Spark Mllib里的分布式矩阵(行矩阵、带有行索引的行矩阵、坐标矩阵和块矩阵概念、构成)(图文详解)
不多说,直接上干货!
Distributed matrix : 分布式矩阵
一般能采用分布式矩阵,说明这数据存储下来,量还是有一定的。
在Spark Mllib里,提供了四种分布式矩阵存储形式,均由支持长整形的行列数和双精度浮点型的数据内容组成。
包括行矩阵、带有行索引的行矩阵、坐标矩阵和块矩阵。 依据你数据的不同的特点,你可以选择不同类型的数据。
(1)、行矩阵: 以行为基本方向的矩阵存储格式,列的作用相对较少。
理解记忆,行矩阵是一个巨大的特征向量的集合
每一行就是一个具有相同格式的向量数据,且每一行的向量内容都可以单独取出来进行操作。
要注意的是,此种矩阵不能按照行号访问。(我也不知道为什么这样)
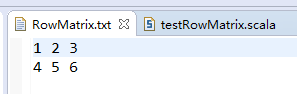
testRowMatrix.scala

package zhouls.bigdata.chapter4
import org.apache.spark._
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.linalg.distributed.RowMatrix
object testRowMatrix {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("testRowMatrix") //设定名称
val sc = new SparkContext(conf) //创建环境变量实例
val rdd = sc.textFile("data/input/chapter4/RowMatrix.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(line => Vectors.dense(line)) //转成Vector格式
val rm = new RowMatrix(rdd) //读入行矩阵
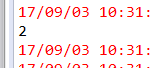
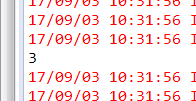
println(rm.numRows()) //打印列数
println(rm.numCols()) //打印行数
}
}
这里,我带你是的
RowMatrix要从RDD[Vector]构造,m是mat的行数,n是mat的列。
(2) 带有行索引的矩阵
单纯的行矩阵对其内容无法进行直接显示,当然可以通过调用其方法显示内部数据内推。即通过带有行索引的行矩阵。
IndexedRowMatrix矩阵和RowMatrix矩阵的不同之处在于,你可以通过索引值来访问每一行。其他的,没啥区别。
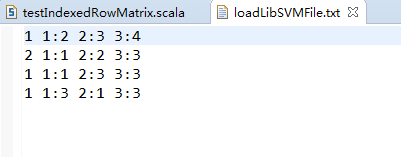
testIndexedRowMatrix.scala
package zhouls.bigdata.chapter4
import org.apache.spark._
import org.apache.spark.mllib.linalg.distributed.{IndexedRow, RowMatrix, IndexedRowMatrix}
import org.apache.spark.mllib.linalg.{Vector, Vectors}
object testIndexedRowMatrix {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("testIndexedRowMatrix") //设定名称
val sc = new SparkContext(conf)
//创建环境变量实例
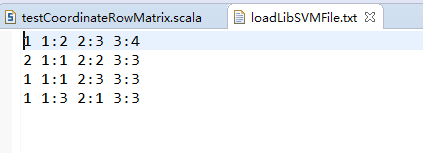
val rdd = sc.textFile("data/input/chapter4/loadLibSVMFile.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(line => Vectors.dense(line)) //转化成向量存储
.map((vd) => new IndexedRow(vd.size,vd)) //转化格式
val irm = new IndexedRowMatrix(rdd) //建立索引行矩阵实例
println(irm.getClass) //打印类型
println(irm.rows.foreach(println)) //打印内容数据
}
}
打印结果是
class org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix
IndexedRow(3,[1.0,2.0,3.0])
IndexedRow(3,[4.0,5.0,6.0])
注意:IndexedRowMatrix除了这个带有行索引的行矩阵功能外,还有其他功能,如:
toRowMatrix将其转化成单纯的行矩阵,toCoordinateMatrix将其转化成坐标矩阵,toBlockMatrix将其转化成块矩阵。
(3) 坐标矩阵
是一种带有坐标标记的矩阵。
坐标矩阵一般用于数据比较多且数据较为分散的情形,即矩阵中含0或者某个具体值较多的情况下。
当你的数据特别稀疏的时候怎么办?采用这种坐标矩阵吧。
CoordinateMatrix矩阵中的存储形式是(row,col,value),就是原始的最稀疏的方式,所以如果矩阵比较稠密,别用这种数据格式。
其中的每一个具体数据都有一组坐标进行标示。其类型格式如下:
(x: Long , y:Long , value:Double)
x和y分别代表标示坐标的坐标轴标号,value是具体内容。x是行坐标,y是列坐标。
testCoordinateRowMatrix.scala
package zhouls.bigdata.chapter4
import org.apache.spark._
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
object testCoordinateRowMatrix {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("testCoordinateRowMatrix") //设定名称
val sc = new SparkContext(conf) //创建环境变量实例
val rdd = sc.textFile("data/input/chapter4/loadLibSVMFile.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(vue => (vue(0).toLong,vue(1).toLong,vue(2))) //转化成坐标格式
.map(vue2 => new MatrixEntry(vue2 _1,vue2 _2,vue2 _3)) //转化成坐标矩阵格式
val crm = new CoordinateMatrix(rdd) //实例化坐标矩阵
println(crm.entries.foreach(println)) //打印数据
}
}
运行结果是,
MatrixEntry(1,2,3.0) MatrixEntry(4,5,6.0)
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号