网络编程部分试题
第一部分 必答题
-
简述 OSI 7层模型及其作用?(2分)
-
应用层(应用层,表示层,会话层)
在应用层中封装实际的消息数据(HTTP,HTTPS,FTP)
传输层:
封装端口 指定传输的协议(TCP/UDP)
网络层:
封装ip 版本ipv4 / ipv6
数据链路层:
封装mac地址 指定链路层协议: arp(通过ip->mac)/rarp(通过mac->ip)
物理层:
打成数据包,变成二进制的字节流通过网络进行传输 -
物理层:利用传输介质为数据链路层提供物理连接,负责处理数据传输率并监控数据出错率,实现数据流的透明传输
-
数据链路层:在物理层提供的服务基础上,数据链路层在数据实体之间建立数据链路链接,传输以帧为单位的数据包,采用差错控制和流量控制方法看,使有差错的物理链路变成无差错的数据链路
-
网络层:为分组通过网络选择合适的路径,实现路由选择和分组转发拥塞控制等
-
传输层:向用户提供端到端服务,处理数据包错误,数据包次序,向高层屏蔽了下层数据通讯细节
-
会话层:维护两个计算机之间的传输链接,保证点到点传输不中断,以及管理数据交换等
-
表示层:用于处理两个通信系统中交换信息的表示方式,主要有数据格式交换,数据加密解密,数据压缩等
-
应用层:为应用软件提供服务
-
-
简述 TCP三次握手、四次挥手的流程。(3分)
-
#
SYN 创建连接
ACK 确认响应
FIN 断开连接# 三次握手
1. 客户端向服务端发送一个标识了SYN的数据,表示期望与服务端建立连接
2. 服务器回复标识了SYN+ACK的数据,确认客户端的序列号
3. 客户端发送一个标识了ACK的数据段,确认服务器的序列号,并建立连接# 四次挥手
1. 客户端向服务端发送标识了FIN、ACK的数据,表示自己想断开连接
2. 服务器回复一段标识ACK的数据段,确认客户端的序列号
3. 服务器向客户端发送一段标识了FIN、ACK的数据,表示自己想要断开连接
4. 客户端回应一个标识了ACK的数据,确认了服务器的序列号,断开TCP连接
-
-
TCP和UDP的区别?(3分)
-
TCP:传输可靠,面向连接,速度慢,数据长度无限,流式传输,全双工,比如打电话、文件传输、邮件
-
UDP:不可靠、无需建立连接、速度快、面向数据报,数据长度有限,比如发短信、在线视频
-
-
什么是黏包?(2分)
-
当发送多条消息时,接收变成了一条或者出现接收不准确的情况,叫做TCP粘包现象
-
# 黏包:
tcp协议数据因为无边界的特点,导致都填分开发送的数据粘合在一起变成了一条数据
# 现象:
# 情况1:
在发送端,数据小,时间间隔短,容易几个数据粘合在一起
# 情况2:
在接受端,接受数据慢,在缓存区,导致几个数据粘合在了一起
# 解决:
使用struct:
# pack (数据长度在21个亿左右)
"""把任意长度的数字转换成具有4个字节固定长度的字节流"""
res = struct.pack("i",2100000000) #代表当前转化的数据是整型
# unpack
"""把4个字节值恢复成原来的数据,返回的是一个元组"""
tup = struct.unpack("i",res)[0] # 把rev转换成整型int
思路方面:
计算接下来要发送的数据大小是多少
通过pack转化固定4个字节发送给接受段
然后在发送真实数据
接受段需要接受2次,第一次接受转换成的真实数据大小,放recv参数中
第二次在接受真实的数据,才能保证不黏包
场景:
用在及时通讯类中,如果是上传下载不需要.
-
-
什么 B/S 和 C/S 架构?(2分)
-
浏览器/服务器模式和客户端/服务器模式
-
网络开发的两大架构:
c/s : client server 软件
b/s : Brower server 网站,小程序
-
-
请实现一个简单的socket编程(客户端和服务端可以进行收发消息)(3分)
-
 View Code
View Code# 服务端 import socket sk = socket.socket() sk.bind(("127.0.0.1", 9000)) sk.listen() conn, addr = sk.accept() re_msg = conn.recv(1024).decode('utf-8') print(re_msg) conn.close() sk.close() # 服务端 import socket sk = socket.socket() sk.connect(('127.0.0.1', 9000)) msg = input() sk.send(msg.encode('utf-8')) sk.close()
-
View Code
# 一.TCP 服务端 import socket # 1.创建一个socket对象 sk = socket.socket() # 2.绑定ip和端口(注册网络) sk.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) sk.bind( ("127.0.0.1",9000) ) # 3.开启监听 sk.listen() # 4.建立三次握手 conn,addr = sk.accept() # 5.处理收发数据逻辑 # 接受数据 msg = conn.recv(1024) msg.decode("utf-8") # 发送数据 conn.send(b"abc") conn.send("我好帅哦".encode()) # 6.四次挥手 conn.close() # 7.退还端口 sk.close() # 二.TCP 客户端 # 1.创建一个socket对象 sk = socket.socket() # 2.与服务器进行连接 sk.connect( ("127.0.0.1",9000) ) # 3.收发数据的逻辑 # 发送 sk.send(b"abc") # 接受 sk.recv(1024) # 4.关闭链接 sk.close() # 三.TCP / socketserver 支持TCP的并发操作 import socketserver class MyServer(socketserver.BaseRequestHandler): def handle(self): conn = self.request if __name__ == "__main__": server = socketserver.ThreadingTCPServer( ("127.0.0.1",9000) , MyServer ) server.serve_forever() # 四.UDP服务端 import socket # 1.创建一个socket对象 sk = socket.socket(type=socket.SOCK_DGRAM) # 2.绑定地址 sk.bind( ("127.0.0.1",9000) ) # 3.处理收发数据的逻辑(服务器一定第一次是接受数据) # 接受 msg , cli_addr = sk.recvfrom(1024) # 发送 sk.sendto(b"abc" , cli_addr) # 4.关闭udp连接 sk.close() # 五.UDP客户端 # 1.创建一个socket对象 sk = socket.socket(type=socket.SOCK_DGRAM) # 2.收发数据 sk.sendto("你好".encode("utf-8") , ("127.0.0.1",9000) ) sk.recvfrom(1024) # 3.关闭udp连接 sk.close() """ 最大的网络传输数据包大小 (MTU 1500Byte) 一般路由器网络转发数据的数据包大小不超过1500B 超过这个范围,该数据会进行拆包和打包的过程 """
-
-
简述进程、线程、协程的区别?(3分)
-
进程是计算机中分配资源的最小单位
-
from multiprocessing import Process
-
-
线程是计算机中CPU可调度的最小单位
-
from threading import Thread
-
-
协程又被称为微线程,是基于代码人为创造出来的,进程和线程是计算机中真实存在的
-
import gevent;from gevent import monkey monkey.pathch_all() # 识别所有模块中的阻塞 g2 = gevent.spawn(play)
-
-
一个进程中可以有多个线程,一个线程中可以创建多个协程
-
一个进程中的线程共享资源
-
由于GIL锁,计算密集型:多进程;IO密集型:多线程
-
-
什么是GIL锁?(2分)
-
GIL锁:全局解释器锁,为了保证数据安全,只让多线程并发不能并行
-
并发:同一时间,一个cpu执行多个任务
并行:同一时间,多个cpu执行多个任务
GIL:全局解释器锁,为了保证数据安全,只让多线程并发,不能并行
在后台一个个的程序都是由一个个的cpython解释器执行的,每个解释器运行的程序都是单独的进程
但是同一时间,程序中的多个线程只能由一个cpu执行
解决办法:
1.换个jpython等其他解释器,又可能出现兼容性问题
2.用多进程的方式间接实现多线程,资源开销较大
历史遗留问题,无法彻底解决
-
-
进程之间如何进行通信?(2分)
-
IPC :
1.管道Pipe(进程和进程之间只能单向通信)(了解)
2.Queue(进程和进程之间可以双向通信)
3.文件 (共享数据)
q = Queue(3)
put get
put_nowait get_nowait (linux有兼容性问题)
empty full qsize(队列长度)
-
-
Python如何使用线程池、进程池?(2分)
-
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
# (1)创建进程池/线程池对象 8个
p = ProcessPoolExecutor() # 参数:cpu的逻辑处理器数量
p = ThreadPoolExecutor() # 参数:cpu的逻辑处理器数量 * 5
# (2)提交异步任务submit
res = p.submit(func,参数1,参数2,...)
# (3)获取返回值 result (里面有阻塞)
res_new = res.result()
# (4)等待所有子进程执行完毕 shutdown
p.shutdown()
print("主进程执行结束 .. ")
-
-
请通过yield关键字实现一个协程? (2分)
-
View Code
""" # 创建生成器 (1) 生成器表达式: gen = (i for i in range(10)) (2) 生成器函数 : 函数内含有yield,需要初始化才能使用 """ def producer(): for i in range(100): n = yield i print("结果:%s",n) def consumer(): # 生成器函数的初始化 g = producer() # send可以类比next,但是第一次调用时,必须给None,send可以给yield发送数据(上一个yield) g.send(None) for i in range(10): res = g.send(i) print(res) consumer()
-
-
什么是异步非阻塞? (2分)
-
同步:
代码从上到下按照顺序,依次执行
异步:
无需等待当前程序中的代码是否执行完毕,
该代码又开启另外一个进程/线程中执行
阻塞 : input , time , sleep , recv ...
非阻塞 : 依次执行,无需等待
异步非阻塞:
场景发生在多进程/多线程之间
没有任何io阻塞或者等待,同时执行
设置setblocking(False) (设置非阻塞 了解)
-
-
什么是死锁?如何避免?(2分)
-
连锁两次,打不开了
-
避免连续上锁,使用递归锁
-
from threading import Lock
互斥锁,死锁,递归锁
只上锁不解锁是死锁
例如:
lock = Lock()
# 1
lock.acquire()
lock.acquire()
lock.acquire()
# 2
进程1
a.acquire()
b.acquire()
b.release()
a.release()
进程2
b.acquire()
a.acquire()
a.release()
b.release()
进程1 拿着A锁抢B锁
进程2 拿着B锁抢A锁
# 使用递归锁,快速应急,解决服务器死锁问题
a = b = RLock()
a.acquire()
a.acquire()
a.acquire()
a.release()
a.release()
a.release()
多次上锁的次数和多次解锁的次数相同,就能达到解锁的目的;
以后使用锁时,尽力不用锁嵌套;
-
-
程序从flag a执行到falg b的时间大致是多少秒?(2分)
import threading
import time
def _wait():
time.sleep(60)
# flag a
t = threading.Thread(target=_wait)
t.setDaemon(False)
t.start()
# flag b
>>>
0 -
程序从flag a执行到falg b的时间大致是多少秒?(2分)
import threading
import time
def _wait():
time.sleep(60)
# flag a
t = threading.Thread(target=_wait)
t.setDaemon(True) # 设置守护进程
t.start()
# flag b
>>>
0
解析:
守护进程: 守护的是主进程
守护线程: 守护的是所有线程;
你不设置守护的话主程序虽然结束了,但是线程没结束,你这整个程序还没结束,但是从flag a 运行到 flag b是按主程序来算的;而设置了守护,那么主程序在结束时会立即回收线程,不管线程是否结束,只要主程序结束了,那么线程立刻被主程序杀死,结束整个程序 -
程序从flag a执行到falg b的时间大致是多少秒?(2分)
import threading
import time
def _wait():
time.sleep(60)
# flag a
t = threading.Thread(target=_wait)
t.start()
t.join() # 设置了等待
# flag b
>>>
60 -
读程序,请确认执行到最后number是否一定为0(2分)
import threading
loop = int(1E7)
def _add(loop:int = 1):
global number
for _ in range(loop):
number += 1
def _sub(loop:int = 1):
global number
for _ in range(loop):
number -= 1
number = 0
ta = threading.Thread(target=_add,args=(loop,))
ts = threading.Thread(target=_sub,args=(loop,))
ta.start()
ta.join()
ts.start()
ts.join()
>>>
一定为0 -
读程序,请确认执行到最后number是否一定为0(2分)
import threading
loop = int(1E7)
def _add(loop:int = 1):
global number
for _ in range(loop):
number += 1
def _sub(loop:int = 1):
global number
for _ in range(loop):
number -= 1
number = 0
ta = threading.Thread(target=_add,args=(loop,))
ts = threading.Thread(target=_sub,args=(loop,))
ta.start()
ts.start()
ta.join()
ts.join()
>>>
不一定为0 -
MySQL常见数据库引擎及区别?(3分)
-
myisam : 5.5之前的默认存储引擎 , 只支持表级锁(读写互相阻塞)
innodb : 5.5版本之后,默认的存储引擎,支持事务,行级锁,外键,能够抗住更大的并发量(全表扫描,存在表级锁)
memory : 把数据存储在内存里,一般做缓存
blackhole : 黑洞,用来同步数据,应该在主从数据库当中
-
-
简述事务及其特性? (3分)
-
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所做的所有更改都会被撤消。
-
原子性
-
一致性
-
隔离性
-
持久性
-
-
A.原子性:
同一个事务当中可能执行多条sql语句,要么全部成功,要么直接回滚,这个过程看成一个整体,一个不能再分割的最小个体
C.一致性:
a,i,d 都是为了保证数据的一致性提出来的
比如必须按照约束要求插入数据,保证每跳数据类型的一致性
事务角度上,防止脏读,幻读,不可重读,最终决定当前客户端和当前的数据库状态一致
I.隔离性:
lock + isolation锁,来处理事务的隔离级别;
一个事务和另外一个事务在工作过程中彼此隔离独立
如果同时更改同一个数据,因为锁机制的存在,先执行的先改,其他事务需要等待,保证数据安全
D.持久性:
把数据写在磁盘上,保证数据的持久化存储;
-
-
事务的隔离级别?(2分)
-
读未提交(read uncommitted)
-
一个事务还没提交时,它做的变更就能被别的事务看到
-
-
读提交(read committed)
-
一个事务提交之后,它做的变更才会被其他事务看到
-
-
可重复读(repeatable read)
-
一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的
-
-
串行化(serializable )
-
顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行
-
-
脏读: 没提交的数据读出来的 (查)
不可重读: 前后多次读取,数据内容不一样(同一个会话中,在不进行修改或者删除的时候,永远看到的是同一套数据)
幻读:前后多次读取,数据内容不一样(从添加的角度上说的)
# 开始事务
begin:
# 处理sql
# commit 提交数据
# rollback 回滚数据
# 数据的隔离级别
RU(READ_UNCOMMITTED) : 读未提交 : 脏读,不可重读,幻读
RC(READ_COMMITTED) : 读已提交 : 防止脏读,会出现不可重复还有幻读
RR(REPEATABLE_READ) : 可重复读 : 防止脏读,不可重复读,可能会出现幻读(默认隔离级别)
SR(SERLALIZABLE) : 可序列化 : 什么都能防止(多个窗口同步,不能并发,性能差)
# 查看默认的隔离级别
select @@tx_isolation
# 查询是否自动提交数据
select @@autocommit
# 找到my.ini 配置文件
autocommit=0 # 关闭自动提交数据
transaction_isolation = READ_UNCOMMITTED # 设置隔离级别
# 打开窗口1
begin;
update t1 set name = "abc" where id = 1
# commit;
# 打开窗口2
select * from t1;
-
-
char和varchar的区别?(2分)
-
char:定长,节省时间,浪费空间
-
varchar:变长,节省空间,浪费时间 (65535个字节,内容的开头会有1~2个字节存储数据长度)
-
-
mysql中varchar与char的区别以及varchar(50)中的50代表的含义。(2分)
-
char:定长,节省时间,浪费空间
-
varchar:变长,节省空间,浪费时间
-
varchar(50)代表可存储数据最长为50个字符长度
-
字符长度如果小于255个,前头用1个字节存长度
字符长度如果大于255个,前头用2个字节存长度
-
-
MySQL中delete和truncate的区别?(2分)
-
delete 删除数据
truncate 重置表(删除数据+重置自增id)
-
-
where子句中有a,b,c三个查询条件, 创建一个组合索引abc(a,b,c),以下哪种会命中索引(3分)
(a)
(b)
(c)
(a,b)
(b,c)
(a,c)
(a,b,c)
>>>
(a) 命中
(b) 不行
(c) 不行
(a,b) 命中
(b,c) 不行
(a,c) 命中
(a,b,c) 命中 -
组合索引遵循什么原则才能命中索引?(2分)
-
最左前缀原则,条件不能使用范围,可以使用and
# where a>1 and b=1 and c = 100 不能命中
# where b=1 and c = 100 or a = 10 不能命中
-
-
列举MySQL常见的函数? (3分)
-
count
avg
sum
max
min
now()
concat
concat_ws
user => select user()
databases => select databases()
group_concat
year(),month,day(),hour,minute,second week...
password
-
-
MySQL数据库 导入、导出命令有哪些? (2分)
-
# 导出 (\q退出数据库)
mysqldump -uroot -p123 db1 > db1.sql
mysqldump -uroot -p123 db1 表1 表2 表3 > ceshi100.sql
# 导入 (进入到mysql,选好数据库)
source /home/wangwen/work/abc.sql
-
-
什么是SQL注入?(2分)
-
sql注入:通过注入一些特殊的字符,绕开sql的判断机制
# 使用预处理机制,可以尽量避免sql注入
execute 默认参数是一条sql语句,如果加入参数元组,就等于开启预处理
语法:execute(sql,(参数1,参数2,参数3......))
例如:
View Codeimport pymysql user = input("user>>>:").strip() pwd = input("password>>>:").strip() conn = pymysql.connect(host="127.0.0.1",user="root",password="",database="db2") # 创建游标对象 cursor = conn.cursor() # 方法一 """ user>> sdfsd password>> sdfsdf' or 10=10 -- sdfsdfsf sql = "select * from usr_pwd where username = '%s' and password='%s' " % (user,pwd) res = cursor.execute(sql) print(res) #返回条数 """ # 方法二 sql = "select * from usr_pwd where username = %s and password=%s" res = cursor.execute(sql,(user,pwd)) if res: print("登录成功") else: print("登录失败")
-
-
简述left join和inner join的区别?(2分)
-
left join : 左联 以左表为主,右表为辅,完整查询左表所有数据,右表不存在的数据拿null来补
inner join : 内联 查询左表右表共同存在的数据 select * from a,b where a.cid = b.id
-
-
SQL语句中having的作用?(2分)
-
一般和group by 配合使用,将分组之后的数据进行二次过滤用having
-
-
MySQL数据库中varchar和text最多能存储多少个字符?(2分)
-
varchar 存的是字符 21845 最大字节数 65535
text 存的是字符 65535 最大字节数 65535 * 3
-
-
MySQL的索引方式有几种?(3分)
-
主键primary key 唯一索引 unique 普通索引 index
联合主键primary key(字段1,字段2,...)
联合唯一索引 unique(字段1,字段2,..)
联合普通索引 index(a,b,c)
innodb(聚集索引) : 一个表只有一个聚集索引,和多个辅助索引,排序速度比较快
myisam(辅助索引) : 只能有多个辅助索引,没有聚集索引
myisam 和innodb 使用索引数据结构都是b+树,只是叶子节点存储的数据不同
innodb文件结构中只有.frm 和 .ibd, 直接把数据塞到叶子节点上
myisam文件结构中只有.frm .myd .myi 叶子节点存储的该数据的地址(映射关系)
-
-
什么时候索引会失效?(有索引但无法命中索引)(3分)
-
1.如果查询的是一个大范围内的数据(like in > < ....) 不能命中索引
2.索引字段参与运算,不能命中,select * from s1 where id*3 = 600
3.如果有or相连,索引字段的判断条件在or的后面,不能命中索引
4.类型不匹配,不能命中 select * from s1 where first_name = 1000
5.联合索引中,不符合最左前缀原则的,不能命中索引
6.like 以%开头
-
-
数据库优化方案?(3分)
-
1.读写分离(主从数据库,主数据库查询,从数据库负责增删改)
2.分库分表(将字段数量过多的表进行拆分)
3.合理优化数据类型,尽量少的占用空间以合理改善聚集索引b+树的高度(追求矮胖结构)
-
-
什么是MySQL慢日志?(2分)
-
设定一个时间阀值,执行sql的时间超过该阈值,把该sql记录在日志文件里,就是慢查询日志
# 查看日志开启状态
show variables like 'slow_query_log';
# 开启慢查询日志
set global slow_query_log = "ON";
# 查看时间阈值
show variables like "long_query_time"
# 设置时间的阈值
set global long_query_time = 5
....
# 参考: https://www.cnblogs.com/Yang-Sen/p/11384440.html
-
-
设计表,关系如下: 教师, 班级, 学生, 科室。(4分) 科室与教师为一对多关系, 教师与班级为多对多关系, 班级与学生为一对多关系, 科室中需体现层级关系。
1. 写出各张表的逻辑字段
2. 根据上述关系表
a.查询教师id=1的学生数
b.查询科室id=3的下级部门数
c.查询所带学生最多的教师的id-
View Code
teacher 老师 id name post_id 1 王老师 1 2 张老师 1 3 金角大王 2 class 班级 id name 1 python1班 2 python2班 3 python3班 t_c_relation 多对多关系 id tid cid 1 1 1 2 1 2 3 3 1 4 3 2 student 学生 id name class_id 1 李四 1 2 张三 2 post 部门 id name parent_id 1 教务部 0 2 python部 1 3 linux部 1 # a select count(*) from t_c_relation as tc,student as s where tc.cid = s.class_id and tc.tid = 1 # b select count(*) from post where parent_id = 3 # c select tc.tid,count(*) as c from t_c_relation as tc,student as s where tc.cid = s.class_id and tc.tid = 1 group by tc.tid order by c desc limit 1
-
-
有staff表,字段为主键Sid,姓名Sname,性别Sex(值为"男"或"女"),课程表Course,字段为主键Cid,课程名称Cname,关系表SC_Relation,字段为Student表主键Sid和Course表主键Cid,组成联合主键,请用SQL查询语句写出查询所有选"计算机"课程的男士的姓名。(3分)
-
View Code
staff sid sname sex 1 张三 男 2 李四 女 course cid cname 1 计算机 2 美术 sc_relation sid cid 1 1 # as 起别名 select s.sname from staff as s, course as c, sc_relation as sc where sc.sid = s.sid and c.cid = sc.cid and c.cname = "计算机" and s.sex = "男" # as 可以省略 select s.sname from staff s, course c, sc_relation sc where sc.sid = s.sid and c.cid = sc.cid and c.cname = "计算机" and s.sex = "男"
-
-
根据表关系写SQL语句(10分)
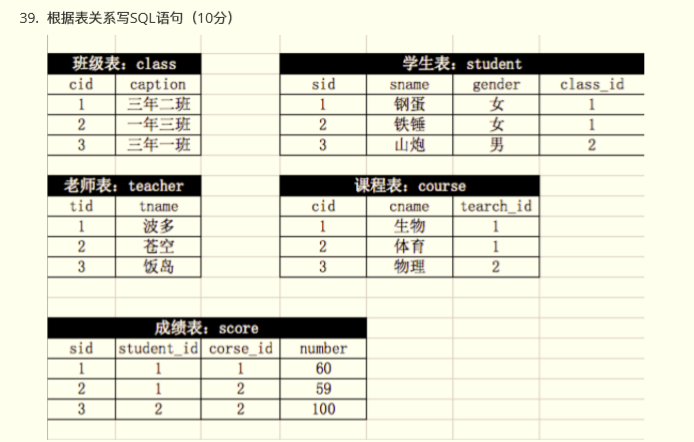
-
查询所有同学的学号、姓名、选课数、总成绩;
-
查询姓“李”的老师的个数;
-
查询平均成绩大于60分的同学的学号和平均成绩;
-
查询有课程成绩小于60分的同学的学号、姓名
-
删除学习“叶平”老师课的score表记录;
-
查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
-
查询每门课程被选修的学生数;
-
查询出只选修了一门课程的全部学生的学号和姓名;
-
查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
-
查询两门以上不及格课程的同学的学号及其平均成绩;
-

第二部分 补充题
-
什么是IO多路复用?
-
内部的实现是异步非阻塞,通过单个线程管理多个socket连接,而不是创建大量的多进程/多线程,节省资源,提升效率
这些网络io操作都会被selector(内部使用linux的epoll多路复用接口实现的)暂时挂起,推入内存队列
此时服务端可以任意处理调度里面的网络io,
当连接的socket有数据的时候,自然会把对应的socket告诉你然后进行读写,而不至于一直阻塞等待
-
-
async/await关键字的作用?
-
asyncio 是在io密集型任务中,处理协程异步并发的工具模块,目的是加快通信的速度,减少阻塞等待
async def 关键字定义异步的协程函数
await 关键字加载需要等待的操作前,控制一个可能发生io阻塞任务的切入和切出
-
-
MySQL的执行计划的作用?
-
执行计划 在一条sql执行之前,制定执行的方案
"""desc/emplain + sql"""
desc select * from t1;
把执行计划的类型,优化级别从低->高
all > index > range > ref > eq_ref > const > system
目标: 至少达到range , ref;
range 索引范围扫描(注意点:如果范围太大,不能命中索引)
ref 普通索引查询(非唯一)
-
-
-
数据库中有表:t_tade_date
id tade_date
1 2018-1-2
2 2018-1-26
3 2018-2-8
4 2018-5-6
...
输出每个月最后一天的ID
>>>
View Codeselect id,max(tade_date) from t_tade_date group by month(tade_date)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号