全网最详细的再次或多次格式化导致namenode的ClusterID和datanode的ClusterID之间不一致的问题解决办法(图文详解)
不多说,直接上干货!
java.io.IOException: Incompatible clusterIDs in /opt/modules/hadoop-2.6.0/data/tmp/dfs/data: namenode clusterID = CID-10c4a581-792e-48a2-932b-c279a448df47; datanode clusterID = CID-ea44321a-a510-430f-93b7-4334c3c800b7
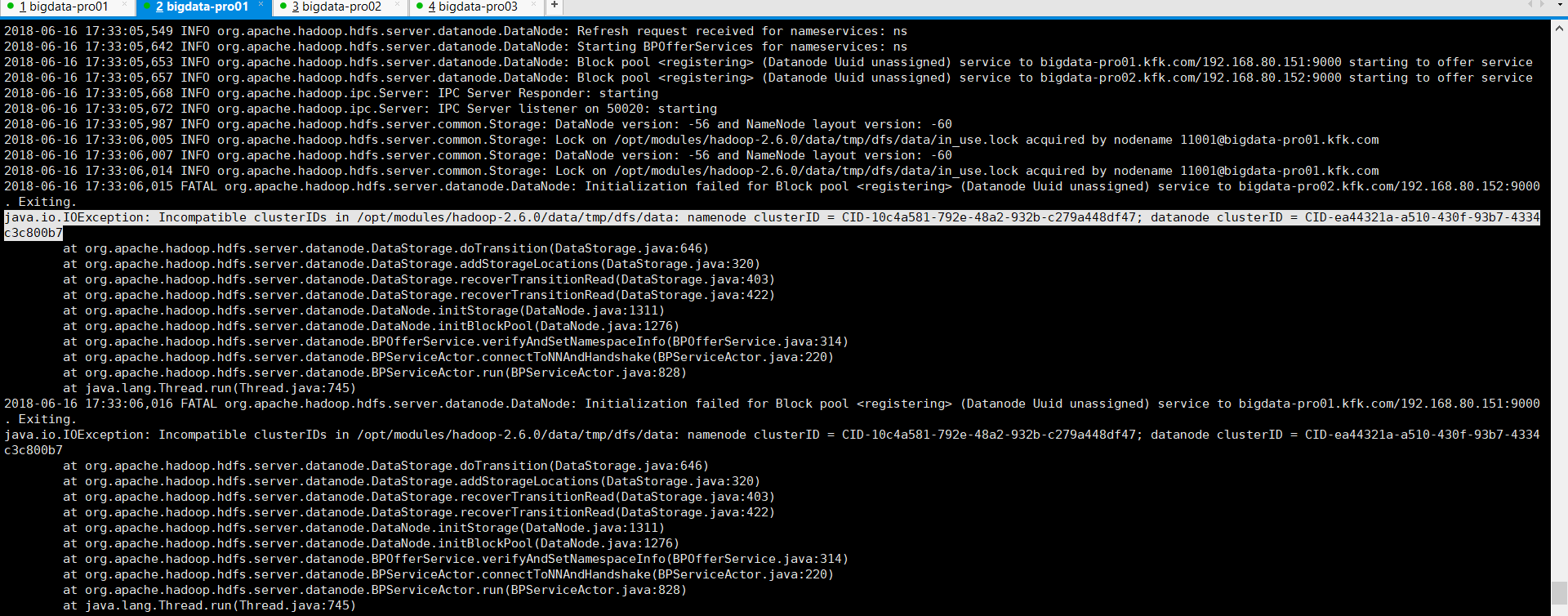
2018-06-16 17:33:05,642 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting BPOfferServices for nameservices: ns 2018-06-16 17:33:05,653 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool <registering> (Datanode Uuid unassigned) service to bigdata-pro01.kfk.com/192.168.80.151:9000 starting to offer service 2018-06-16 17:33:05,657 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool <registering> (Datanode Uuid unassigned) service to bigdata-pro02.kfk.com/192.168.80.152:9000 starting to offer service 2018-06-16 17:33:05,668 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting 2018-06-16 17:33:05,672 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 50020: starting 2018-06-16 17:33:05,987 INFO org.apache.hadoop.hdfs.server.common.Storage: DataNode version: -56 and NameNode layout version: -60 2018-06-16 17:33:06,005 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /opt/modules/hadoop-2.6.0/data/tmp/dfs/data/in_use.lock acquired by nodename 11001@bigdata-pro01.kfk.com 2018-06-16 17:33:06,007 INFO org.apache.hadoop.hdfs.server.common.Storage: DataNode version: -56 and NameNode layout version: -60 2018-06-16 17:33:06,014 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /opt/modules/hadoop-2.6.0/data/tmp/dfs/data/in_use.lock acquired by nodename 11001@bigdata-pro01.kfk.com 2018-06-16 17:33:06,015 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to bigdata-pro02.kfk.com/192.168.80.152:9000. Exiting. java.io.IOException: Incompatible clusterIDs in /opt/modules/hadoop-2.6.0/data/tmp/dfs/data: namenode clusterID = CID-10c4a581-792e-48a2-932b-c279a448df47; datanode clusterID = CID-ea44321a-a510-430f-93b7-4334c3c800b7 at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:646) at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:320) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:403) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:422) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1311) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1276) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:314) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:220) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:828) at java.lang.Thread.run(Thread.java:745) 2018-06-16 17:33:06,016 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to bigdata-pro01.kfk.com/192.168.80.151:9000. Exiting. java.io.IOException: Incompatible clusterIDs in /opt/modules/hadoop-2.6.0/data/tmp/dfs/data: namenode clusterID = CID-10c4a581-792e-48a2-932b-c279a448df47; datanode clusterID = CID-ea44321a-a510-430f-93b7-4334c3c800b7 at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:646) at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:320) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:403) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:422) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1311) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1276) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:314) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:220) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:828) at java.lang.Thread.run(Thread.java:745) 2018-06-16 17:33:06,022 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool <registering> (Datanode Uuid unassigned) service to bigdata-pro01.kfk.com/192.168.80.151:9000
解决办法:
改为最新的,一致,即可。
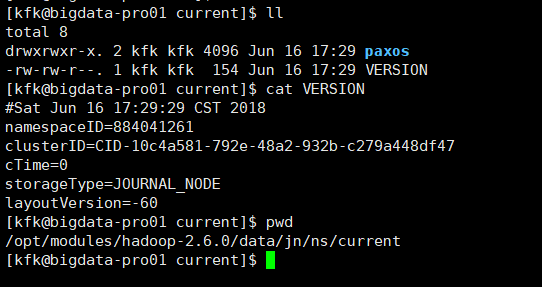
[kfk@bigdata-pro01 ns]$ cd current/ [kfk@bigdata-pro01 current]$ ll total 8 drwxrwxr-x. 2 kfk kfk 4096 Jun 16 17:29 paxos -rw-rw-r--. 1 kfk kfk 154 Jun 16 17:29 VERSION [kfk@bigdata-pro01 current]$ cat VERSION #Sat Jun 16 17:29:29 CST 2018 namespaceID=884041261 clusterID=CID-10c4a581-792e-48a2-932b-c279a448df47 cTime=0 storageType=JOURNAL_NODE layoutVersion=-60 [kfk@bigdata-pro01 current]$ pwd /opt/modules/hadoop-2.6.0/data/jn/ns/current [kfk@bigdata-pro01 current]$
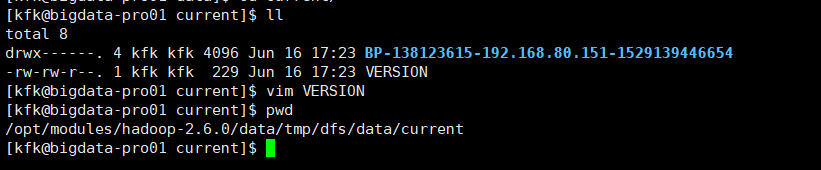
[kfk@bigdata-pro01 current]$ ll total 8 drwx------. 4 kfk kfk 4096 Jun 16 17:23 BP-138123615-192.168.80.151-1529139446654 -rw-rw-r--. 1 kfk kfk 229 Jun 16 17:23 VERSION [kfk@bigdata-pro01 current]$ vim VERSION [kfk@bigdata-pro01 current]$ pwd /opt/modules/hadoop-2.6.0/data/tmp/dfs/data/current [kfk@bigdata-pro01 current]$

[kfk@bigdata-pro02 current]$ cat VERSION #Sat Jun 16 17:31:31 CST 2018 namespaceID=884041261 clusterID=CID-10c4a581-792e-48a2-932b-c279a448df47 cTime=0 storageType=NAME_NODE blockpoolID=BP-1432817714-192.168.80.151-1529141369820 layoutVersion=-60 [kfk@bigdata-pro02 current]$ pwd /opt/modules/hadoop-2.6.0/data/tmp/dfs/name/current [kfk@bigdata-pro02 current]$

[kfk@bigdata-pro03 current]$ pwd /opt/modules/hadoop-2.6.0/data/tmp/dfs/data/current [kfk@bigdata-pro03 current]$ cat VERSION #Sat Jun 16 17:24:24 CST 2018 storageID=DS-dd6ab07e-640c-467d-88cf-ee421a0a2289 clusterID=CID-10c4a581-792e-48a2-932b-c279a448df47 cTime=0 datanodeUuid=05ce9b98-1e61-490c-8063-43398f96c12e storageType=DATA_NODE layoutVersion=-56 [kfk@bigdata-pro03 current]$
先,
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/stop-all.sh
再 ,
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/start-all.sh
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号