

Flume启动运行时报错org.apache.flume.ChannelFullException: Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight解决办法(图文详解)
前期博客
Flume自定义拦截器(Interceptors)或自带拦截器时的一些经验技巧总结(图文详解)
问题详情
启动agent服务
[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_MySearchAndReplaceInterceptor/ --conf-file conf_MySearchAndReplaceInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console

我这里,出现了这个错误
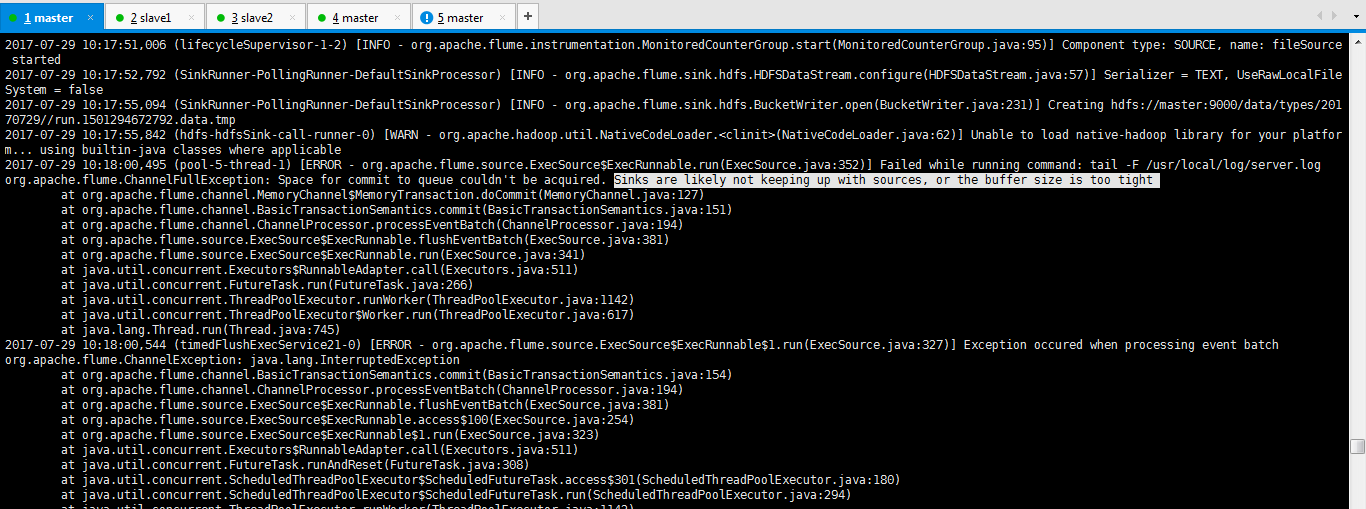


2017-07-29 10:17:51,006 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: fileSource started
2017-07-29 10:17:52,792 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false
2017-07-29 10:17:55,094 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170729//run.1501294672792.data.tmp
2017-07-29 10:17:55,842 (hdfs-hdfsSink-call-runner-0) [WARN - org.apache.hadoop.util.NativeCodeLoader.<clinit>(NativeCodeLoader.java:62)] Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-07-29 10:18:00,495 (pool-5-thread-1) [ERROR - org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:352)] Failed while running command: tail -F /usr/local/log/server.log
org.apache.flume.ChannelFullException: Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight
at org.apache.flume.channel.MemoryChannel$MemoryTransaction.doCommit(MemoryChannel.java:127)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194)
at org.apache.flume.source.ExecSource$ExecRunnable.flushEventBatch(ExecSource.java:381)
at org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:341)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
2017-07-29 10:18:00,544 (timedFlushExecService21-0) [ERROR - org.apache.flume.source.ExecSource$ExecRunnable$1.run(ExecSource.java:327)] Exception occured when processing event batch
org.apache.flume.ChannelException: java.lang.InterruptedException
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:154)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194)
at org.apache.flume.source.ExecSource$ExecRunnable.flushEventBatch(ExecSource.java:381)
at org.apache.flume.source.ExecSource$ExecRunnable.access$100(ExecSource.java:254)
at org.apache.flume.source.ExecSource$ExecRunnable$1.run(ExecSource.java:323)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
解决办法

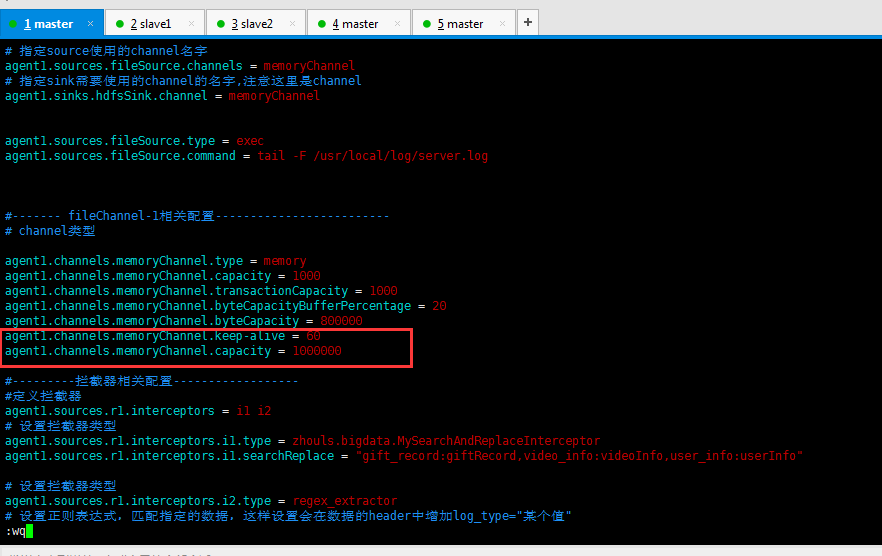
agent1.channels.memoryChannel.keep-alive = 60 agent1.channels.memoryChannel.capacity = 1000000
然后,再来修改
修改java最大内存大小
vi bin/flume-ng
JAVA_OPTS="-Xmx1024m"
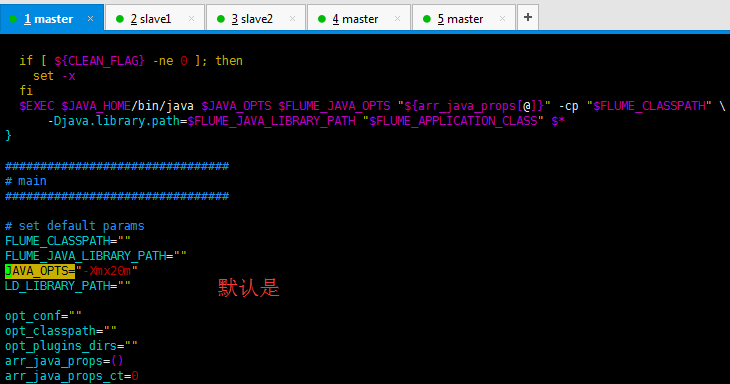
改为

即,修改后之后,再次运行
[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_MySearchAndReplaceInterceptor/ --conf-file conf_MySearchAndReplaceInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
上述错误,得以解决了。
参考博客
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
分类:
Hadoop Flume集群搭建

« 上一篇: 基于Web的Kafka管理器工具之Kafka-manager启动时出现Exception in thread "main" java.lang.UnsupportedClassVersionError错误解决办法(图文详解)
» 下一篇: Flume启动时报错Caused by: java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long.解决办法(图文详解)
» 下一篇: Flume启动时报错Caused by: java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long.解决办法(图文详解)

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!