牛客网Java刷题知识点之字符流缓冲区、BufferedWriter、BufferedReader、BufferedReader-readLine方法原理、自定义MyBufferedReader-read方法、自定义MyBufferedReader-readLine方法
不多说,直接上干货!
把提高效率的动作,封装成一个对象。即把缓冲区封装成一个对象。
就是在一个类里封装一个数组,能对流锁操作数据进行缓存。
什么是字符流缓冲区?
善于使用字符流缓冲区,减轻负担,提高下效率。
其实啊,无非是将源中数据,存储到自定义数组里,进行缓存。并对数组操作,从而提高效率。
即BufferedReader 比 FileReader要增强。
BufferedWriter 比 FileWriter要增强。
什么情况下需要使用字符流缓冲区?
先从一个例子,来由浅入深的
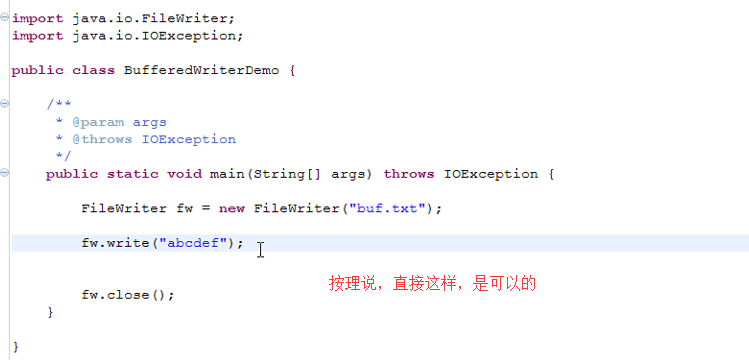
为了提高写入的效率,需引入字符流的缓冲区。
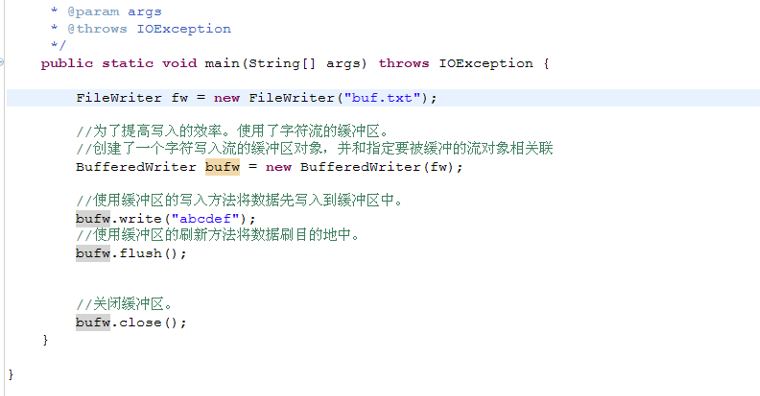
BufferedWriterDemo.java
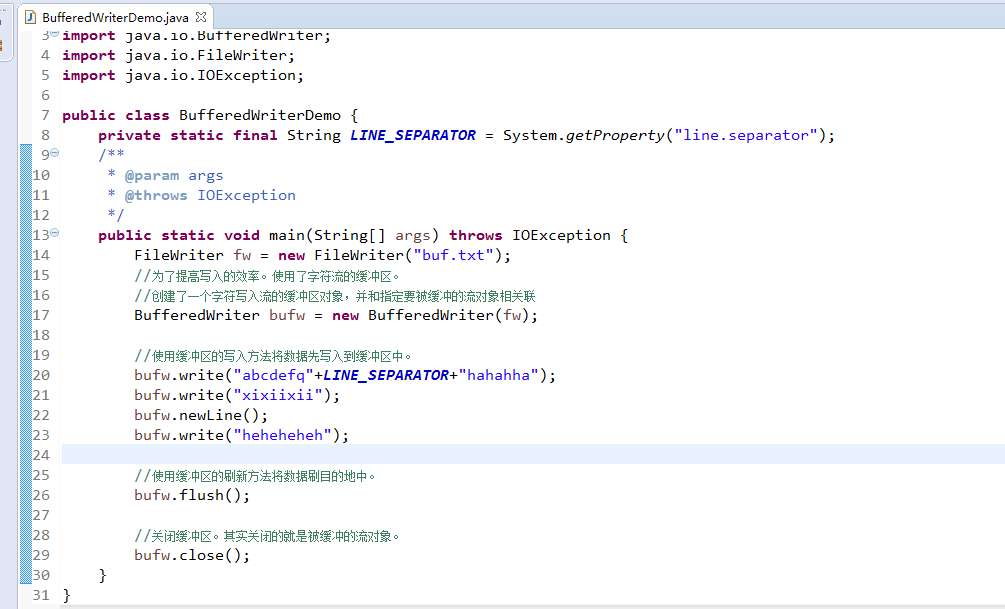
package zhouls.bigdata.DataFeatureSelection.test; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; public class BufferedWriterDemo { private static final String LINE_SEPARATOR = System.getProperty("line.separator"); /** * @param args * @throws IOException */ public static void main(String[] args) throws IOException { FileWriter fw = new FileWriter("buf.txt"); //为了提高写入的效率。使用了字符流的缓冲区。 //创建了一个字符写入流的缓冲区对象,并和指定要被缓冲的流对象相关联 BufferedWriter bufw = new BufferedWriter(fw); //使用缓冲区的写入方法将数据先写入到缓冲区中。 bufw.write("abcdefq"+LINE_SEPARATOR+"hahahha"); bufw.write("xixiixii"); bufw.newLine(); bufw.write("heheheheh"); //使用缓冲区的刷新方法将数据刷目的地中。 bufw.flush(); //关闭缓冲区。其实关闭的就是被缓冲的流对象。 bufw.close(); } }
由fw变成bufw
同样,为了读取的效率,引入字符流缓冲区。
BufferedReaderDemo.java
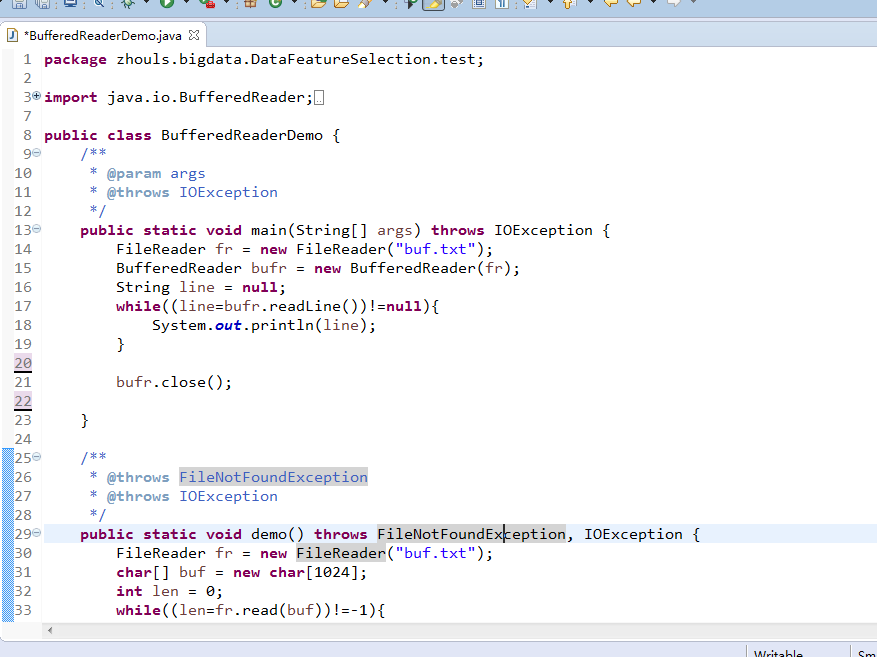
package zhouls.bigdata.DataFeatureSelection.test; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class BufferedReaderDemo { /** * @param args * @throws IOException */ public static void main(String[] args) throws IOException { FileReader fr = new FileReader("buf.txt"); BufferedReader bufr = new BufferedReader(fr); String line = null; while((line=bufr.readLine())!=null){ System.out.println(line); } bufr.close(); } /** * @throws FileNotFoundException * @throws IOException */ public static void demo() throws FileNotFoundException, IOException { FileReader fr = new FileReader("buf.txt"); char[] buf = new char[1024]; int len = 0; while((len=fr.read(buf))!=-1){ System.out.println(new String(buf,0,len)); } fr.close(); } }
BufferedReader-readLine方法原理
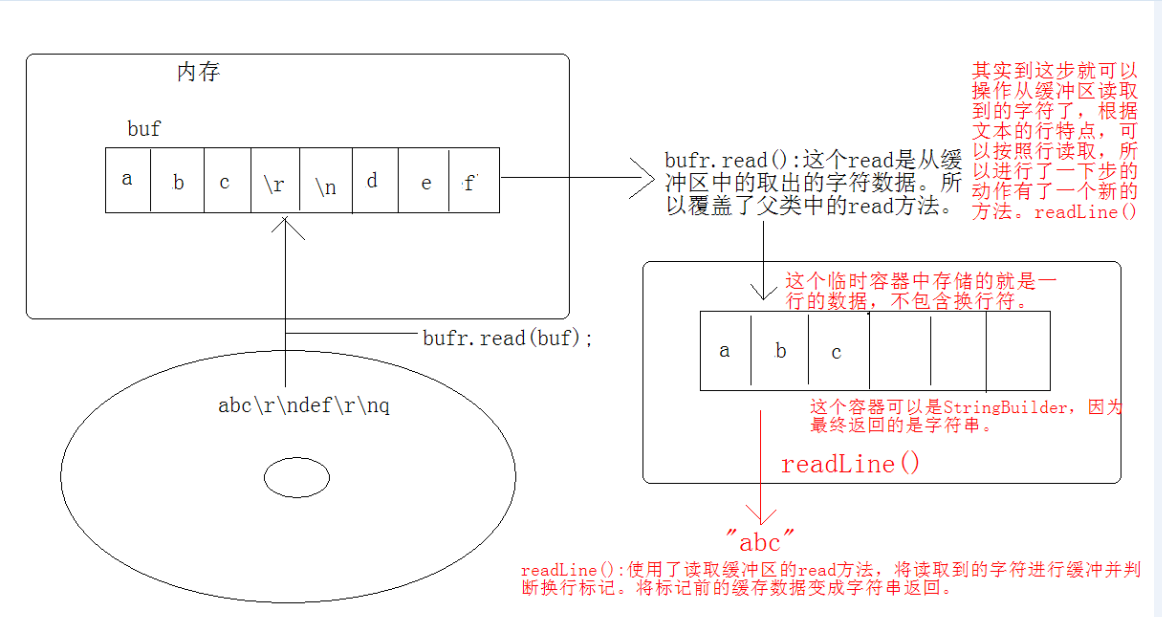
自定义MyBufferedReader-read方法和自定义MyBufferedReader-readLine方法
MyBufferedReader.java
其实啊,无非是将源中数据,存储到自定义数组里,进行缓存。并对数组操作,从而提高效率。
即BufferedReader 比 FileReader要增强。
BufferedWriter 比 FileWriter要增强。
package zhouls.bigdata.DataFeatureSelection.test; import java.io.FileReader; import java.io.IOException; import java.io.Reader; /** * 自定义的读取缓冲区。其实就是模拟一个BufferedReader. * * 分析: * 缓冲区中无非就是封装了一个数组, * 并对外提供了更多的方法对数组进行访问。 * 其实这些方法最终操作的都是数组的角标。 * * 缓冲的原理: * 其实就是从源中获取一批数据装进缓冲区中。 * 在从缓冲区中不断的取出一个一个数据。 * * 在此次取完后,在从源中继续取一批数据进缓冲区。 * 当源中的数据取光时,用-1作为结束标记。 * * @author Administrator */ public class MyBufferedReader extends Reader { private Reader r; //定义一个数组作为缓冲区。 private char[] buf = new char[1024]; //定义一个指针用于操作这个数组中的元素。当操作到最后一个元素后,指针应该归零。 private int pos = 0; //定义一个计数器用于记录缓冲区中的数据个数。 当该数据减到0,就从源中继续获取数据到缓冲区中。 private int count = 0; MyBufferedReader(Reader r){ this.r = r; } /** * 该方法从缓冲区中一次取一个字符。 * @return * @throws IOException */ public int myRead() throws IOException{ if(count==0){ count = r.read(buf); pos = 0; } if(count<0) return -1; char ch = buf[pos++]; count--; return ch; /* //1,从源中获取一批数据到缓冲区中。需要先做判断,只有计数器为0时,才需要从源中获取数据。 if(count==0){ count = r.read(buf); if(count<0) return -1; //每次获取数据到缓冲区后,角标归零. pos = 0; char ch = buf[pos]; pos++; count--; return ch; }else if(count>0){ char ch = buf[pos]; pos++; count--; return ch; }*/ } public String myReadLine() throws IOException{ StringBuilder sb = new StringBuilder(); int ch = 0; while((ch = myRead())!=-1){ if(ch=='\r') continue; if(ch=='\n') return sb.toString(); //将从缓冲区中读到的字符,存储到缓存行数据的缓冲区中。 sb.append((char)ch); } if(sb.length()!=0) return sb.toString(); return null; } public void myClose() throws IOException { r.close(); } public int read(char[] cbuf, int off, int len) throws IOException { return 0; } public void close() throws IOException { } }
MyBufferedReaderDemo.java
package zhouls.bigdata.DataFeatureSelection.test; import java.io.FileReader; import java.io.IOException; import java.util.Collections; import java.util.HashMap; public class MyBufferedReaderDemo { /** * @param args * @throws IOException */ public static void main(String[] args) throws IOException { FileReader fr = new FileReader("buf.txt"); MyBufferedReader bufr = new MyBufferedReader(fr); String line = null; while((line=bufr.myReadLine())!=null){ System.out.println(line); } bufr.myClose(); Collections.reverseOrder(); HashMap map = null; map.values(); } }
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号