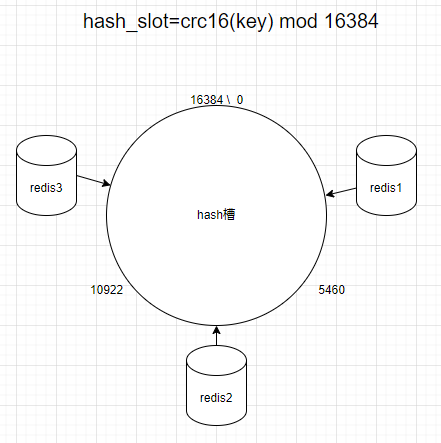
hash槽分区
Hash槽
Redis集群引入的哈希槽,解决数据key的hash分配不均匀的问题,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽位,集群的每个节点负责一部分hash槽位。
分片
每个redis集群节点通过CLUSTER SLOTS分配存储数据的槽位区间
扩容\缩容
根据扩容\缩容后计算节点数,合理计算每个集群节点存储的槽位区间,并通过CLUSTER SLOTS重新分配各节点的槽位分区
实践
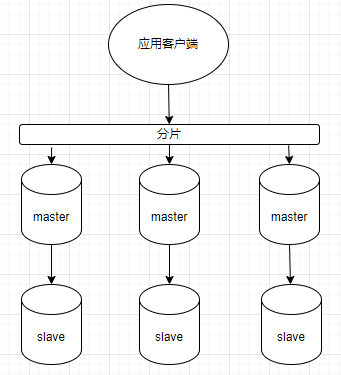
拓扑结构
使用三台机器,搭建三主三从的集群结构,生产环境中六个节点需要分布在六个物理机上,保证数据可恢复。
配置
- 基础配置
参数说明参考:Redis部署-单机部署
bind 0.0.0.0 -::1
port 6379
daemonize yes
pidfile "/var/run/redis_6379.pid"
logfile "/usr/local/redis-7.2.4/cluster/log/redis_6379.log"
save 3600 1 300 100 60 10000
dbfilename "dump6379.rdb"
dir "/usr/local/redis-7.2.4/cluster"
requirepass "redis"
masterauth "redis"
appendonly yes
appendfilename "appendonly6379.aof"
appenddirname "appendonlydir"
aof-use-rdb-preamble yes
- 集群相关配置
* 开启集群
cluster-enabled yes
# 节点配置文件指定
cluster-config-file nodes-6379.conf
# 节点超时下线认定时间
cluster-node-timeout 15000
6个节点修改端口后各自部署
启动
- 执行启动命令
# 本文当前所在工作目录 /usr/local/redis-7.2.4/cluster
redis-server ./redis_cluster6379.conf
redis-server ./redis_cluster26379.conf
- 通过--cluster create创建集群关系
在redis服务器上执行如下命令:
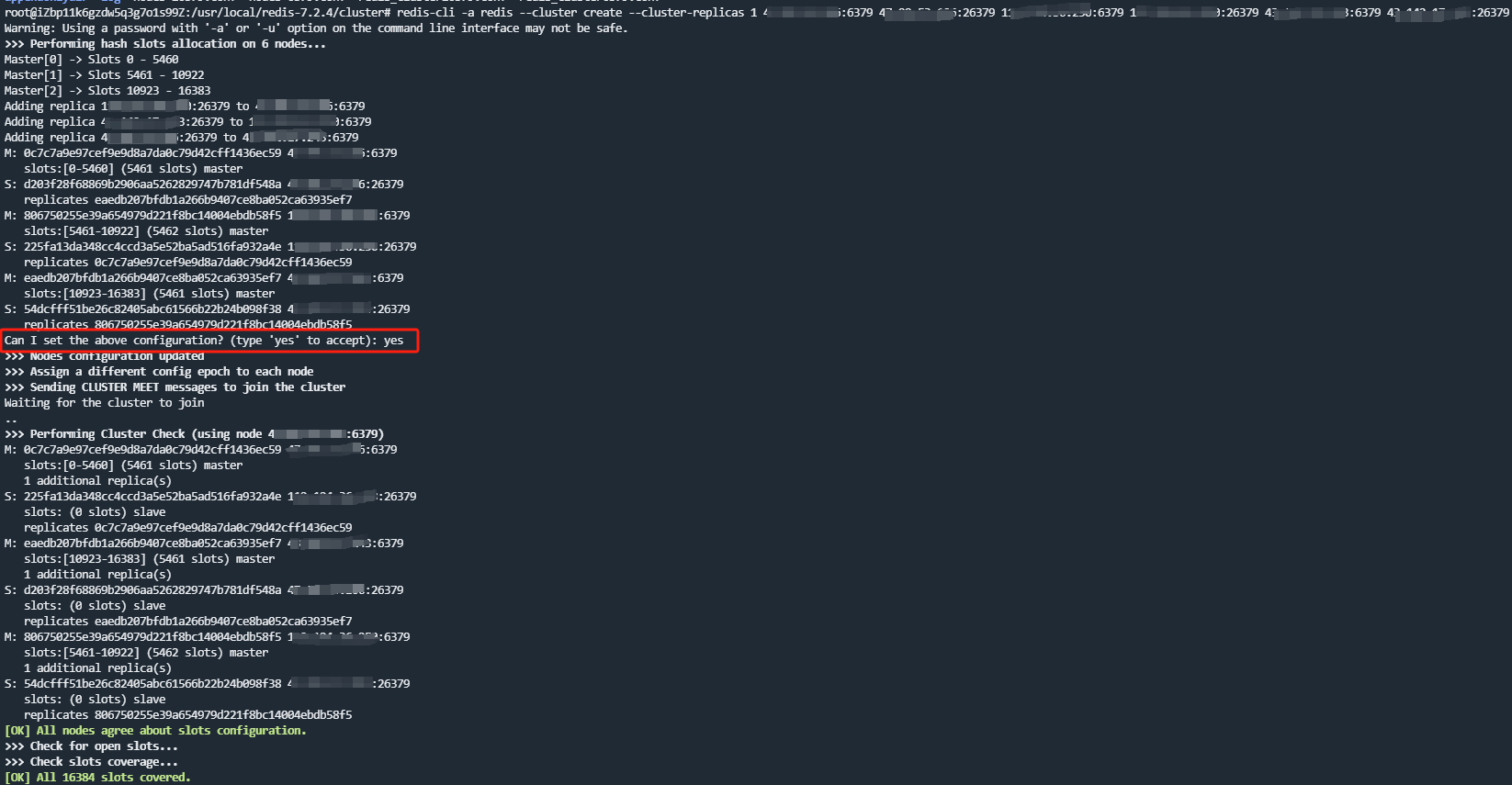
redis-cli -a redis --cluster create --cluster-replicas 1 127.0.0.1:6379 127.0.0.2:26379 127.0.0.3:6379 127.0.0.4:26379 127.0.0.5:6379 127.0.0.6:26379
命令中的ip需要替换成实际ip,[cluster-replicas 1]表示每个master主机拥有一个slave,注意redis集群搭建时不能有数据
注意:搭建集群时需要开通集群总线端口,总线端口在节点端口的基础上+10000,如节点端口位6379,总线端口位16379
需要在控制台输入:yes,确认集群分配的方案
3. 集群搭建结果验证
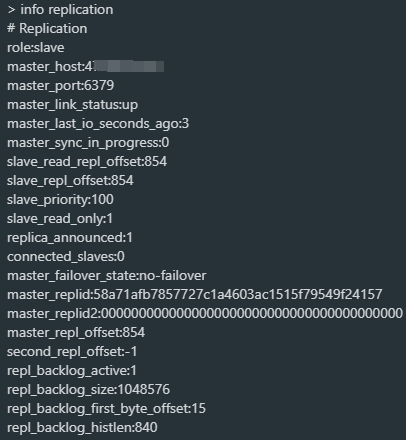
使用info relication命令查看节点主从信息
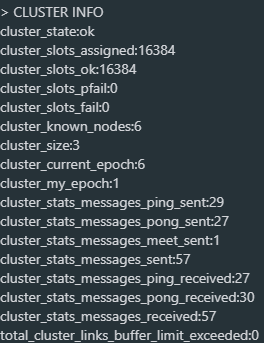
使用CLUSTER INFO命令查看节点集群信息
使用CLUSTER NODES查看所有集群节点

集群扩容
- 新增集群节点,参考上面的启动过程
- 加入集群节点
执行如下命令
redis-cli -a redis --cluster add-node 127.0.0.7:6379 127.0.0.8:26379
- 重新分配槽位
执行reshard命令重新分配槽位 - 添加主从关系
使用culster-slave对新增的集群节点分配主从关系
redis-cli -a redis --cluster add-node 127.0.0.7:6379 127.0.0.8:26379 --cluster-slave --cluster-master-id node_id
集群缩容
- 从集群中删除节点
使用del-node删除节点
redis-cli -a redis --cluster del-node 127.0.0.7:6379 node_id
- 清空被删除节点的槽位,重新分配
redis-cli -a redis --cluster rehard 127.0.0.7:6379
- 删除从节点
redis-cli -a redis --cluster del-node 127.0.0.8:6379 node_id
特征
- 集群不能保证数据的强一致性,当写入数据时,分布写入的master节点宕机,导致slave节点没接收到数据,之后数据重新分配时会出现数据丢失的问题。
- 集群模式下,mset操作的数据放在了同一分区,底层通过{}控制,如mset k1{v1} k2
- 集群模式下,当某一分区的节点全部宕机,是否继续提供服务,通过cluster-require-full-coverage yes控制


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)