python_002_简介
目前python应用领域:
- 云计算: 云计算最火的语言, 典型应用OpenStack
- WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。。。, 典型WEB框架有Django
- 科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
- 系统运维: 运维人员必备语言
- 金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
- 图形GUI: PyQT, WxPython,TkInter
python在一些公司的应用:
- 谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
- CIA: 美国中情局网站就是用Python开发的
- NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算
- YouTube:世界上最大的视频网站YouTube就是用Python开发的
- Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
- Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
- Facebook:大量的基础库均通过Python实现的
- Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
- 豆瓣: 公司几乎所有的业务均是通过Python开发的
- 知乎: 国内最大的问答社区,通过Python开发(国外Quora)
- 春雨医生:国内知名的在线医疗网站是用Python开发的
- 除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。
python是一门什么样的语言?
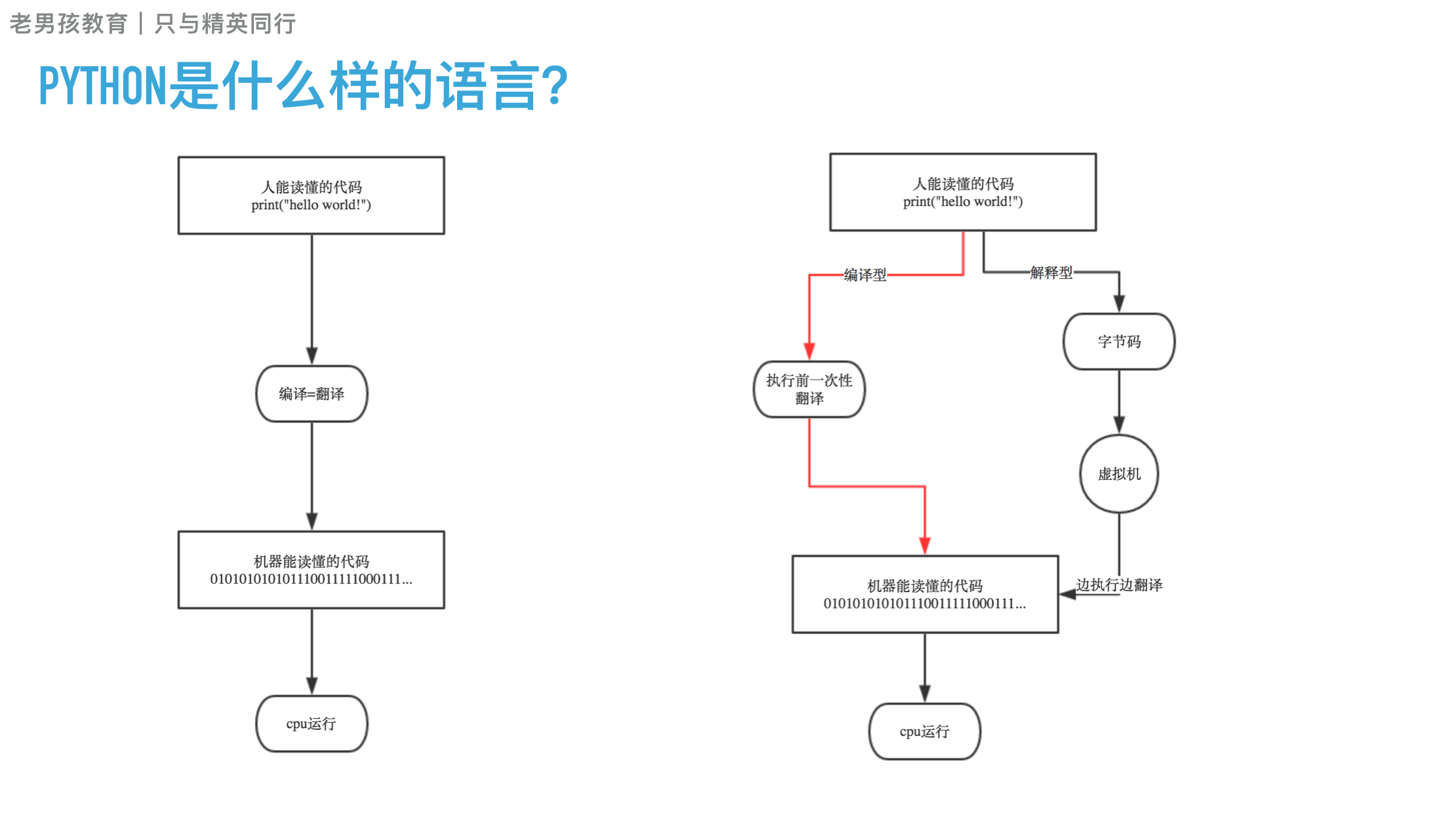
编程语言主要从以下几个角度进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言。
编译型和解释行
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本 语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。此外,Java情况比较特殊,首先Java是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。其实python也一样,当我们执行python程序时,他也一样执行了这么一个过程,这个过程不需要人工参与,而且会产生一个.pyc的文件,所以我们应该这样来描述Python,python是一门先编译后解释的语言
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言
简述python的运行过程
Python中存在这两个概念,PyCodeObject和pyc文件,PyCodeObject是Python编译器真正编译成的结果
当python程序运行时,编译的结果保存在位于内存中的PyCodeObject中,当Python程序运行结束后,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们可以将pyc文件看作PyCodeObject的一种持久化保存方式。
python解释器
CPython
当我们从Python官方网站下载并安装好Python 2.7后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
python编程基础知识
小例子
name="zlt" name2=name name="dddd" print(name) print(name2)
输出:
dddd
zlt
可以看出name2并非通过name指向“zlt”的内存地址,而是直接指向“zlt”的内存地址
用户输入
1 #!/usr/bin/env python 2 # _*_coding:utf-8_*_ 3 # Author:zlt 4 5 username=input("username:") 6 password=input("password:") 7 print(username,password)
输入密码时如果想要不可见,需要利用getpass方法,
#!/usr/bin/env python # _*_coding:utf-8_*_ # Author:zlt import getpass password=getpass.getpass("password:") #在命令行可以执行,是密文,在pycharm中看不到效果 print(password)
格式化输出
#!/usr/bin/env python # _*_coding:utf-8_*_ # Author:zlt username=input("username:") age=int(input("age:")) #python3 里input 默认是str print(type(age),type(str(age))) job=input("job:") salary=input("salary:") #格式化输出 info=''' ---------info of %s-------- name:%s password:%d job:%s salary:%s ''' %(username,username,age,job,salary) print(info) # %s 表示 String # %d 表示 int info2=''' ---------info2 of {name}-------- name:{nam} age:{a} job:{jo} salary:{sa} '''.format(name=username,nam=username,a=age,jo=job,sa=salary) print(info2) info3=''' ---------info3 of {0}-------- name:{0} age:{1} job:{2} salary:{3} '''.format(username,age,job,salary) print(info3)
表达式 while


# _*_coding:utf-8_*_ # Author:zlt age_of_oldboy=56 count=0 while count<3: guess_age=int(input("guess age:")) if guess_age==age_of_oldboy: print("yes, you got it.") break elif guess_age>age_of_oldboy: print("think smaller...") else: print("think bigger!") count +=1 else: #当while的条件不满足的时候就执行else print("you have tried too many times... fuck off!")
表达式for
#!/usr/bin/env python # _*_coding:utf-8_*_ # Author:zlt age_of_oldboy=56 count=0 for i in range(3): guess_age=int(input("guess age:")) if guess_age==age_of_oldboy: print("yes, you got it.") break elif guess_age>age_of_oldboy: print("think smaller...") else: print("think bigger!") count +=1 else:#上面正常走完,就执行else,如果上面break,则不再执行else print("you have tried too many times... fuck off!")
三级菜单
使用dict和list实现
#!/usr/bin/env python # _*_coding:utf-8_*_ # Author:zlt ################################################# # Task Name: 三级菜单 # # Description:打印省、市、县三级菜单 # # 可返回上一级 # # 可随时退出程序 # # ----------------------------------------------# # Author:Oliver Lee # ################################################# meum={ '山东':{ '青岛' : ['四方','黄岛','崂山','李沧','城阳'], '济南' : ['历城','槐荫','高新','长青','章丘'], '烟台' : ['龙口','莱山','牟平','蓬莱','招远'] }, '江苏':{ '苏州' : ['沧浪','相城','平江','吴中','昆山'], '南京' : ['白下','秦淮','浦口','栖霞','江宁'], '无锡' : ['崇安','南长','北塘','锡山','江阴'] }, '浙江':{ '杭州' : ['西湖','江干','下城','上城','滨江'], '宁波' : ['海曙','江东','江北','镇海','余姚'], '温州' : ['鹿城','龙湾','乐清','瑞安','永嘉'] } } meum_keys = meum.keys() print(type(meum_keys)) for key in meum_keys: print(key,end=" ") print() while True: dirname=input("退出请输入Q , 继续请输入省或市名称:") if dirname.lower()=="q": break if meum_keys.__contains__(dirname): meum_2 = meum[dirname] for key_2 in meum_2.keys(): print(key_2, end=" ") print() else: flag=False for key in meum_keys: meum_2=meum[key] meum_2_keys=meum_2.keys() if meum_2_keys.__contains__(dirname): print(meum_2[dirname]) flag=True break else: continue if not flag: print("没有找到您输入的省、市名称")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号