

spark-2.2.0-bin-hadoop2.6和spark-1.6.1-bin-hadoop2.6发行包自带案例全面详解(java、python、r和scala)之环境准备(图文详解)
不多说,直接上干货!
关于下载,这两个spark-2.2.0-bin-hadoop2.6和spark-1.6.1-bin-hadoop2.6发行包不多赘述。
http://archive.apache.org/dist/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.6.tgz http://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.6.tgz
我是解压在D:\SoftWare方便为了导入其中的所需jar包

这里,我是在Scala IDEA for Eclipse里,手动来构建spark-1.6.1-bin-hadoop2.6和spark-2.2.0-bin-hadoop2.6发行包的scala代码环境
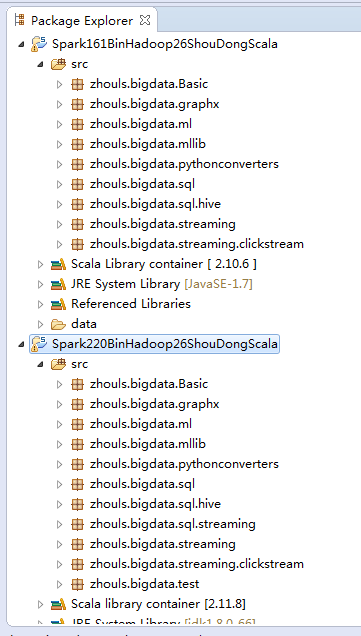
这里,我是在Scala IDEA for Eclipse里,手动来构建spark-1.6.1-bin-hadoop2.6发行包的java代码环境
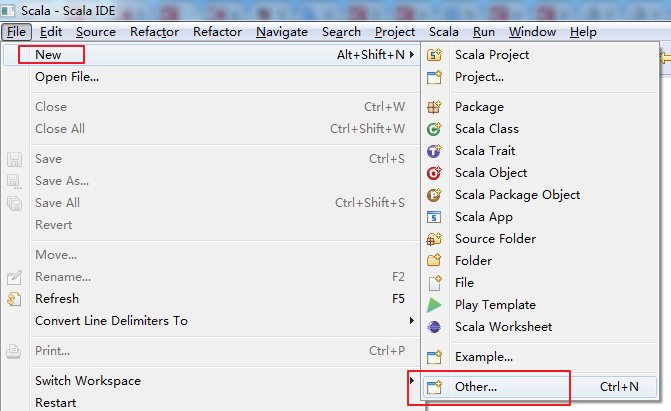

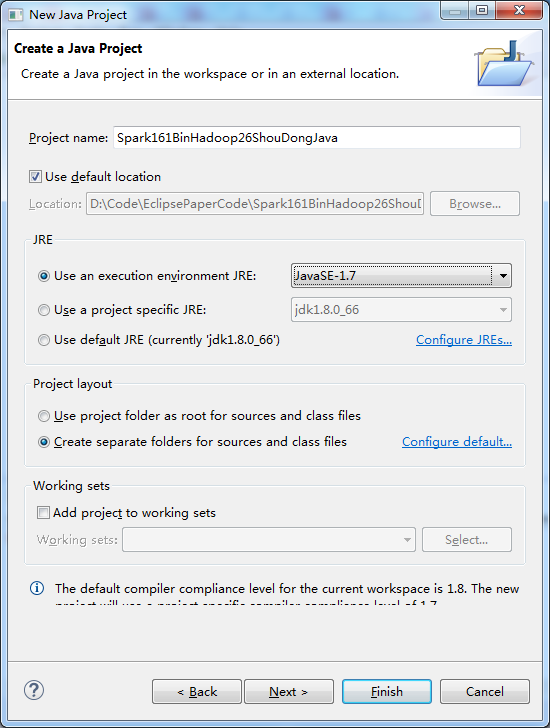
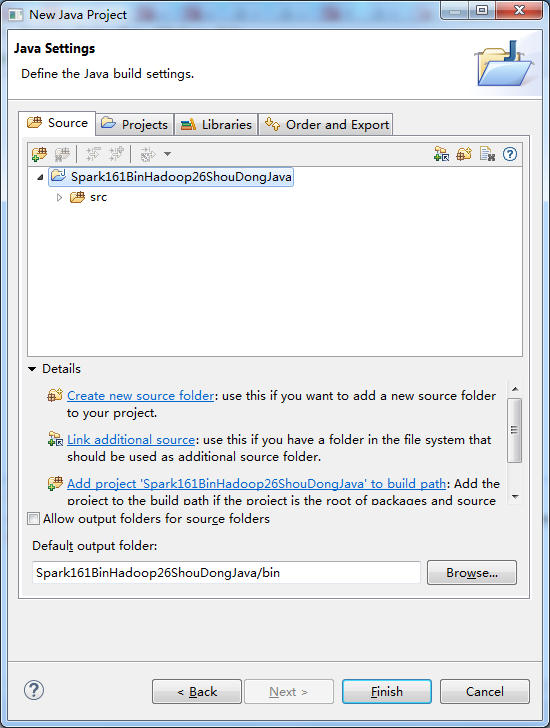

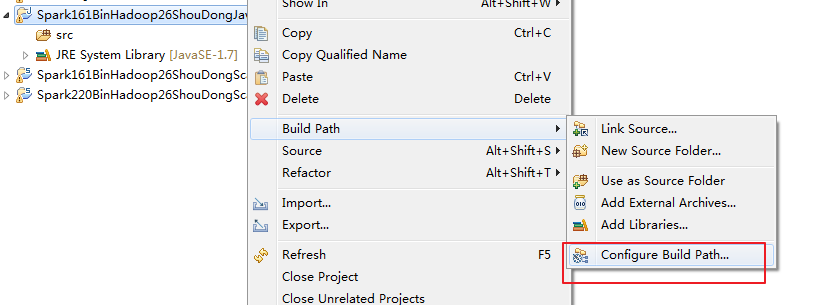

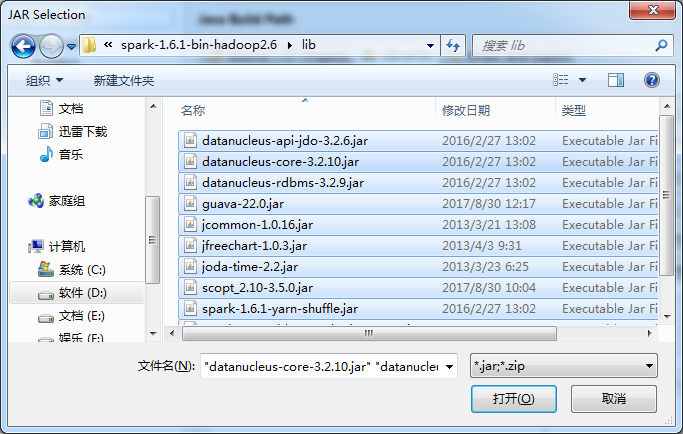
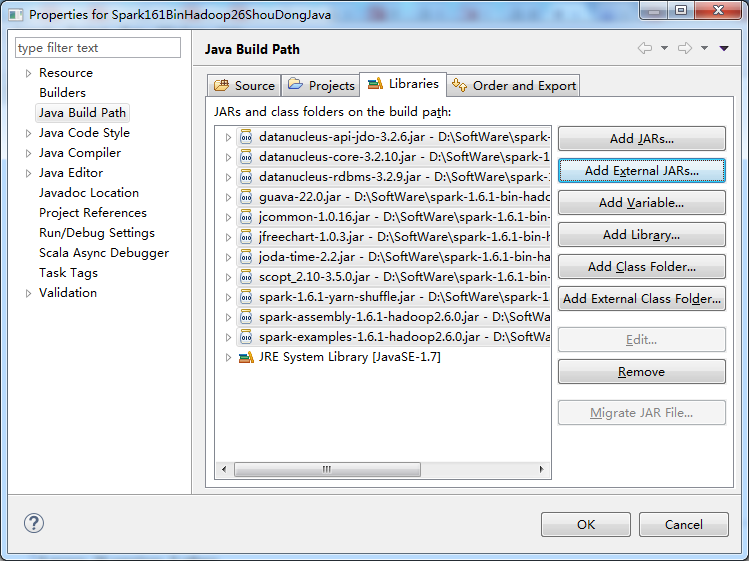
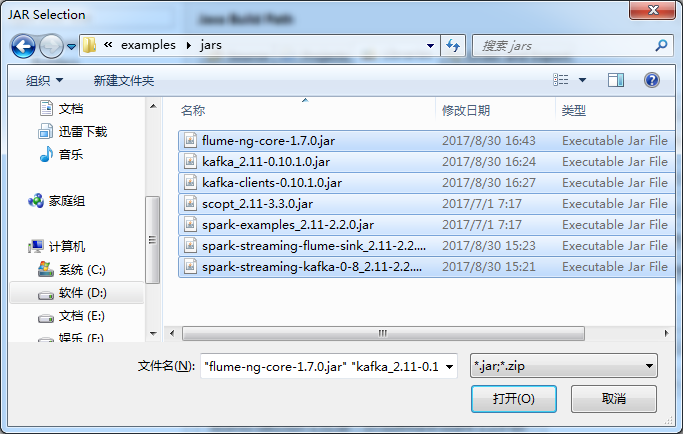
D:\SoftWare\spark-1.6.1-bin-hadoop2.6\lib下的所有
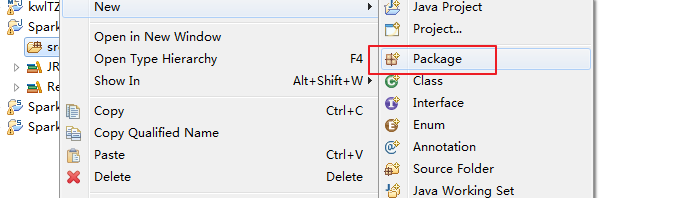
zhouls.bigdata.Basic、zhouls.bigdata.sql、zhouls.bigdata.streaming、zhouls.bigdata.ml、zhouls.bigdata.mllib
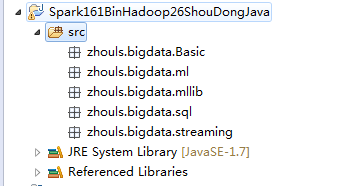
然后,再分别复制进去,不多说。
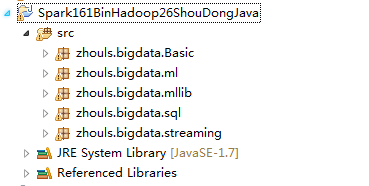
这里,我是在Scala IDEA for Eclipse里,手动来构建java代码环境
D:\SoftWare\spark-2.2.0-bin-hadoop2.6\jars

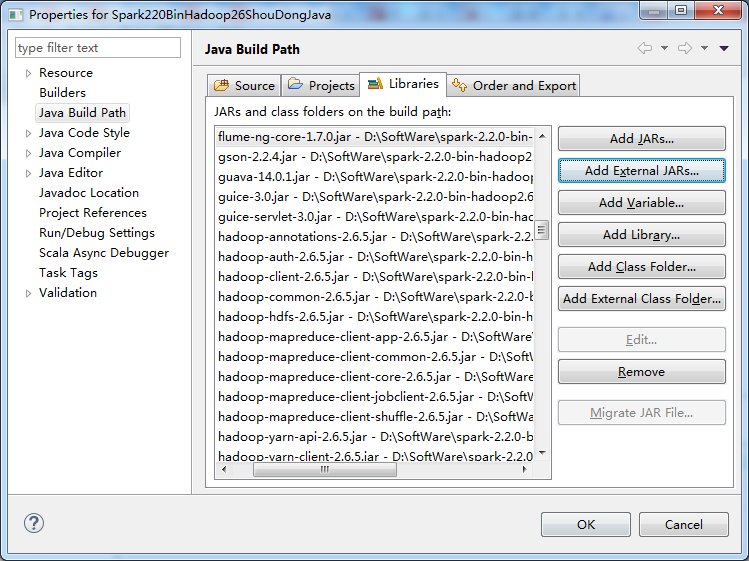

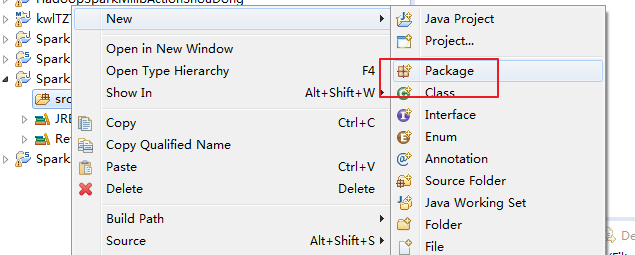
zhouls.bigdata.Basic、zhouls.bigdata.sql、zhouls.bigdata.streaming、zhouls.bigdata.ml、zhouls.bigdata.mllib
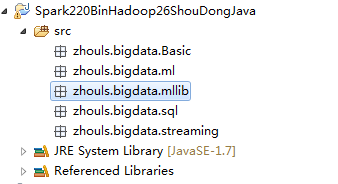

成功!
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

