

Spark Mllib里数据集如何取前M行(图文详解)
不多说,直接上干货!

见具体,
Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
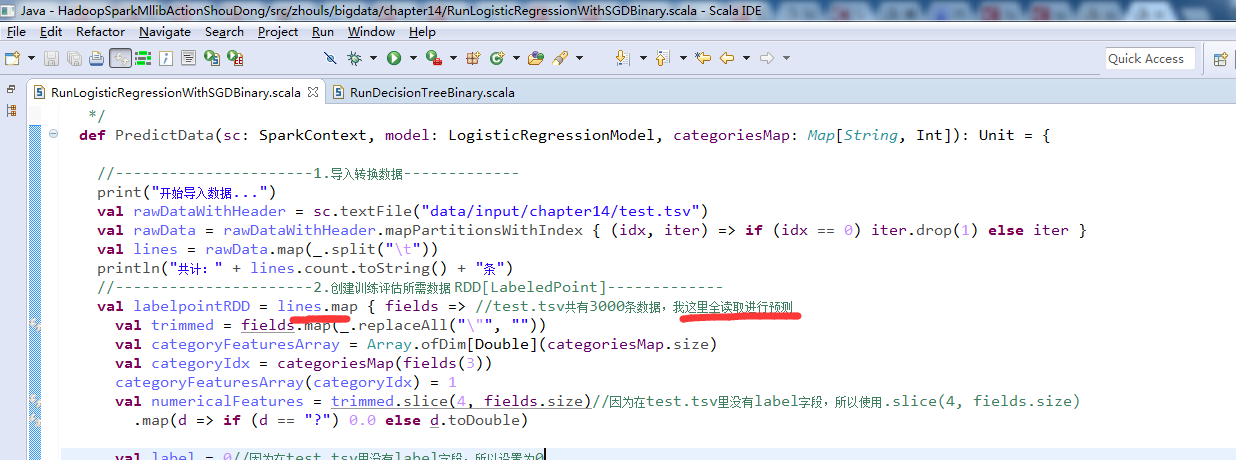
见具体
Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第14章 使用逻辑回归二元分类算法来预测分类StumbleUpon数据集
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

