Apache Kylin Cube 的构建过程
不多说,直接上干货!
1、 Cube的物理模型

如上图所示,一个常用的3维立方体,包含:时间、地点、产品。假如data cell 中存放的是产量,则我们可以根据时间、地点、产品来确定产量,同时也可以根据时间、地点来确定所有产品的总产量等。
Apache Kylin就将所有(时间、地点、产品)的各种组合实现算出来,data cell 中存放度量,其中每一种组合都称为cuboid。估n维的数据最多有2^n个cuboid,不过Kylin通过设定维度的种类,可以减少cuboid的数目。
2 、Cube构建算法介绍
2.1 逐层算法(Layer Cubing)
我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。
比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
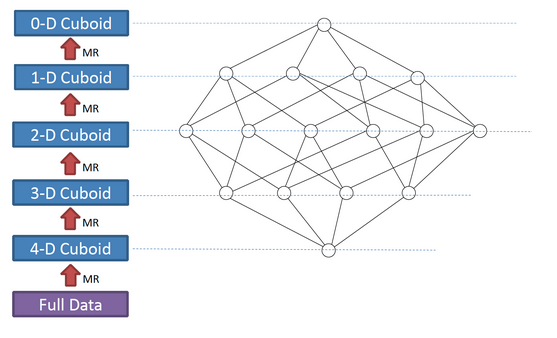
如上图所示,展示了一个4维的Cube构建过程。
此算法的Mapper和Reducer都比较简单。Mapper以上一层Cuboid的结果(Key-Value对)作为输入。由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,并对Value进行操作,然后把新Key和Value输出,进而Hadoop MapReduce对所有新Key进行排序、洗牌(shuffle)、再送到Reducer处;Reducer的输入会是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
每一轮的计算都是一个MapReduce任务,且串行执行; 一个N维的Cube,至少需要N次MapReduce Job。
算法优点
- 此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
- 受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
算法缺点
- 当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
- 由于Mapper不做预聚合,此算法会对Hadoop MapReduce输出较多数据; 虽然已经使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力;
- 对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
- 总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候;时常有用户问,是否能改进Cube算法,缩短时间。
2 .2 快速Cube算法(Fast Cubing)
快速Cube算法(Fast Cubing)是麒麟团队对新算法的一个统称,它还被称作“逐段”(By Segment) 或“逐块”(By Split) 算法。
该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;图2解释了此流程。
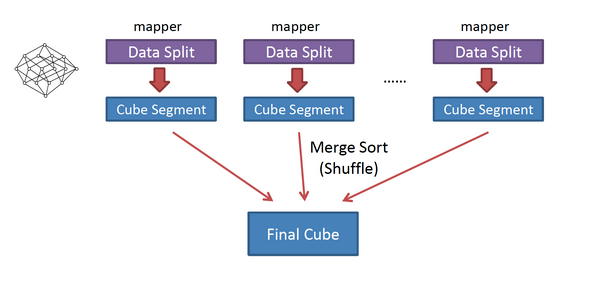
与旧算法相比,快速算法主要有两点不同
- Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
- 一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
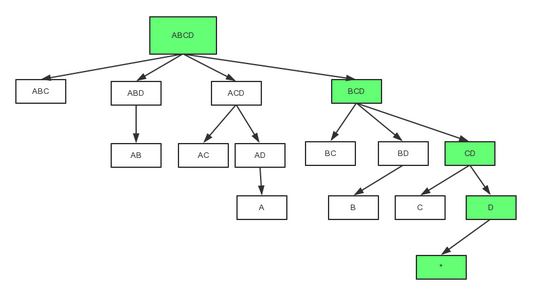
子立方体生成树的遍历
值得一提的还有一个改动,就是子立方体生成树(Cuboid Spanning Tree)的遍历次序;在旧算法中,Kylin按照层级,也就是广度优先遍历(Broad First Search)的次序计算出各个Cuboid;在快速Cube算法中,Mapper会按深度优先遍历(Depth First Search)来计算各个Cuboid。深度优先遍历是一个递归方法,将父Cuboid压栈以计算子Cuboid,直到没有子Cuboid需要计算时才出栈并输出给Hadoop;最多需要暂存N个Cuboid,N是Cube维度数。
采用DFS,是为了兼顾CPU和内存:
- 从父Cuboid计算子Cuboid,避免重复计算;
- 只压栈当前计算的Cuboid的父Cuboid,减少内存占用。
-
-
-
-
-
-
-
-
立方体生成数的遍历过程
-
-
-
-
-
-
-
上图是一个四维Cube的完整生成树;按照DFS的次序,在0维Cuboid 输出前的计算次序是 ABCD -> BCD -> CD -> D -> , ABCD, BCD, CD和D需要被暂存;在被输出后,D可被输出,内存得到释放;在C被计算并输出后,CD就可以被输出; ABCD最后被输出。
4.3 、Cube构建流程

主要步骤如下:
- 构建一个中间平表(Hive Table):将Model中的fact表和look up表构建成一个大的Flat Hive Table。
- 重新分配Flat Hive Tables。
- 从事实表中抽取维度的Distinct值。
- 对所有维度表进行压缩编码,生成维度字典。
- 计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid。
- 创建HTable。
- 构建最基础的Cuboid数据。
- 利用算法构建N维到0维的Cuboid数据。
- 构建Cube。
- 将Cuboid数据转换成HFile。
- 将HFile直接加载到HBase Table中。
- 更新Cube信息。
- 清理Hive。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号